混合多云第二课——混合技术如何每年为京东节省上亿元成本?
Posted Jcloud
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了混合多云第二课——混合技术如何每年为京东节省上亿元成本?相关的知识,希望对你有一定的参考价值。
大家好,我叫侯竹玲,欢迎大家收看我在京东做研发。接下来我来介绍混合多云第二课 全场景混布。

为什么要介绍混部?因为现在除了互联网企业以外,各大国央企、金融企业都在探索全量业务容器化,那么容器化之后又希望不同的特征业务的工作负载,能够进行不同的调度,充分利用负载之间消峰填谷的这种效应,让工作负载可以更稳定、更高效、更低成本去使用资源,就是业界我们常提到的“混部”。
京东是在2014年就开始探索容器化,17年的时候开始探索混部,经过我们多轮的架构的升级,延伸到了现在的这种混部架构,实现了全场景的混部,混部资源 CPU使用率常态化的保证在了80%左右,帮助京东节省了大量的资源成本。
京东混部其实它是在京东内部超大规模混部生产实践经验而来,旨在为用户打造云原生场景下,全场景混部的一套解决方案,可以真正的帮助企业做到降本增效,实现云原生后时代持续的红利释放。
2022年的春晚红包,其实我们在12月28号才开始启动项目会,1月6号的时候真正的做系统的改造,1月31号春晚就要播出。
那么在20多天的时间下,我们业务在没有增加任何的线上资源的前提下,利用混部技术对离线资源做压制,保证了在线业务资源的充足使用,助力春晚红包顺利进行。
接下来我们进入正题,下面我会从三个方面来介绍混部。
第一混部整体的介绍和在京东的历程。第二混部的架构和功能。第三各模块的混布的技术。
1.混部的价值是什么?在京东有哪些重要的应用历程? 好,我们进入第一块,第一个模块主要是混部的介绍和历程,我们来介绍一下什么是混部。
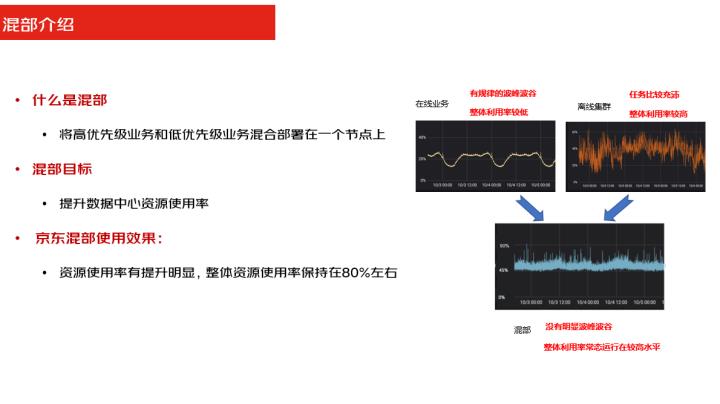
混部其实用一句话说,就是将高优先级的业务和低优先级的业务混合部署在一个节点上。那么从业务场景上来说,混部其实是通过在线作业运行的过程当中,把离线的任务填充进来,充分的利用负载之间的削峰填谷的效应来提高资源的利用率。
