机器学习框架之sklearn简介
Posted AI遇见机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习框架之sklearn简介相关的知识,希望对你有一定的参考价值。
标题
简介
基本概括
举个例子
导入数据及数据预处理
训练模型
模型优化
模型选择
超参的搜索
特征选择
数据切分
Pineline
简介
今天为大家介绍的是scikit-learn。sklearn是一个Python第三方提供的非常强力的机器学习库,它包含了从数据预处理到训练模型的各个方面。在实战使用scikit-learn中可以极大的节省我们编写代码的时间以及减少我们的代码量,使我们有更多的精力去分析数据分布,调整模型和修改超参。(sklearn为包名)
基本概括
sklearn拥有可以用于监督和无监督学习的方法,一般来说监督学习使用的更多。sklearn中的大部分函数可以归为估计器(Estimator)和转化器(Transformer)两类。
估计器(Estimator)其实就是模型,它用于对数据的预测或回归。基本上估计器都会有以下几个方法:
fit(x,y) :传入数据以及标签即可训练模型,训练的时间和参数设置,数据集大小以及数据本身的特点有关
score(x,y)用于对模型的正确率进行评分(范围0-1)。但由于对在不同的问题下,评判模型优劣的的标准不限于简单的正确率,可能还包括召回率或者是查准率等其他的指标,特别是对于类别失衡的样本,准确率并不能很好的评估模型的优劣,因此在对模型进行评估时,不要轻易的被score的得分蒙蔽。
predict(x)用于对数据的预测,它接受输入,并输出预测标签,输出的格式为numpy数组。我们通常使用这个方法返回测试的结果,再将这个结果用于评估模型。
转化器(Transformer)用于对数据的处理,例如标准化、降维以及特征选择等等。同与估计器的使用方法类似:
fit(x,y) :该方法接受输入和标签,计算出数据变换的方式。
transform(x) :根据已经计算出的变换方式,返回对输入数据x变换后的结果(不改变x)
fit_transform(x,y) :该方法在计算出数据变换方式之后对输入x就地转换。
以上仅仅是简单的概括sklearn的函数的一些特点。sklearn绝大部分的函数的基本用法大概如此。但是不同的估计器会有自己不同的属性,例如随机森林会有Feature_importance来对衡量特征的重要性,而逻辑回归有coef_存放回归系数intercept_则存放截距等等。并且对于机器学习来说模型的好坏不仅取决于你选择的是哪种模型,很大程度上与你超参的设置有关。因此使用sklearn的时候一定要去看看官方文档,以便对超参进行调整。
举个例子
导入数据及数据预处理
sklearn的datasets中提供一些训练数据,我们可以使用这些数据来进行分类或者回归等等,以此熟悉sklearn的使用。
如下面代码所示我们读取了鸢尾属植物的分类数据集。load_iris()返回的是一个类似字典的对象通过关键字则可以获取对应的数据。
from sklearn.datasets import load_iris
dataSet = load_iris()
data = dataSet['data'] # 数据
label = dataSet['target'] # 数据对应的标签
feature = dataSet['feature_names'] # 特征的名称
target = dataSet['target_names'] # 标签的名称
print(target)现在我们已经读取了数据,首先第一件事应当是查看数据的特点。我们可以看到标签总共有三个,所以该数据要解决的是一个三分类问题。接着我们要去查看数据特征,用pandas的DataFrame展示是一个很好选择。
import pandas as pdimport numpy as np
