DropBox:机器学习每年可以为我们节省170万的文档预览费用
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DropBox:机器学习每年可以为我们节省170万的文档预览费用相关的知识,希望对你有一定的参考价值。
【CSDN 编者按】Dropbox 借助机器学习的预测功能,每年能为公司节省了一百多七十多万美元的基础架构成本。非常了不起的成就。本文,一起来看一看 Dropbox 采用机器学习的经过,以及分析一下其中的利弊。
最近,Dropbox 优化了生成和缓存文档预览的方式,并借助机器学习的预测能力,每年为公司节省了 170 万美元的基础架构成本。Dropbox 的一些常用功能都采用了机器学习,例如搜索、文件与文件夹提示以及文档扫描 OCR。虽然用户看不到 Dropbox 采用的机器学习,但这些应用程序仍以其他方式推动了业务的发展。
在本文中,我们就来看一看 Dropbox 采用机器学习的经过,以及其中的利弊。

预览功能
用户可以利用 Dropbox 的预览功能直接查看文件,而无需下载内容。除了常见的缩略图预览之外,Dropbox 还提供交互式预览界面,可供用户共享文件和共同编辑文件,包括添加批注和标记其他用户。
我们的内部系统 Riviera 负责安全地生成文件预览,它可以处理数百种支持的文件类型的预览。它可以将各种内容转换操作链接在一起,创建适合特定文件类型的预览。例如,Riviera 可以将 PDF 文档的某一页栅格化,在 Dropbox 的 Web 界面中显示高分辨率的预览。完整内容的预览功能支持批注和共享之类的交互。大型图片可以转换成缩略图,以供在各种情况中显示给用户,包括搜索结果或文件浏览器。
在 Dropbox 的规模下,Riviera 每天需要处理数十 PB 的数据。为了加快某些类别的大型文件的预览,Riviera 会提前生成预览,并缓存预览结果(此过程称为预热)。由于我们支持的文件量非常巨大,因此预热消耗的 CPU 与存储也非常可观。
我们看到采用机器学习可以降低这些成本,因为有些预生成的内容从不会有人查看。如果我们可以有效地预测某个预览是否会被使用,则只需预热我们确信一定会被查看的文件,从而节省计算和存储空间。我们的这个项目名叫 Cannes(戛纳),这个名字的灵感来自法国戛纳电影节。

机器学习的利弊权衡
在预览的优化过程中,机器学习的两项折衷决定了我们的指导原则。
第一个挑战是权衡机器学习为基础设施带来的成本效益。减少预热的文件可以节省成本,无人不喜欢,但也有可能漏掉一些文件,造成不良的用户体验。如果缓存中没有相应的文件预览,则 Riviera 需要动态地生成预览,而在这期间用户只能等待。我们与预览团队合作开发出了一种预防措施,防止用户体验降级,并通过这种预防措施来调整模型,以合理的方式节省费用。
另一个需要权衡的是复杂性和模型的性能 vs. 可解释性和部署的成本。通常,你需要权衡机器学习的复杂性与可解释性:通常模型越复杂,预测就越准确,但代价是可解释性会降低,你很难解释为何得出了这样的预测,而且部署的复杂性可能也会增加。在第一次迭代中,我们的目标是尽快提供可解释的机器学习解决方案。
由于 Cannes 是在现有系统内新构建的机器学习应用程序,因此我们偏向于使用一种比较简单且可以解释的模型,这样我们就可以在研究更复杂的模型之前,集中精力建立模型、指标以及报告。如果出现问题,或 Riviera 出现意外行为,机器学习团队也能够进行调试,并了解是 Cannes 的原因还是其他问题。我们的解决方案必须相对简单且成本低廉,因为我们每天都需要部署将近 5 亿个请求。目前的系统只能预热所有的可预览文件,因此任何改进都可以节省成本,而且越快越好!