从右面这张图我们可以看一下上面的两张图,第一张图是在线业务资源使用情况,第二张图是离线业务的使用情况。
在线业务使用情况我们看到它这种资源利用率都比较低,但是会存在波峰波谷比较明显。
而离线业务这张图资源利用率比较高,但是它的业务比较密集,所以我们在整合了混部之后,下面这张图可以看到它整体的利用资源利用率平均保持在了80%左右,并且不会存在这种很频繁的波峰波谷的效应。
在线业务运行的过程当中,离线业务不影响在线业务的使用
保证了资源利用率的提升,这就是混部,那么整体京东混部使用的效果,其实刚才已经讲过了,整体我们利用对资源的使用率有了明显的提升,并且整体的资源使用率保持在了80%左右。
我们接下来看一下京东混部的发展历程。
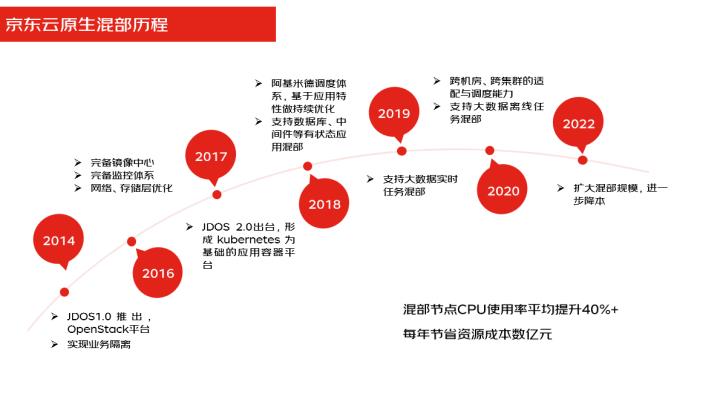
京东在2014年的时候就推出了jdos1.0的容器平台,然后在2017年的时候我们就推出2.0,也就是基于kubernetes的应用容器平台,在2018年的时候在云原生的基础上做了调度的增强,增加了阿基米德的调度,支持了数据库中间件等有状态应用的混部。
在2019年的时候又支持了大数据实时数据的混部,在20年的时候做了扩展,支持了大数据离线任务的混部,在2022年的时候扩大了混布的规模,进一步做了降本。
整个的在混布的过程中,资源利用率不断提升,现在的混部节点的CPU的使用率平均已经提升了40%以上,每年为京东节省的资源成本达到数亿元。
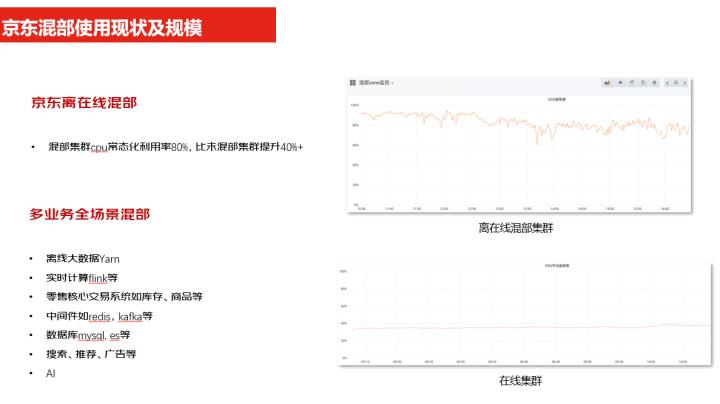
可以看到这张图是现在京东混部的使用的现状和规模,我们刚才讲了整个资源的利用率已经常态化的资源,这是我们线上一张截图,可以看到,CPU的使用率平均常态保持在了80%,比未做混部的集群资源利用率提升了40%以上,整个业务已经做到了全场景的混部,有离线的大数据、实时的计算,以及零售的一些核心业务中间件、数据库,还有广告搜索以及AI等各种场景的应用,都可以做到同步混部的效果。
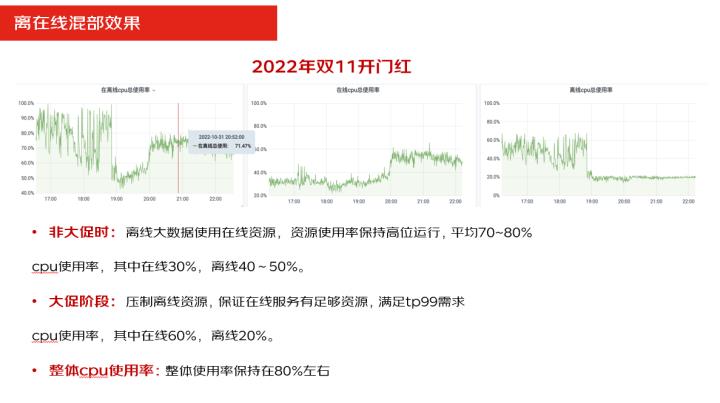
