我理解的朴素贝叶斯模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我理解的朴素贝叶斯模型相关的知识,希望对你有一定的参考价值。
参考技术A 文/胡晨川
我想说:“任何事件都是条件概率。”为什么呢?因为我认为,任何事件的发生都不是完全偶然的,它都会以其他事件的发生为基础。换句话说,条件概率就是在其他事件发生的基础上,某事件发生的概率。
条件概率是朴素贝叶斯模型的基础。
假设,你的川术公司正在面临着用户流失的压力。虽然,你能计算用户整体流失的概率(流失用户数/用户总数)。但这个数字并没有多大意义,因为资源是有限的,利用这个数字你只能撒胡椒面似的把钱撒在所有用户上,显然不经济。你非常想根据用户的某种行为,精确地估计一个用户流失的概率,若这个概率超过某个阀值,再触发用户挽留机制。这样能把钱花到最需要花的地方。
你搜遍脑子里的数据分析方法,终于,一个250年前的人名在脑中闪现。就是 “贝叶斯Bayes” 。你取得了近一个月的流失用户数、流失用户中未读消息大于5条的人数、近一个月的活跃用户数及活跃用户中未读消息大于5条的人数。在此基础上,你获得了一个“一旦用户未读消息大于5条,他流失的概率高达%”的精确结论。怎么实现这个计算呢?先别着急,为了解释清楚贝叶斯模型,我们先定义一些名词。
概率(Probability)——0和1之间的一个数字,表示一个特定结果发生的可能性。比如投资硬币,“正面朝上”这个特定结果发生的可能性为0.5,这个0.5就是概率。换一种说法,计算样本数据中出现该结果次数的百分比。即你投一百次硬币,正面朝上的次数基本上是50次。
几率(Odds)——某一特定结果发生与不发生的概率比。如果你明天电梯上遇上你暗恋的女孩的概率是0.1,那么遇不上她的概率就是0.9,那么遇上暗恋女孩的几率就是1/9,几率的取值范围是0到无穷大。
似然(Likelihood)——两个相关的条件概率之比,即给定B发生的情况下,某一特定结果A发生的概率和给定B不发生的情况下A发生的概率之比。另一种表达方式是,给定B的情况下A发生的几率和A的整体几率之比。两个计算方式是等价的。
因为上面在似然当中提到了条件概率,那么我们有必要将什么是条件概率做更详尽的阐述。
如上面的韦恩图,我们用矩形表示一个样本空间,代表随机事件发生的一切可能结果。的在统计学中,我们用符号P表示概率,A事件发生的概率表示为P(A)。两个事件间的概率表达实际上相当繁琐,我们只介绍本书中用得着的关系:
A事件与B事件同时发生的概率表示为P(A∩B),或简写为P(AB)即两个圆圈重叠的部分。
A不发生的概率为1-P(A),写为P(~A),即矩形中除了圆圈A以外的其他部分。
A或者B至少有一个发生的概率表示为P(A∪B),即圆圈A与圆圈B共同覆盖的区域。
在B事件发生的基础上发生A的概率表示为P(A|B),这便是我们前文所提到的条件概率,图形上它有AB重合的面积比上B的面积。
回到我们的例子。以P(A)代表用户流失的概率,P(B)代表用户有5条以上未读信息的概率,P(B|A)代表用户流失的前提下未读信息大于5条的概率。我们要求未读信息大于5条的用户流失的概率,即P(A|B),贝叶斯公式告诉我们:
P(A|B)=P(B|A) P(A)/P(B)*
如下图,由这个公式我们就能轻松计算出,在观察到某用户的未读信息大于5条时,他流失的概率为80%。80%的数值比原来的30%真是靠谱太多了。
朴素贝叶斯的应用不止于此,我们再例举一个更复杂,但现实场景也更实际的案例。假设你为了肃清电商平台上的恶性商户(刷单、非法交易、恶性竞争等),委托算法团队开发了一个识别商家是否是恶性商户的模型M1。为什么要开发模型呢?因为之前识别恶性商家,你只能通过用户举报和人肉识别异常数据的方式,人力成本高且速率很慢。你指望有智能的算法来提高效率。
之前监察团队的成果告诉我们,目前平台上的恶性商户比率为0.2%,记为P(E),那么P( E)就是99.8%。利用模型M1进行检测,你发现在监察团队已判定的恶性商户中,由模型M1所判定为阳性(恶性商户)的人数占比为90%,这是一个条件概率,表示为P(P|E)=90%;在监察团队判定为健康商户群体中,由模型M1判定为阳性的人数占比为8%,表示为P(P| E)=8%。乍看之下,你是不是觉得这个模型的准确度不够呢?感觉对商户有8%的误杀,还有10%的漏判。其实不然,这个模型的结果不是你想当然的这么使用的。
这里,我们需要使用一个称为“全概率公式”的计算模型,来计算出在M1判别某个商户为恶性商户时,这个结果的可信度有多高。这正是贝叶斯模型的核心。当M1判别某个商户为恶性商户时,这个商户的确是恶性商户的概率由P(E|P)表示:
P(E|P)=****P(P|E) P(E)/(P(E)P(P|E)+P( E)*P(P| E))******
上面就是全概率公式。要知道判别为恶性商户的前提下,该商户实际为恶性商户的概率,需要由先前的恶性商户比率P(E),以判别的恶性商户中的结果为阳性的商户比率P(P|E),以判别为健康商户中的结果为阳性的比率P(P| E),以判别商户中健康商户的比率P( E)来共同决定。
