李宏毅老师2020年深度学习系列讲座笔记4
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记4相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&
终于讲到PPO了哈哈哈哈超搞笑超好玩的
首先给出基本要素啦,依旧是我们熟悉的actor、environment、reward function

和policy~

接下来就是讲了流程啦,观察到s_1→做出a_1→得到r_1→观察到新的s_2→……
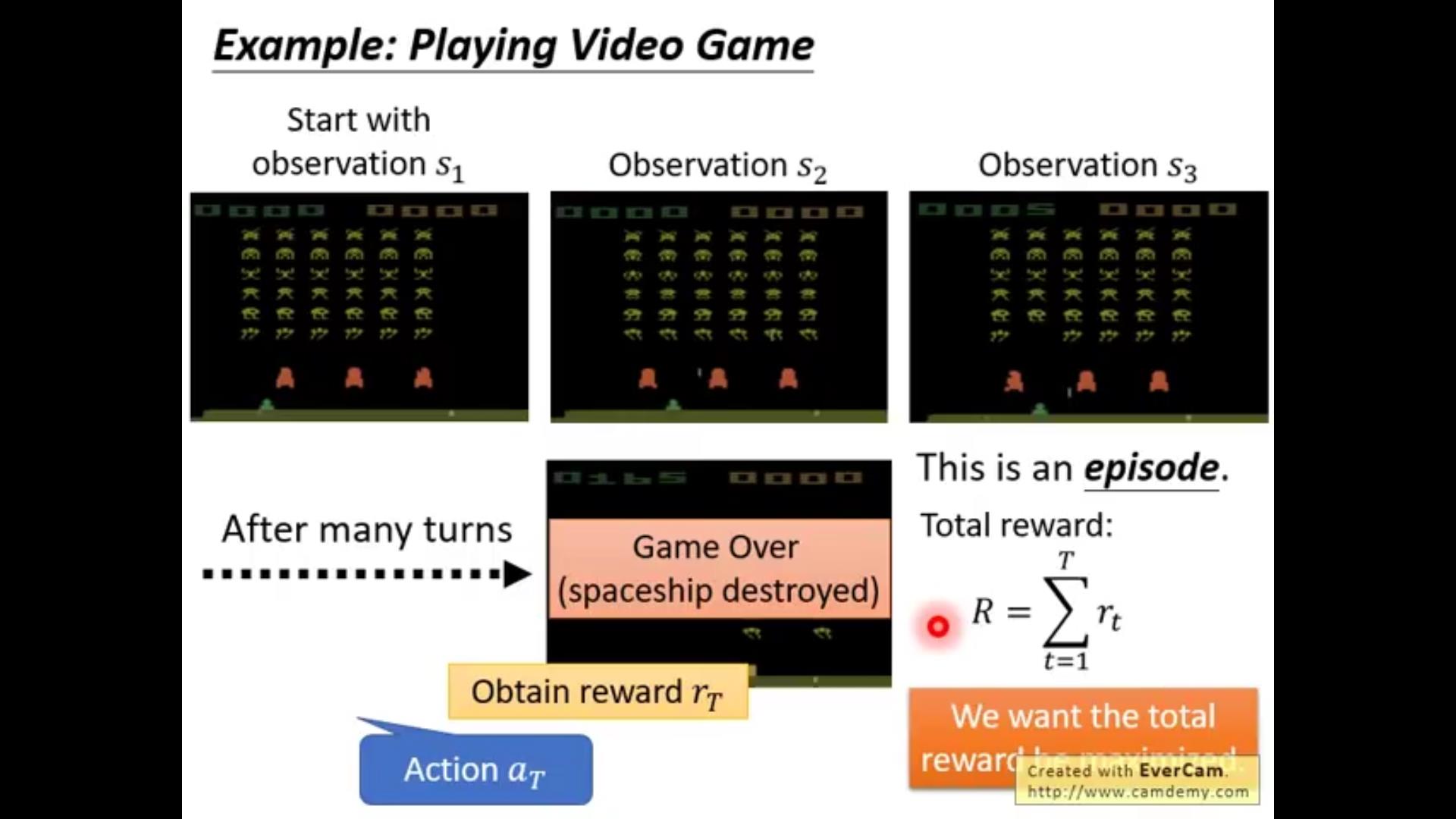
一般来说~s_2和s_1、a_1都有关,而且一般来说是一个distribution而不是一个确定的值(打游戏并不是你看到这个页面做一个行动的结果是给定的,那样也太无聊啦!)