可以看到这是一张2022年双11开门红的一张图,我们可以看到整体的资源利用率都在80%左右,但是在大促和非大促的时候,离线和在线的使用的资源的情况一有一些变化,可以看到第一张图是整体的资源,第二张图是在线资源,第三张图是离线的资源。
那么在非大促的时候,离线的整体资源的使用率是比较高的,达60%左右,在线的资源使用率是在40%到50%之间。那么在大促的时候,也就是我们在8点开始做大促,在7点的时候我们把离线业务做了压制,到8点的时候,就看到在线的资源的使用率已经上升达到了60%左右,而离线的资源使用率降到了20%左右。那么在整体资源保持稳定的情况下,离在线资源做了一个调整,就是我们在不增加任何资源的情况下,保证了在线业务的正常的运行。
好,我们来介绍一下京东全场景混部的价值。
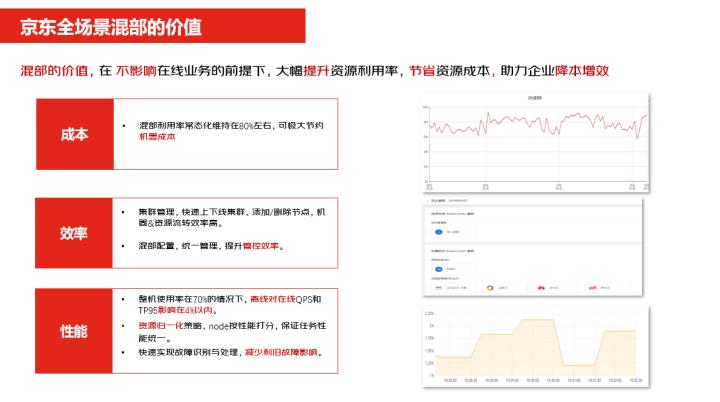
其实混部的价值用一句话说就是在不影响在线业务的前提下,大幅提升资源的利用率,节省资源的成本,助力企业降本增效。
其实大部分企业它的离线的机房和在线的机房是完全隔离的,在这种情况下就会造成资源的浪费,我们可以将这些资源做规划,做统一的调度利用削峰填谷的效应来提高资源的利用率。下面我们重点从成本、效率和性能三个方面来介绍一下混部。
成本的话,刚刚提到的我们可以将离线资源和在线资源给它进行统一归一化之后,统一做调度,整体可以将常态化资源利用率保持在80%左右,极大的节约机器的成本。效率的话,整个集群的管理也好,我们可做了快速的上下线,并且对于添加删除节点这个机器的一些流转,都进行了整个的平台化的效率提升。再一个混部配置有了统一的管理,提升了管控的效率。
性能方面,我们看到在整机使用率在70%的情况下,离线对在线的QPS和TP95的影响,我们控制在了4%以内。做了资源的归一化策略之后,会根据每个节点的性能来给它去做打分,保证任务的一个调度的统一。我们在做平衡调度的时候,会根据不同节点的打分来做统一的调度。
第三个就是说如果我们在调度的过程当中,我们可以快速的识别出故障并且去做处理,这样减少了一些利旧设备对业务的影响。
下面我们来看一下,那么刚刚上面我们讲到了混部它是通过在线作业在运行过程当中来填充离线的作业,那么我们既要保证在线任务正常运行,又要提升资源的利用率,那么这个就给混部其实带来了一定的挑战和难点。
挑战和难点会在哪几个方面?

