李宏毅老师2020年深度学习系列讲座笔记5
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记5相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&
1. On-policy & off-policy
如果是一边玩一边学习就是on 如果是站一边看别人玩学习那就是off
随便一点,是不是就是一边打怪一边增长经验和先看别人怎么打怪偷师的区别?

之前我们用的gradient descent是on-policy的,这是因为我们每一次都要更新\\theta,因此我们是一边往前走一边不断更新自己。但是我们想要尽量用off-policy,因为这样的话每一个data(状态、函数和选择等)都可以用很多次,(on-policy的每一次运算都是用完了立刻丢掉了)
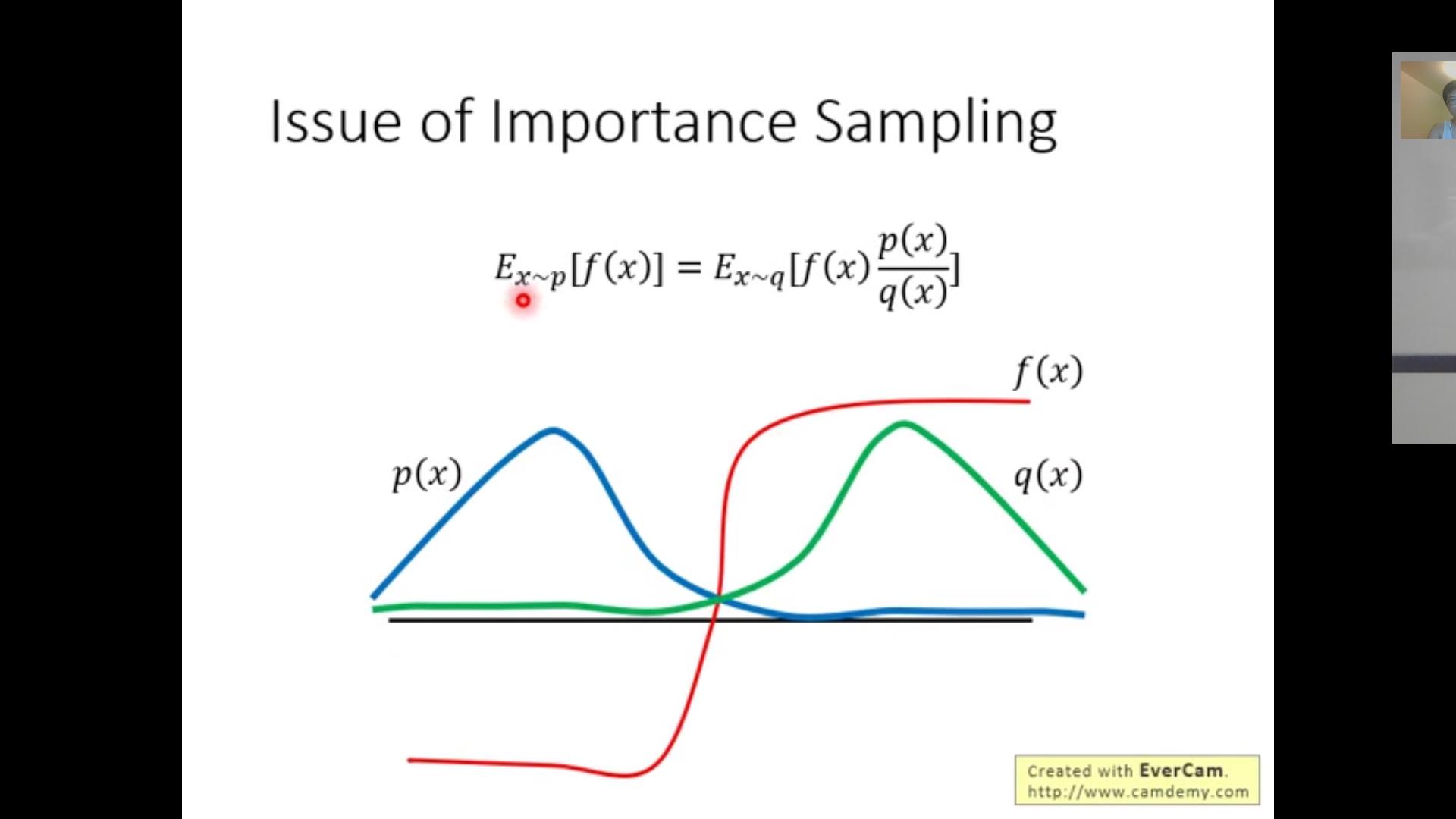
一个技巧:【importance sampling】(不是RL专用的,很常见】
很多时候,我们想研究的真实的x的distribution/p(x)/和我们能得到的x'的q(x)是不一样的,因此我们需要对于原本E(X)的计算公式修改(否则计算出来的是和q(x)相关而不能体现p(x)的特点)。
我们采用的公式就是f(x)*p(x)/q(x)在q(x)决定的trajectory上求期望的方法,这个关键在于当q(x)=0时的x需要满足p(x)=0,也就是对于q(x)有一些限制。