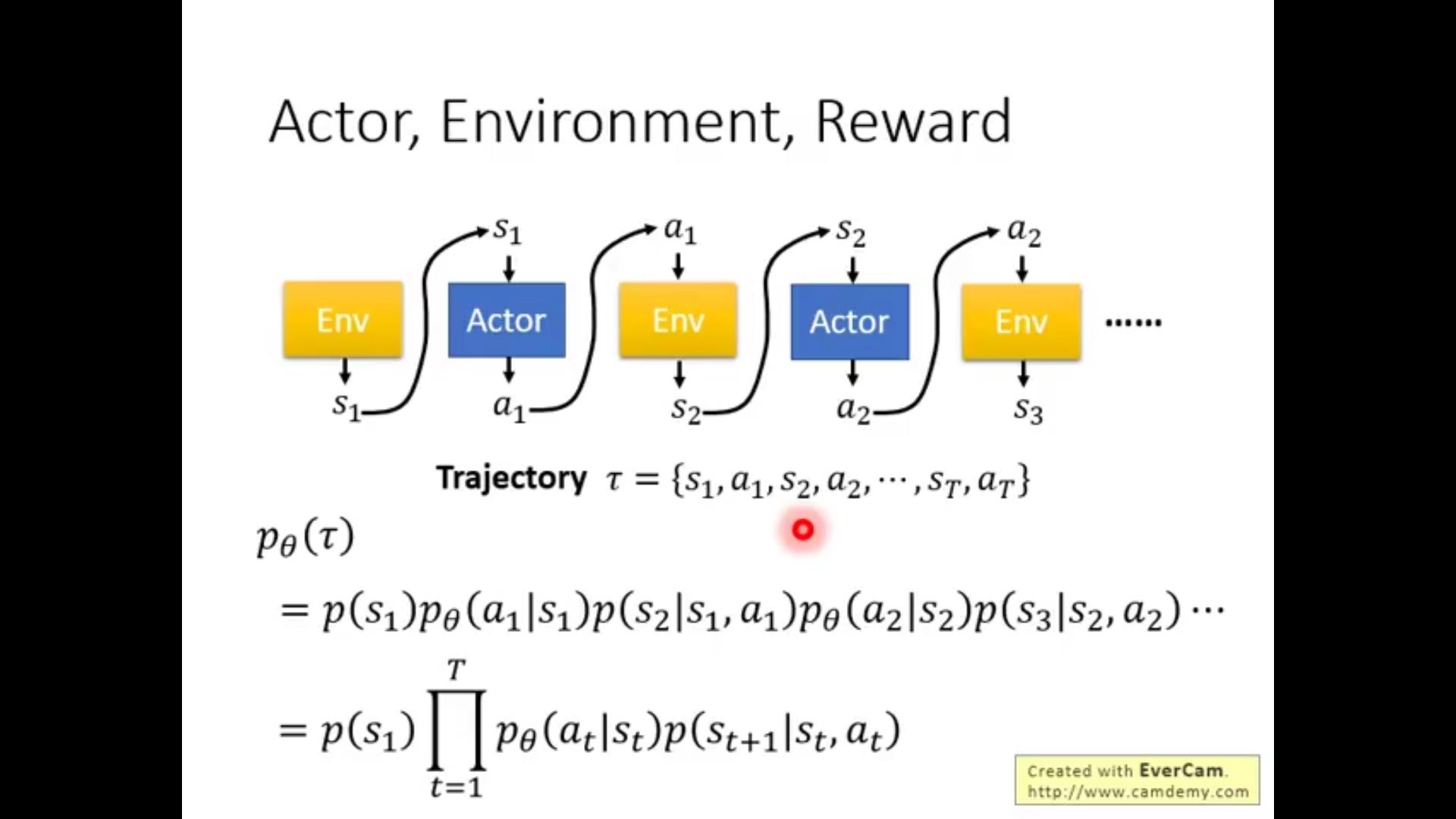
而且reward也不是一定的~因此我们针对这个问题,计算的不是一个reward而是reward的期望!(很多个trajectory的均值)

具体方法(公式推导在第二次笔记里说过了)

实作思路(复习啦)
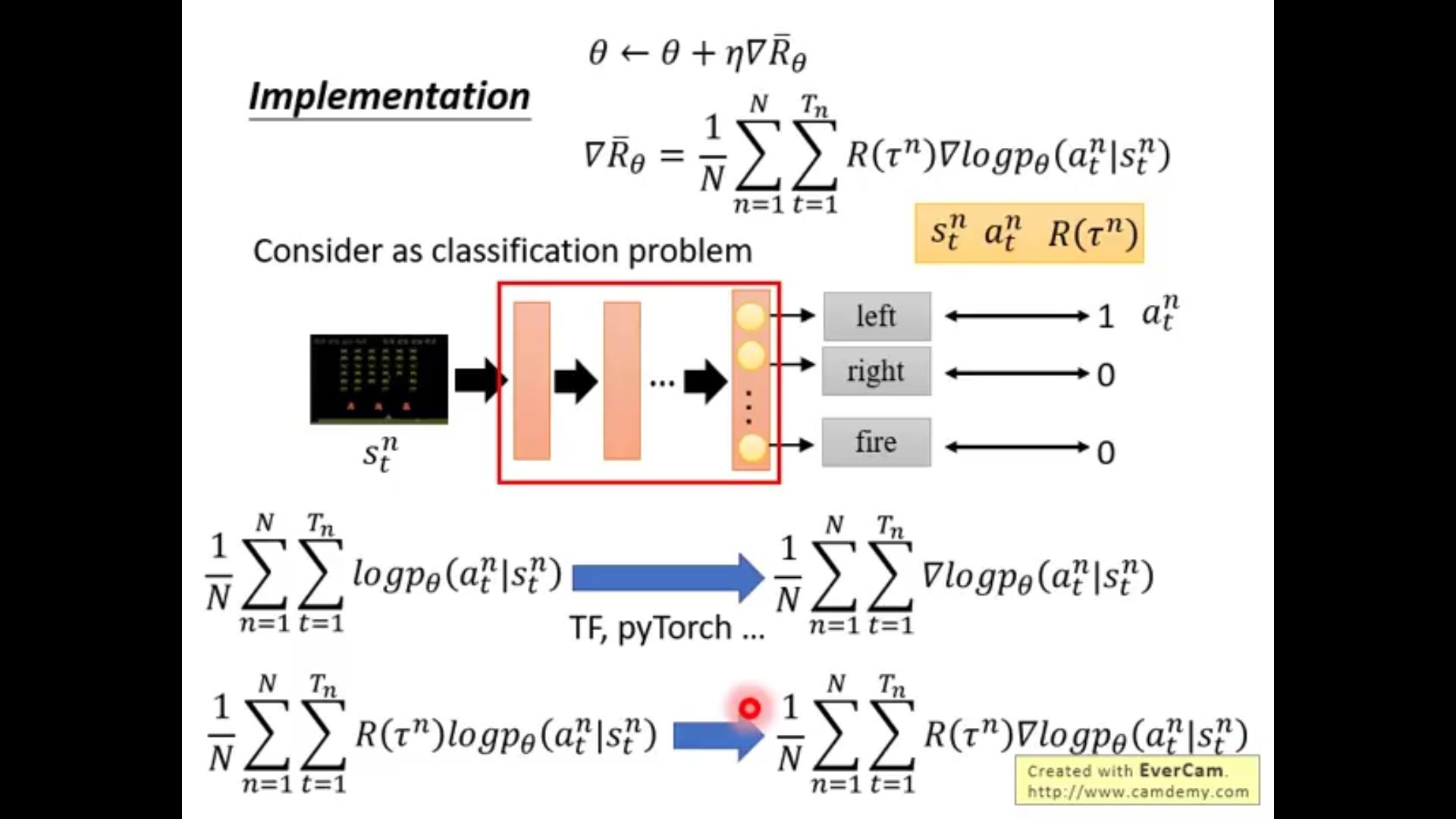
用到的作为对照的都是sampling的结果