离线任务在填充过程中不能无限的填充,需要保证在线作业不受影响,那就要保证SLO在可接受的范围内,同时离线作业,要快速的支持切换上下线那么当我在线业务需要的时候,你能快速的让出资源,我不需要的时候,你又能够快速的去使用这些已有的资源。当然了,离线运行起来之后,还得保证离线作业的一个成功率,不能因为资源让出来而导致了它的失败。
所以我们要在保证这些前提下,对我们混部的挑战有以下几点,第一点就是说我们如何去减少低级别的应用,对高级别应用的干扰呢?在保证它的SLO的前提下,怎么样去更多的去使用资源。第二点就是说如何满足高低级别应用的调度的需求,在整体上去做质量的把控,我既要保证高级别应用的所需要的资源的需求,并且我还不能够让低级别的应用它的作业的失败,所以这个就是要从全局上去做统一的调度。
第三点怎么样去避免高级别的应用和低级别的应用,不被同时调度在一个核上,发生抢占时间的执行。别因为低级别的应用调度,在同一个节点上造成了高级别应用不能够去使用当前的一个资源。第四个内存的资源是有限的,那么我们如何去做合理的分配?避免高级别和低级别应用发生对存储内存资源的相互争抢。
第五个,高级别应用和低级别应用,它在运行的过程当中都会跟网络是密切相关的,那么网络它要如何去做隔离,再最后一个就是说高级别应用和低级别应用,它在对 io的使用过程中也会发生抢占,那么如何制定有效的io的隔离策略呢?以上的这些问题和挑战,我们在下面的介绍当中会一一去做一些解答。
2.混部的主要架构和重要功能有哪些?
接下来我们介绍一下混部的架构和相关的技术。

可以看到这是整个混部架构的全景图。架构的核心分了几大块,第一块就是资源的隔离,如果我要保证离线的任务,对在线业务的干扰最少,我就要去做到各种维度的隔离,有CPU、内存、磁盘,各种维度都要做这种隔离的控制。
第二个如果我要保证整个的集群的资源的调度要做到均衡,所以我们要去做调度,调度的时候要去做负载感知的调度,做调度任务的压制驱逐,过载保护等一系列保证资源的均衡的运行。
第三块就是我们的可观测性,不管隔离也好,调度也好,我可以实时的观测到各种维度的资源的监控,比如集群资源监控,节点的负载的调度的以及干扰的各种数据都可以通过大盘去看到。
再一个就是故障的探测与恢复,可以做软件层面故障的探测,硬件的故障探测,以及故障之后的故障的隔离自愈都可以在我们整个混部里头去做,自己去做闭环完成。再往上就是我们的业务,不管这是在线业务还是离线的数据以及数据库中间件和AI,支持多场景的这样的一个混部,这就是混部的整个架构图,那么接下来我会分在每个层面详细的介绍一下这几块的能力。
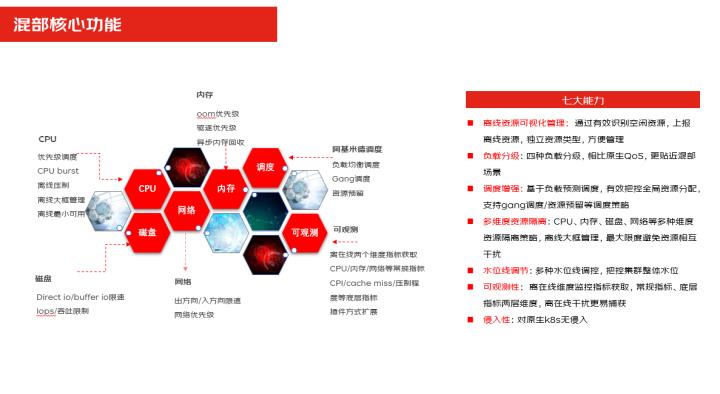