Cannes v1
考虑到这些权衡之后,我们选择了一个简单、易于训练且易于解释的模型。第一版的模型是一个梯度提升分类器,训练时采用了文件扩展名、存储了文件的 Dropbox 账号类型,以及该账号最近 30 天的活动等作为输入特征。在离线预留数据上训练时,我们发现该模型经过预热后,预测的预览准确率可以在最多 60 天内超过 70%。该模型拒绝了预留数据中大约 40%的预热请求,并且性能在我们为自己设定的预防指标以内。假阴性的数量很少,假阴性指的是我们预测不会被查看、但最终在接下来的 60 天内被查看的文件,一旦出现这种情况,我们就需要动态生成预览。我们估算了一下成本:“拒绝百分比”- 假阴性,结果发现每年可以节省 170 万美元。
在探索预览优化之前,我们想确保节省的成本能够超过构建机器学习解决方案的成本。我们大致估算了一下 Cannes 项目可以节省的成本。在大型分布式系统中设计和部署机器学习系统,你需要考虑系统的变化随着时间的推移对你的估计产生的影响。我们希望初始的模型尽量简单,这样一来即使相邻系统发生一些很小的变化,成本的影响也不会出现数量级的变化。通过分析训练好的模型,可以让我们更好地了解第一版实际可以节省的成本,并确认这项投资是值得的。
我们利用内部的功能开关服务 Stormcrow,在 Dropbox 流量 1%的随机样本上,针对模型进行了 A / B 测试。我们验证了模型的准确率和预热“节省”的成本符合我们离线分析的结果,这是个好消息!由于 Cannes v1 不再预热所有符合条件的文件,因此我们知道预计缓存命中率会下降。在实验期间,我们观察到缓存命中率比 A / B 测试中的对照组低了几个百分点。尽管百分比下降了,但总体的预览延迟基本上保持不变。
我们非常关心尾延迟(第 90 个百分位数以上的请求延迟),因为缓存未命中会导致尾延迟过高,进而严重地影响用户的预览功能。然而,我们并没有观察到预览尾延迟或总体延迟明显上升,这很让人欣慰。这次实时测试让我们信心大增,我们决定将 v1 模型部署到更多 Dropbox 流量。