df = pd.DataFrame(np.column_stack((data,label)),columns = np.append(feature,'label'))
df.head()# 查看前五行数据
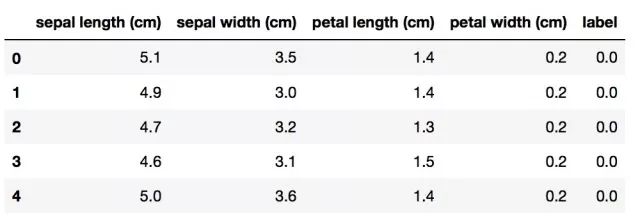
我们可以看到一条数据对应了4个连续特征,接着应当查看一些数据集的缺失值的比例,这一步非常重要,如果数据集中出现缺失值,在训练模型的时候就会出现问题。
df.isnull().sum(axis=0).sort_values(ascending=False)/float(len(df))# 检查缺失值比例

sklearn的preprocessing中有提供Imputer()处理缺失值的函数,它提供了中位数、均值、众数等策略填充缺失值。但是不同情况下处理不一定使用填充来处理缺失值。因此在遇到缺失值的时候要慎重处理。幸运的是我们这个数据集中没有缺失值,这样节省了我们处理缺失值的时间。接下来要判断数据集的样本类别是否均衡。
df['label'].value_counts() # 检查数据类别的比例

非常幸运,我们的样本类别的比例恰好是1:1:1,如果我们样本比例失衡严重,那么我们可能需要对失衡的比例做一些调整,例如重采样、欠采样等等。现在数据集看上去没有什么大的问题了,但是在训练之前,我们还是应当对数据进行标准化处理。
模型训练之前,我们要对数据进行预处理。sklearn中的preprocessing模块提供非常多的数据归一化的类。
标准化之后的数据不仅可以提高模型的训练速度,并且不同的标准会带来不一样的好处。
from sklearn.preprocessing import StandardScaler
StandardScaler().fit_transform(data)例如,z-score 标准化将样本的特征值转换到同一量纲下,使得不同特征之间有可比性。以上我们就是使用了z-score标准化,sklearn的preprocessing中还有一些其他的标准化方法,有兴趣的朋友可以查看官方文档。
训练模型
在处理好数据之后我们就可以训练模型了,以多元逻辑回归为例
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
ss = ShuffleSplit(n_splits = 1,test_size= 0.2) # 按比例拆分数据,80%用作训练
for tr,te in ss.split(data,label):
xr = data[tr]
xe = data[te]
yr = label[tr]
ye = label[te]
clf = LogisticRegression(solver = 'lbfgs',multi_class = 'multinomial')
clf.fit(xr,yr)
predict = clf.predict(xe)
print(classification_report(ye, predict))
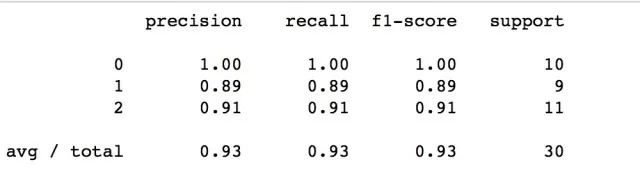
这里我们的逻辑回归使用OVR多分类方法,
OvR把多元逻辑回归,看做二元逻辑回归。具体做法是,每次选择一类为正例,其余类别为负例,然后做二元逻辑回归,得到第该类的分类模型。最后得出多个二元回归模型。按照各个类别的得分得出分类结果。
模型优化
模型选择
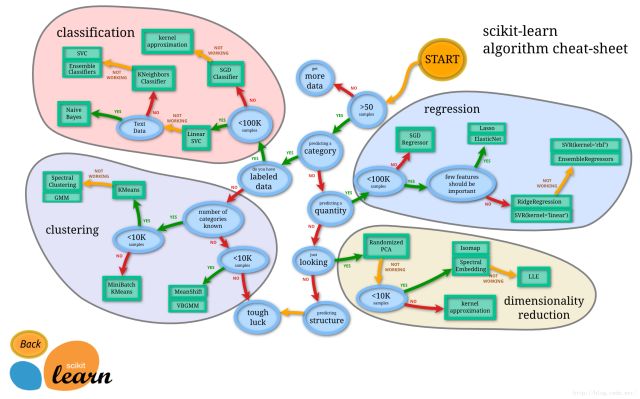
对于一个分类任务,我们可以按照以上的图来选择一个比较合适的解决方法或者模型,但模型的选择并不是绝对的,事实上很多情况下你会去试验很多的模型,才能比较出适合该问题的模型。
数据划分
我们可以使用交叉验证或其他划分数据集的方法对数据集多次划分,以得出模型平均的性能而不是偶然结果。sklearn 有很多划分数据集的方法,它们都在model_selection 里面,常用的有