第一个我们可以看到这几块是沉淀出了核心的能力,有第一个就是我们刚才提到调度,调度这个就是有阿基米德调度,它有负载均衡干调度,然后这一块是隔离,有CPU隔离、磁盘隔离、内存隔离这一大块是隔离的内容,再一块就是可观测性,我们可以提到了不管是底层指标还是上层业务指标,它可以通过多维度去做这样的一个监控。
呈现出来的7大能力,第一块就是我们的离线资源的可视化,我可以识别出有哪些空闲的资源去做上报,我可以整体去控制有哪些离线资源。负载的分级,、通过负载分了4级,对相比原生的Qos的3级来说,它更贴近了混部,业务在做调度和驱逐,或者是在隔离的时候都会用到负载的应用的分级。
调度的增强就是说基于负载预测的调度,可以有效的把全局资源分配支持这种gang调度,就批量的调度一些资源的预留等这样的一些策略。接下来还有一个功能就是我们刚才提到隔离,那都是支持CPU内存、磁盘网络等多维度的一些隔离,还有我们的一个离线大框策略,那就是可以最大限度的避免了资源的相互干扰。
水位线的调节,我们可以支持有调度水位线隔离水位线,可以通过水位线的配置去做调控,把控集群的一个整体的水位,可观测性就是可以支持多维度的一个监控指标以及的一个查看。
在你的离线有干扰的时候,我们可以第一时间捕捉到这样的一些信息。最后一个就是侵入性,我们这个混部它是一个插件,它对原生k8s是无侵入的。
3.混部包含哪些关键的技术?
接下来我们来介绍一下混部技术。

首先可以看一下应用QoS的分级,分了4级,级别整体上分了两个维度,第一个维度是延迟敏感型的在线业务的,第二个维度是资源消耗性的离线业务。4个级别前三个级别是给分给了在线业务,最后一个级别是分给了离线业务。为什么要去做分级?它的目的就是说在单机资源紧张的时候,我们会根据优先级来去做资源的调度,会保证在线资源的应用可以优先获得资源。
第二块是我们的负载均衡的容器的调度.
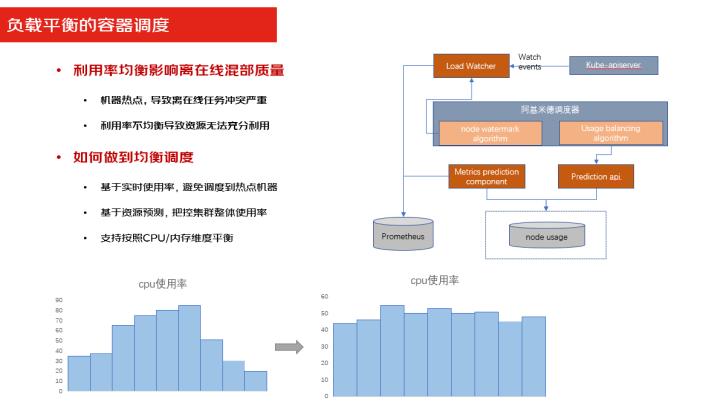
负载均衡刚才提到了我要保证整体的资源保证在80%左右上去运行,我就得做负载均衡的整体的调度,为什么要去做均衡的调度?因为如果你的利用率不均衡的时候,会导致资源的无法正常的充分的利用。
第二个如果是把你的业务调度在热点机器上的话,会导致离线业务和在线业务的严重冲突,所以我们要去做平衡调度,那么做平衡调度是怎么样去做的呢?
首先我们会通过监控系统,实时上报资源的使用率,通过资源使用率,去把业务分配到不同的节点上去,避免分配到热点机器上。
第二个基于资源的一个预测,我们会能够预测到你的业务会使用多少资源,那么根据这个资源来做整体整个节点资源的一个把控。
第三个我们会支持 Cpu和内存维度的整体资源利用率的控制均衡的调度.