大规模的实时预测
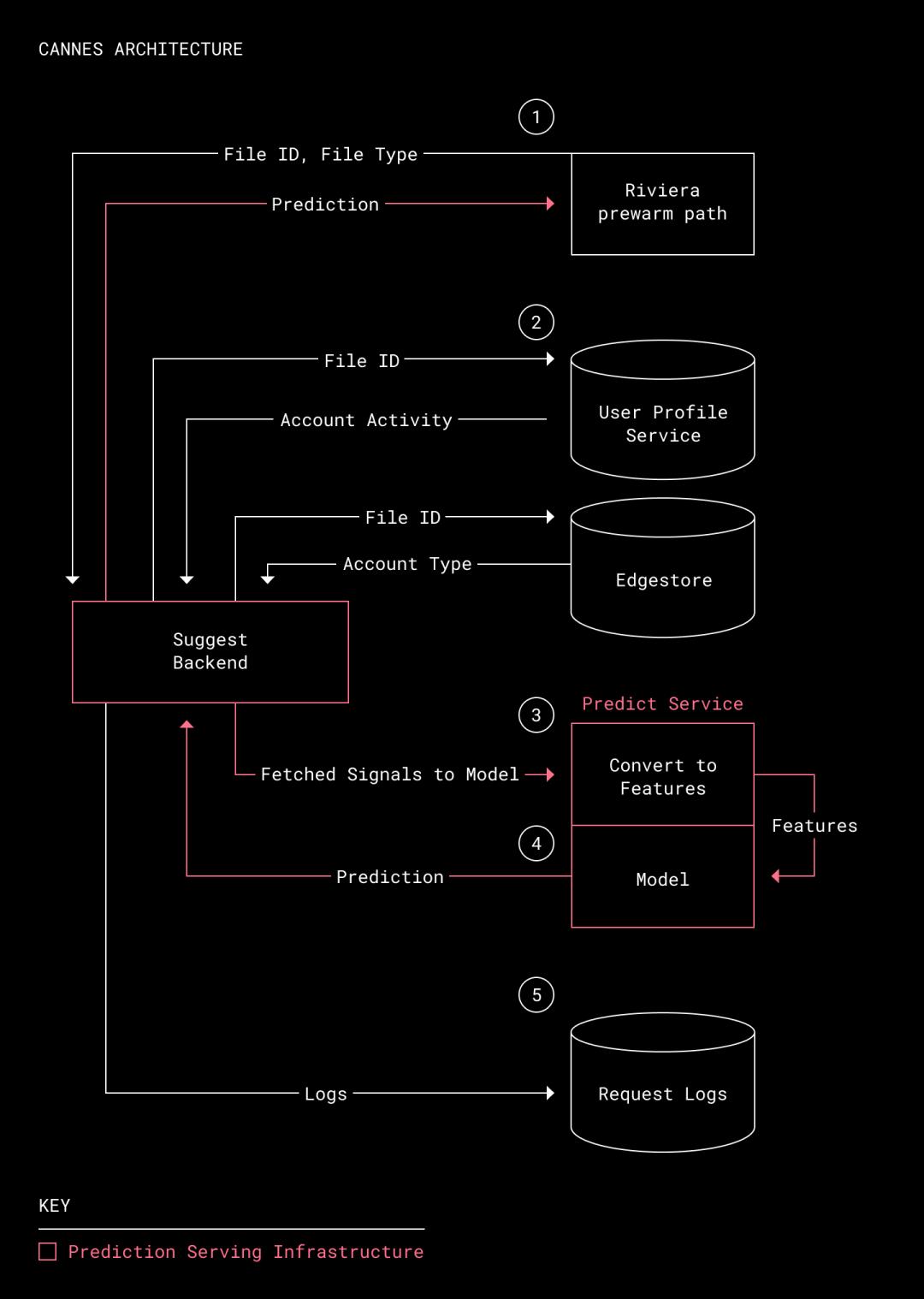
我们需要一种方法,当某个文件进入预热路径时,实时地告诉Riviera该文件是否需要预热。为了解决这个问题,我们将 Cannes 构建成了预测流水线,负责提取与文件相关的信号,并将其发送给模型,供模型预测未来使用预览的可能性。
-
从Rivieraprewarm path(预热路径)接收文件 ID。Riviera 会收集所有可进行预热的文件 ID。(Riviera可以预览 Dropbox 存储的大约 98%的文件。只有很少一部分文件的文件类型不支持,或无法预览。)Riviera 发送一条预测请求,其中包含需要预测文件 ID 以及文件类型。
-
获取实时信号。为了收集预测期间文件的最新活动信号,我们使用了一个名为“Suggest Backend”(建议后台)的内部服务。该服务会验证预测请求,然后查询与该文件相关的信号。信号存储在 Edgestore(Dropbox 主要的元数据存储系统)或 User Profile Service(RocksDB 数据存储,负责聚合Dropbox 活动信号)中。
-
将信号编码为特征向量。收集到的信号会被发送到 Predict Service(预测服务),由该服务将信号编码为表示文件所有相关信息的特征向量,然后将这个向量发送给模型进行评估。
-
生成预测。模型使用特征向量,返回该文件可能会被预览的概率。接着,这个预测结果会被发送回 Riviera,并由 Riviera 预热未来 60 天内可能会被预览的文件。
-
记录请求的相关信息。SuggestBackend(建议后台)会记录下特征向量、预测结果和请求状态,这些都是调查性能下降和延迟问题的关键信息。
其他考虑事项
减少预测延迟很重要,因为上述管道位于 Riviera 预热功能的关键路径上。例如,当将这个模型扩展到 25%的流量时,我们观察到了一些极端的情况,导致建议后台的可用性降低到了内部 SLA 以下。
经过分析后,我们发现上述第 3 步出现了超时的问题。因此,我们改进了特征编码处理,并优化了预测路径上的几个问题,降低了这些极端情况下的尾延迟。