实验三 朴素贝叶斯算法及应用
实验三 朴素贝叶斯算法及应用
作业信息
| 博客班级 | 博客班级链接 |
|---|---|
| 作业要求 | 作业要求链接 |
| 作业目标 | 掌握朴素贝叶斯算法,可以借用该算法解决特定应用场景 |
| 学号 | 3180701125 |
一、实验目的
- 理解朴素贝叶斯算法原理,掌握朴素贝叶斯算法框架;
- 掌握常见的高斯模型,多项式模型和伯努利模型;
- 能根据不同的数据类型,选择不同的概率模型实现朴素贝叶斯算法;
- 针对特定应用场景及数据,能应用朴素贝叶斯解决实际问题。
二、实验内容
- 实现高斯朴素贝叶斯算法。
- 熟悉sklearn库中的朴素贝叶斯算法。
- 针对iris数据集,应用sklearn的朴素贝叶斯算法进行类别预测。
- 针对iris数据集,利用自编朴素贝叶斯算法进行类别预测。
三、实验报告要求
- 对照实验内容,撰写实验过程、算法及测试结果;
- 代码规范化:命名规则、注释;
- 分析核心算法的复杂度;
- 查阅文献,讨论各种朴素贝叶斯算法的应用场景;
- 讨论朴素贝叶斯算法的优缺点。
四、实验过程及结果
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df[\'label\'] = iris.target
df.columns = [
\'sepal length\', \'sepal width\', \'petal length\', \'petal width\', \'label\'
]
data = np.array(df.iloc[:100, :])
return data[:, :-1], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_test[0], y_test[0]
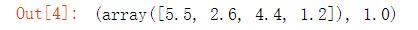
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# 标准差(方差)
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# 处理X_train
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分类别求出数学期望和标准差
def fit(self, X, y):
labels = list(set(y))
data = {label: [] for label in labels}
for f, label in zip(X, y):
data[label].append(f)
self.model = {
label: self.summarize(value)
for label, value in data.items()
}
return \'gaussianNB train done!\'
# 计算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev)
return probabilities
# 类别
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(
self.calculate_probabilities(X_test).items(),
key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))
model = NaiveBayes()
model.fit(X_train, y_train)
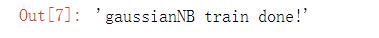
print(model.predict([4.4, 3.2, 1.3, 0.2]))
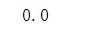
model.score(X_test, y_test)
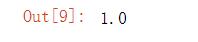
scikit-learn实例
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)

clf.score(X_test, y_test)

clf.predict([[4.4, 3.2, 1.3, 0.2]])
from sklearn.naive_bayes import BernoulliNB, MultinomialNB # 伯努利模型和多项式模型
五、实验小结
通过本次实验使我基本对朴素贝叶斯算法的框架有了较为深刻的掌握。对于朴素贝叶斯算法而言,它有着较为稳定的分类效率和对缺失数据不敏感的特点,且对小规模的数据表现很好,能够处理多分类任务。但是该算法需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
以上是关于我理解的朴素贝叶斯模型的主要内容,如果未能解决你的问题,请参考以下文章