K折交叉验证:
KFold 普通K折交叉验证
StratifiedKFold(保证每一类的比例相等)
留一法:
LeaveOneOut (留一)
LeavePOut (留P验证,当P = 1 时变成留一法)
随机划分法:
ShuffleSplit (随机打乱后划分数据集)
StratifiedShuffleSplit (随机打乱后,返回分层划分,每个划分类的比例与样本原始比例一致)
以上方法除了留一法都有几个同样的参数:
n_splits:设置划分次数
random_state:设置随机种子
以上的划分方法各有各的优点,留一法、K折交叉验证充分利用了数据,但开销比随机划分要高,随机划分方法可以较好的控制训练集与测试集的比例。(通过设置train_size参数)。关于划分数据集的使用可以参照上面例子中的ShuffleSplit的用法,其他的函数使用方法大同小异,详细可查看官方文档。
超参的搜索
我们上面已经初步得出模型,并且效果看起来还不错,所以我们现在应该下想办法进一步优化这一个模型了。
我们在调参的时候需要将数据集分为三部分,分别是:训练集、验证集以及测试集。训练集用于模型的训练,然后我们根据验证集的结果去调整出泛化能力较强的模型,最后通过测试集得出模型的泛化能力。如果只把数据分为训练集和测试集,也许你能调出对于测试集最合适的参数,但模型的泛化能力也许并没有在测试集上表现的那么强。
由于鸢尾属植物的数据集并不大,如果将数据分为三部分的话,训练数据就太少了,可能提高不了模型的性能。在此只是简单的介绍sklearn中的调参方法。
model_seletion里面还提供自动调参的函数,以格搜索(GridSearchCV)为例。
from sklearn.model_selection import GridSearchCV
clf = LogisticRegression()
gs = GridSearchCV(clf, parameters)
gs.fit(data, label)
gs.best_params_
通过传入字典,对比使用不同的参数的估计器的效果,得出最优的参数。这里是对逻辑回归的精度进行调整。另外我们还可以使用不同的指标来选择参数,不同的指标在sklearn.metrics中
特征选择
当特征特别多的时候,且有冗余的情况下,对特征进行选择不仅能使训练速度加快,还可以排除一些负面特征的干扰。sklearn 的feature_seletion提供了它许多特征选取函数,目前包括单变量选择方法和递归特征消除算法。它们均为转化器,故在此不举例说明如何使用。
除了使用feature_seletion的方法选取特征外,我们也可以选择那些带有特征选择的模型进行选择特征,例如随机森林会根据特征的重要程度对特征打分。
Pineline
使用pineline可以按顺序构建从数据处理到和训练模型的整个过程。pineline中间的步骤必须转化器(对数据进行处理)。使用pineline的好处就是可以封装一个学习的过程,使得重新调用这个过程变得更加方便。中间的过程用多个二元组组成的列表表示。
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
clf = LogisticRegression()
new_clf = Pipeline([('pca',pca),('clf',clf)])
上面的封装的估计器,会先用PCA将数据降至两维,在用逻辑回归去拟合。
小结
本期介绍sklearn只做简单介绍,还有一些方面没有涉及,例如特征抽取、降维等等,这些在官方文档中有详细使用方法及参数介绍。
参考来源
http://scikit-learn.org/stable/documentation.html 官方文档
以及网上各位大佬的博文
AI遇见机器学习
mltoai
以上是关于机器学习框架之sklearn简介的主要内容,如果未能解决你的问题,请参考以下文章