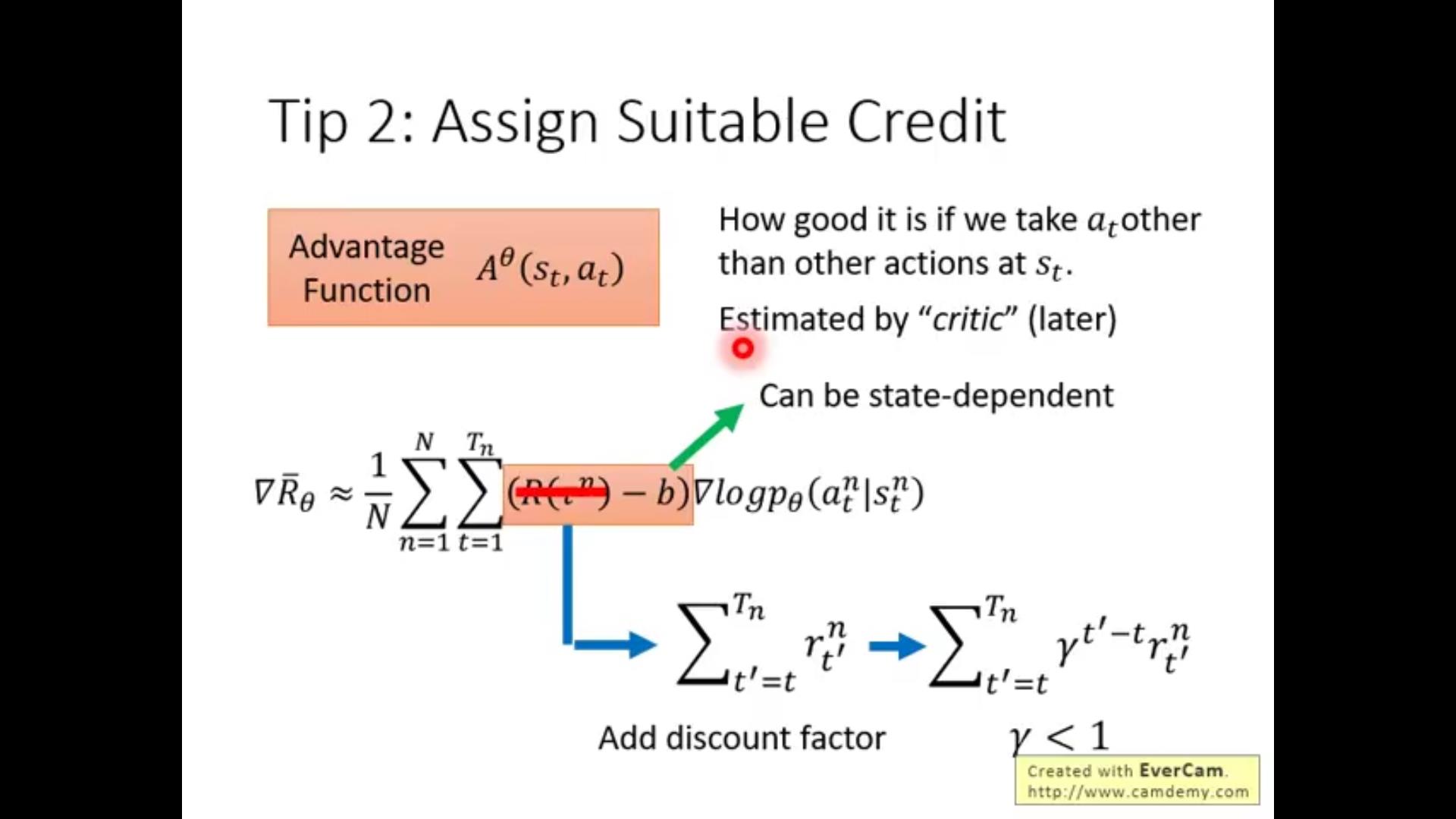
tips:1.baseline:因为reward是非负的 可能给不太好的action增大probability都会导致reward增加,因此通过add一个baseline只加比baseline大的,小的(由于乘上一个负数)概率会减小

2.可能有“败方MVP”现象:虽然有的总reward不好但是单步action好;有的虽然reward高但是有不好的action。
解决思路:因为每一条路上各个action如果都用(R(\\tao^n)-b)一样的权重的话会造成平均但是不公平,因此我们用这一步之后所有的reward而不是整条trajectory的reward作为权重

还要乘上一个discount factor(\\gamma)
1.本身离这action越远和action的关系越小
2.人们更希望得到奖励的时间尽量及时
以上是关于李宏毅老师2020年深度学习系列讲座笔记4的主要内容,如果未能解决你的问题,请参考以下文章