我们来看一下Gang调度,Gang调度也是资源平衡调度的一个最核心的能力,它就是主要解决了是什么?我们原生的是我们会进行一个去做调度,Gang调度解决的就是批量调度,我可以等着一次性把所有的应用所有的资源都分配好了之后一次性调度完成,那避免了有的任务。

在轮巡的过程当中,当一部分业务任务完成,另外一部分任务没完成的时候,它会等待,造成了资源使用的一个浪费。资源预留就是我们在大促也好,或者是在有些核心业务的时候,有这种资源预留的诉求,就是说我有些特定的业务一定要调度到某些特定的资源上去,比如ES他要调度到大磁盘的node上去,这个时候我们就用了资源预留,我可以把某些资源特定给到某种业务这样调度上来的时候,我就直接可以把相关的业务调度到特定的资源上去。
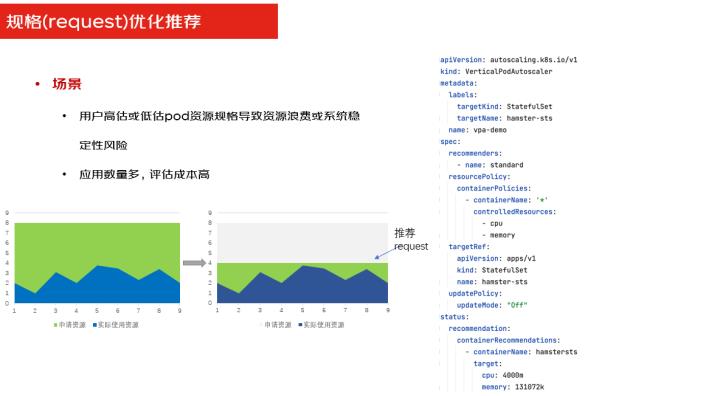
Request优化推荐,就是我们可以能做到根据真正的资源使用情况,去智能的推荐你的Request,因为往往业务在自己申请 Request资源的时候,为了避免有这种高流量突发的情况,会多去申请一些资源出来,真正使用的时候,其实它使用不了这么多量,会造成一个资源的浪费。
所以针对这种场景,又做了一个优化,我会根据真正的业务的使用资源,再加上你业务未来的预测会用到多少资源,两者整体做评估之后,给出一个 request的值的推荐。这个值既能保证你业务的正常运行,也能够去减少资源的浪费,可以进一步做到资源的使用的优化,降低成本。
资源超卖也是调度里头的核心能力。

我们可以根据在线业务的情况,通过下面一个公式,实时的计算出在线的实际的使用量,然后去评估出离线资源可用的资源有多少,上报给上层的管理端,让他知道当前离线资源可以有多少资源,根据这个资源再调度水为线,然后再去调度离线资源,看可以有多少的离线业务被调度上来。

当然离线可用资源,比如说我可以根据调度水为线,离线的任务调度到哪个节点上,所以这些都是会有一些参数去做设置的。
设置完了之后我们再计算通过计算的能力去算出哪些资源,离线的任务可以被调上来,哪些不可以被调上来。驱逐和调度是混部里头的核心的能力,那么就是说如果我的离线业务已经被调上来了,当在线的资源使用率达到了一定的高度的时候,怎么办?就需要去做驱逐,比如下面的驱逐,比如说内存达到一定的高度的时候,我就要把离线的资源给它驱逐掉,保证在线的资源的正常的使用。