此外,在我们讲为什么要用importance sampling之前我们再讲一点相关的知识。在实际应用中,p(x)和q(x)还是不能差别太大,这是因为虽然二者期望一样但是方差等其他信息还是有差别的。所以一旦取样取得不够多或者不够好很有可能因为方差而导致得到的结果差别很大。
小总结:

又来推公式啦

主要应用就是derivative和条件概率的公式,不加赘言。关键在于红线花掉的那个比例,为什么去掉可以有三种理解方式:
1.本身state出现的概率和trajectory和action关系都不大,因此可以忽略
2.实际应用中有些state甚至只会出现一次(比如图像识别)因此很难求p_\\theta 和p_\\theta',因此干脆自己洗脑说这个不重要= =
3.可以理解为a和s独立,因此条件概率和联合概率相等(本质上也是1.)
如何保证\\theta和\\theta'足够相似呢??——————PPO!
下面讲讲PPO和它的前身TRPO,具体方法就是加一个类似regularation(ML的)的项\\beta KL(\\theta,\\theta')。TRPO是改成了一个constraint,结果差不多但是实际应用TRPO难度大得多。
KL不是参数距离而是result的距离

具体算法如下:

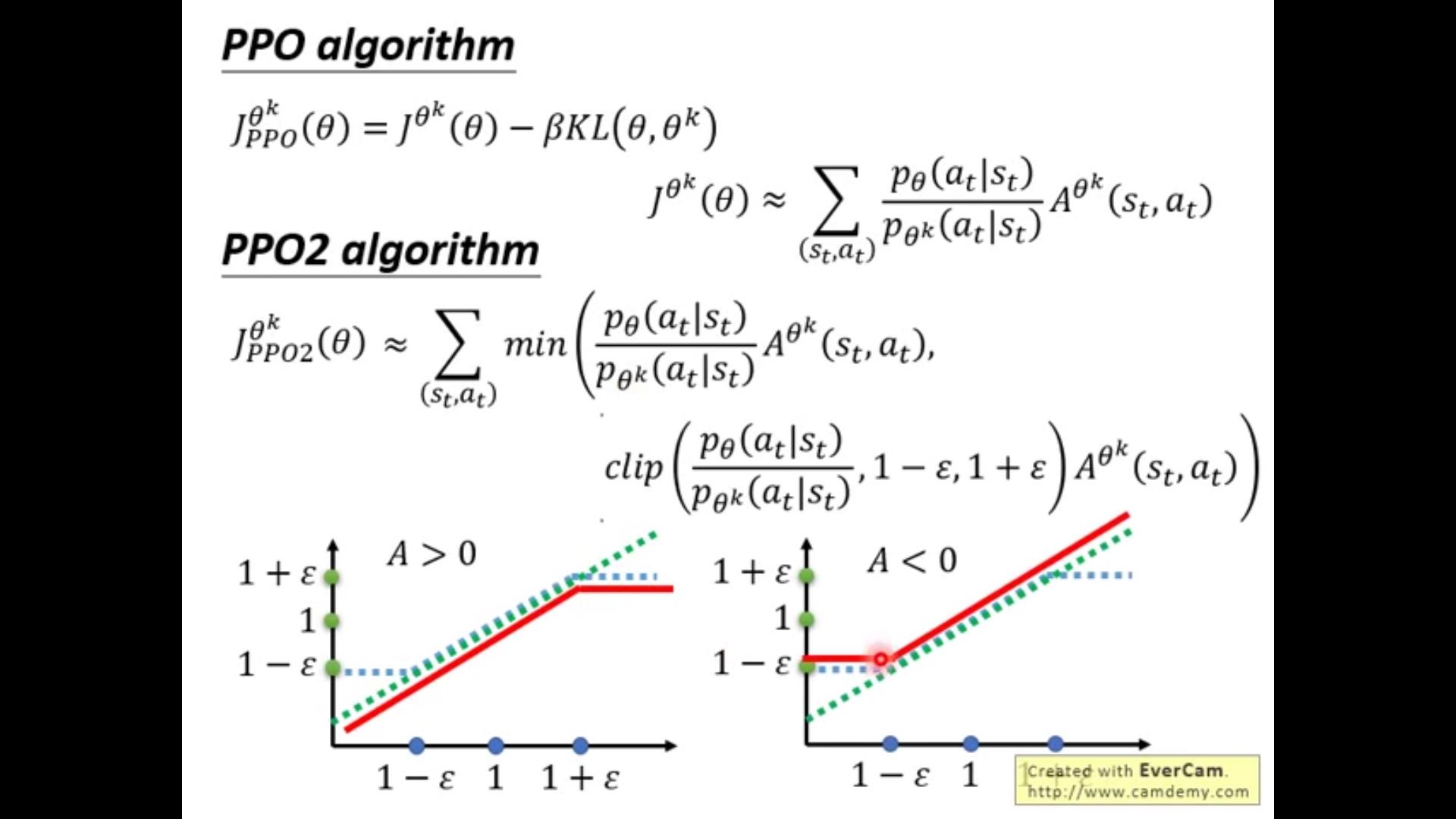
clip:截断函数,把第一项的分数函数截断到1-\\epsilon 和1+\\epsilon之间。
A>0时候,我们想尽量把p_\\theta / p_\\theta^k增大,因此就像红线那样尽量大到1+\\epsilon;A《0时候,我们想尽量把p_\\theta / p_\\theta^k压小,因此就像红线那样尽量压到1-\\epsilon;
最后show一下PPO的方法与别的方法的结果比较:
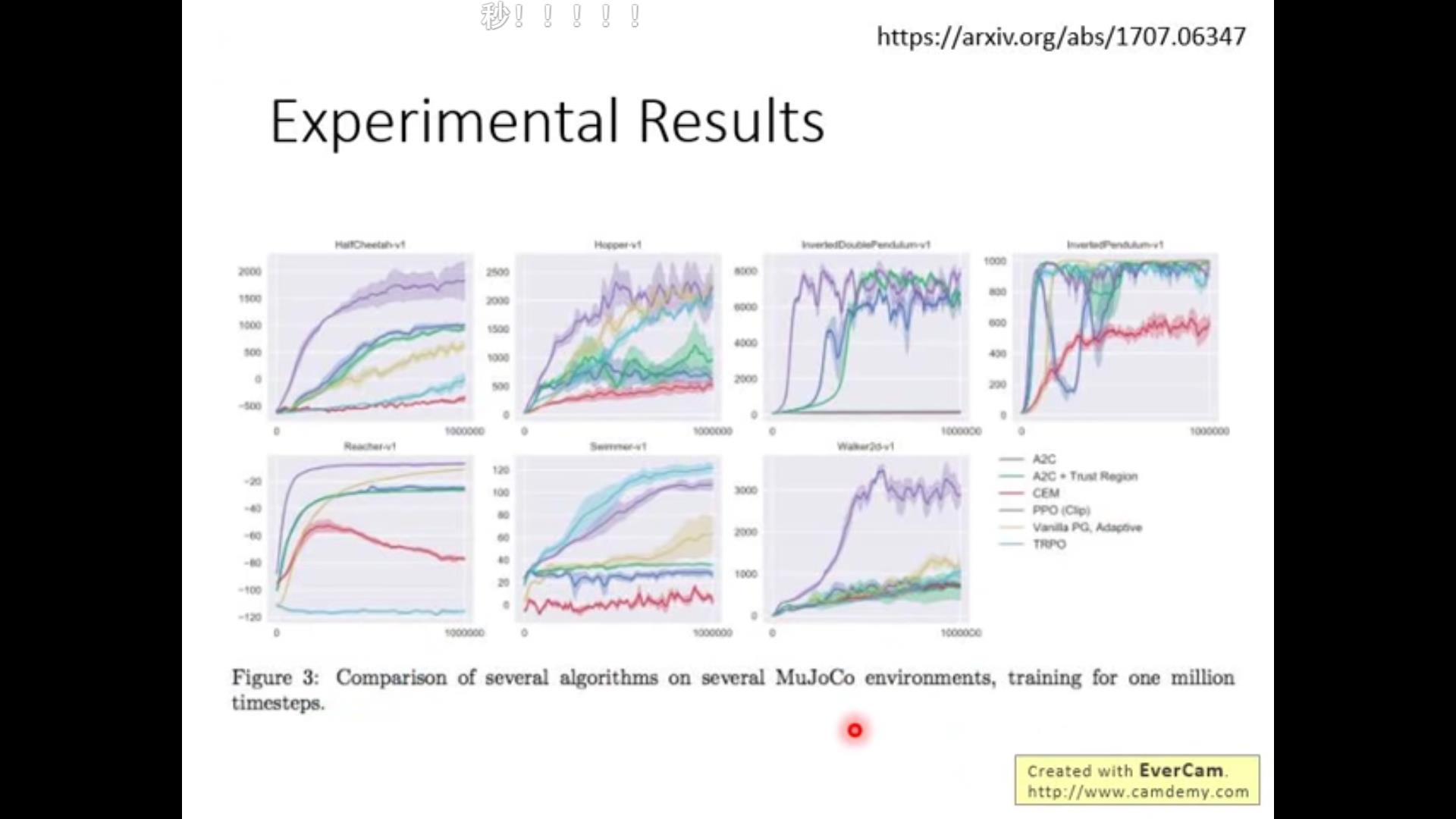
以上是关于李宏毅老师2020年深度学习系列讲座笔记5的主要内容,如果未能解决你的问题,请参考以下文章