优化机器学习
在推出机器学习模型的过程期间(及其之后),我们非常注重稳定性,并确保不会对预览界面的用户体验产生负面影响。多个层面的监视和警报是部署机器学习的关键组成部分。
Cannesv1 的指标
预测服务基础设施的指标:共享系统有自己内部的 SLA,主要都是围绕正常运行时间和可用性。我们依靠 Grafana 等现成的工具进行实时监控和发送警报。我们监控的指标包括:
预览指标:我们有一些预览性能方面的关键指标,即预览延迟分布。我们保留了3%的存档数据,用于比较使用 Cannes 与不使用 Cannes 两种情况下的预览指标,以防止模型漂移或可能会降低模型性能的系统变化。Grafana 是一款应用程序级指标的通用解决方案。主要指标包括:
-
预览延迟分布(使用 Cannes 与不使用 Cannes),需要特别注意第 90 个百分比以上的延迟。
-
缓存命中率(使用 Cannes 与不使用 Cannes):缓存命中总数/预览内容的总请求数量。
模型性能指标:我们为机器学习团队使用的 Cannes v1 的模型建立了指标,并建立了自己的流水线来计算这些指标。我们关心的指标包括:
-
-
ROC 曲线下的面积:虽然我们直接监视了混淆矩阵的统计信息,但我们也希望计算 AUROC,以便将来比较模型的性能。
上述模型性能指标每小时计算一次,并存储在 Hive 中。我们使用 Superset 来可视化重要的指标,并创建了一个 Cannes 的实时变化仪表板。Superset 是在各项指标的基础之上构建的,如果底层模型行为发生变化,它会赶在客户受到影响之前主动通知我们。
然而,仅凭监视和警报不足以确保系统健康,明确责任并建立上报问题的流程也是必要的。例如,我们记录了机器学习系统的上游依赖项,因为它们可能影响到模型的结果。此外,我们还创建了一个手册,详细介绍了解决问题的步骤,帮助值班的工程师判断问题来自 Cannes 内部还是其他的其他部分,并提供了在根本原因是机器学习模型的情况下,上报问题的流程。机器学习团队与非机器学习团队之间的紧密合作有助于确保 Cannes 的平稳运行。

目前的状况与未来的探索
目前 Cannes 已部署到几乎所有的 Dropbox 流量中了。结果,我们每年 170 万美元的预热成本变成了如今每年 9,000 美元的机器学习基础设施(主要用于建议后台和预测服务的流量增加)。
对于该项目的下一个迭代,我们有许多期待的探索方面。如今 Cannes 已投入生产,我们可以尝试更为复杂的模型类型。我们还可以根据更详细的内部费用和使用情况数据,为模型开发更细致的成本函数。
我们还讨论过新建一个预览应用程序,通过机器学习更细致地控制预测决策,而不是针对每个文件进行预热/不预热的二元分类。我们可以通过具有预见性的预热来发挥更大的创造力,降低成本,同时又不会破坏用户的文件预览体验。
我们希望将 Cannes 项目积累的经验和工具推广到 Dropbox 的其他基础设施。利用机器学习优化基础设施是一个振奋人心的投资领域。
参考链接:https://dropbox.tech/machine-learning/cannes--how-ml-saves-us--1-7m-a-year-on-document-previews


“面向对象就是一个错误!”
以上是关于DropBox:机器学习每年可以为我们节省170万的文档预览费用的主要内容,如果未能解决你的问题,请参考以下文章
基于阿里云GPU云服务器的AIACC助力UC搜索业务性能提效380%,每年节省数千万成本
图,图谱,图信号处理,图机器学习新书,170页pdf阐述从图分析到图神经网络应用
混合多云第二课——混合技术如何每年为京东节省上亿元成本?
学习笔记TF059:自然语言处理智能聊天机器人
机器学习框架之sklearn简介
人工智能人才需求翻番,算法人才缺口达170万