当然调度的水位线也是为了保证资源的管控,不可能把所有离线任都给往上调度,会有一定的调度水位线的控制,但高于调水位线的时候,离线的任务是没办法再调度到这个点节点上来的。
我们来介绍一下隔离能力。
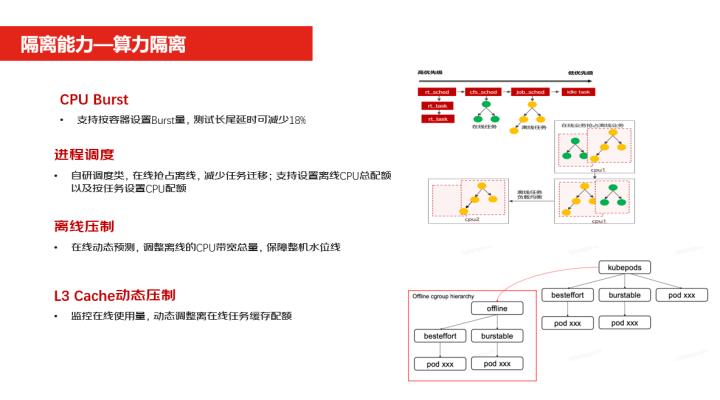
首先看一下算力隔离,算力隔离第一项就是CPU Burst,CPU Burst就是我们可以把设置CPU Burst的量,当你不用的时候把空闲的时间可以折算成你的一个使用量的buffer,当你未来有峰值的时候,可以有一定量的buffer去做使用。
第二块就是进程的调度,进程调度是我们自研的调度类,在原生的基础上做了改造的,改造之后能做到在线立即抢占离线,就是当在线的进程来了之后,当资源不够的时候,可以立即把这个离线的进程给抢占掉。第三个就是离线压制,我们可以在通过动态的预测调整离线的一个CPU的带宽的使用量。
第四个是L3 Cache,Cache也是可以做到动态的压制,通过监控的指标来监控它的使用量,动态的调整离线任务的缓冲的一个配置。当设置好了一定比例之后,当在线的Cache使用的多的时候,会把离线的Cache压制掉,去给在线使用。内存cache就是在做内存方面的一些隔离,第一块异步内存的回收,也就是当容器内存用量超过水位线的时候,它就会启动异步回收,会减少内存配置延时。
第二块就是快速内存回收。

当一项任务销毁的时候,马上就做回收。第三个就是 GroupOOM也就是在一个容器上,把进程杀掉的时候,他可以一并把所有的进程杀掉,减少无效的占用。第四个就是内存水位线的保护,就是可以优先回收离线的业务,保证在线的业务的内存不被回收。Mba的动态压制也是通过监控在线的一个使用量动态的调整,离线任务在内存的带宽上的一个配额,也是为了优先保证在线业务。
最后一个是oom的优先级。在oom的时候就会根据优先级去执行,可以先优先杀掉离线任务,保证在线业务的正常的使用。
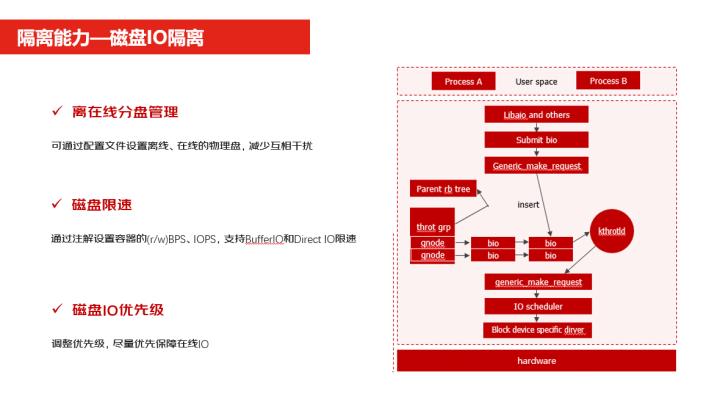
磁盘IO的隔离分三块,第一块就是我们支持了离线在线分盘管理,就说离线在线的可以分别使用不同的盘,这样可以避免了相互的干扰。
第二个磁盘的限速,你可以去配置一些磁盘的一些吞吐和IOPS的使用。第三个就是磁盘IO的优先级,我可以设置一定的优先级,这样保证在线业务比离线业务的使用的磁盘要强,我们会保证优先级高的业务使磁盘。
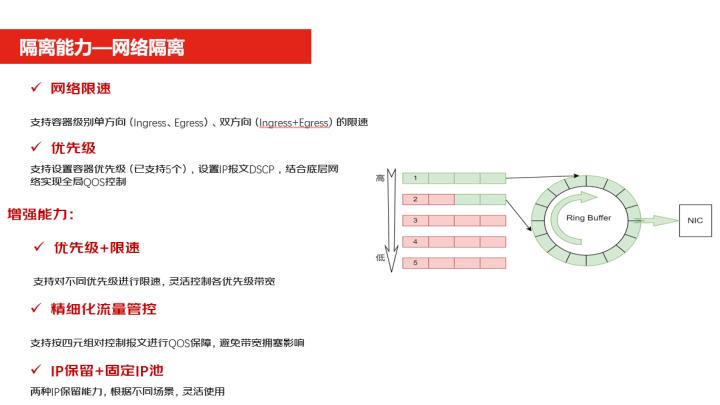
网络隔离是我们自研开发的一款 CNI插件天链,它可以做到网络的限速,它能够支持单方向和双方向的一个限速。
第二个它支持配置优先级,我们整个优先级分了5级,可以根据优先级的高低来去做流量的一个转发,在整体的增强能力上还做了优先级加限速混合使用,我可以支持业务在不同的优先级上进行限速,灵活的控制各优先级带宽的使用。
第二块我们做到了精细化的流量的管控,就支持按照四元组来进行流量的转化的控制。
第三块增强能力是做了IP保留和固定的IP池,这两类的 IP的保留。的业务方可以根据自己业务的场景的不同灵活的使用这种保留的情况。离线大框是我们整体对离线资源的管控设计,我们可以把所有的离线的任务放在一个大框下,这样可以方便统一管理离线资源的使用。
Cpu内存的压制水位线就是我们在设置了混部的时候可以设置各种的水位线,有调度水位线,有压制水位线,但你如果设置了压制水位线之后,当这个节点资源的CPU和内存使用率超过设置水位线的时候,那就会对离线资源去做压制。
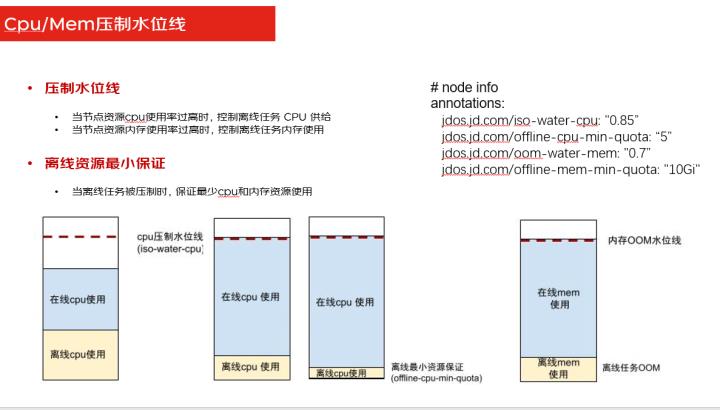
也还可以设置一个最小保证量,不能把离线任务的资源都给压制没了,我们可以设置一个最小保障量,在压到最小量的时候就不会再压了,保证离线资源还有一定的资源在用,但是它也不会占用很多的资源,给在线业务留出足够的资源去使用。
下一个大块主要就是可视化,我们分支持做了多维度的监控,可以
从集群、节点、namespace、工作负载等多个维度去观测自己的监控大盘,有问题或者有故障的时候实时的去做监控与发现。
组件监控比如有ETCD组件,API server监控,核心的一些组件,都支持监控,就可以自己随时观测到自己组件的一个状态。
调度监控就是我们在做整体资源调度的时候,我们可以看到这张盘,你可以实时的看到自己的调度的队列,那调度的QPS时延及其的负载是多少,都可以随时观察到,你有没有调度不均的情况,你有没有把调度的热点上的问题存在,都可以从这张图上去做实时的监控。
好,我今天的分享就这些,谢谢大家。
以上是关于混合多云第二课——混合技术如何每年为京东节省上亿元成本?的主要内容,如果未能解决你的问题,请参考以下文章