李宏毅老师2020年深度学习系列讲座笔记7
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记7相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&
第七个视频 继续咯!
【接6 为什么Q-learning会有over-estimate的现象而Double DQN可以避免?】
Q- learning因为一直以rt+maxQ来拟合Q值,因此求的一直是关于a最大的Q,但是由于本身再计算Q 的时候会考虑有误差和随机,因此一旦Q的随机性增加了一点点Q值最后输出的Q(st,at)就会比本应该的值要大(over estimate)。我们解决方法是同时构造两个Q值函数Q和Q',其中一个用于寻找最大的a,另一个用于更新Q值-一旦Q选大了Q'会给一个合适值,一旦Q'大了。。。Q不会选这个啦。

另外一种改进是Dueling DQN-原本DQN是直接输出Q函数,但是新的是分别输出V和A,然后再算Q。这个方法的优势在于:
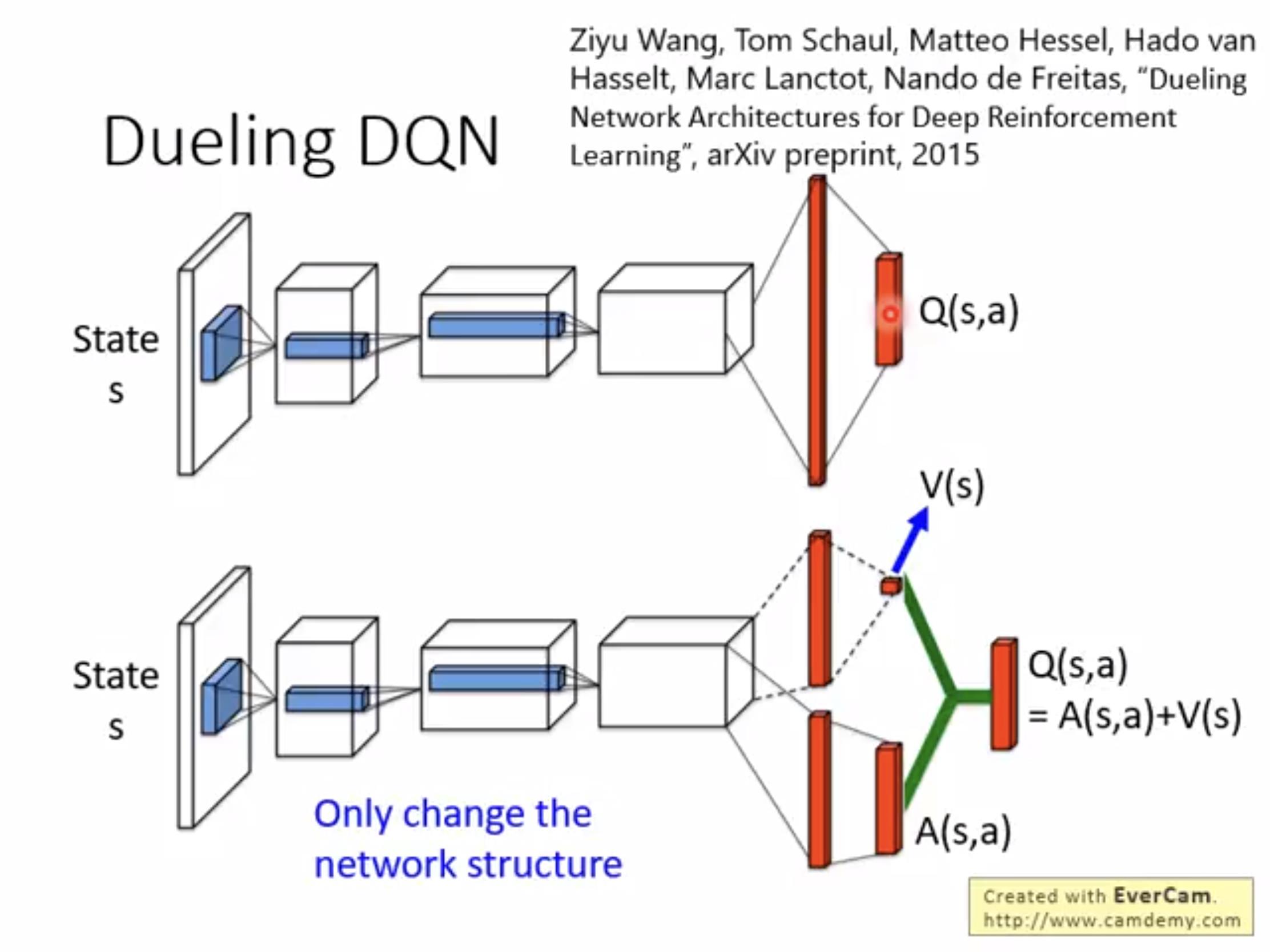
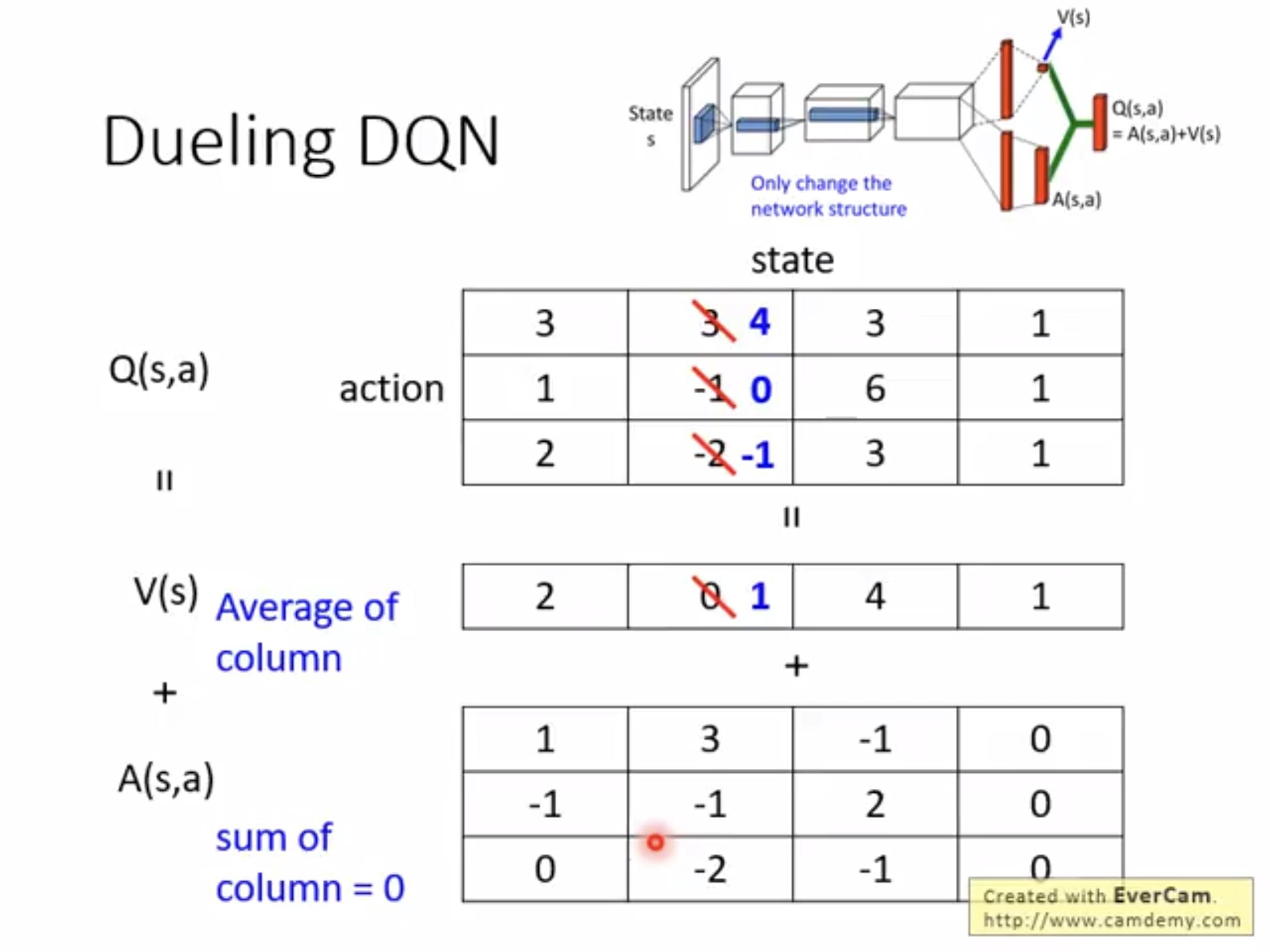
将s、a的影响分开,这样如果想让Q升高可以提高state的value可以通过提高状态的reward。为了使得A和为0我们也需要在输出之前给一个normalize的过程。

接下来讲几个优化的小tips:
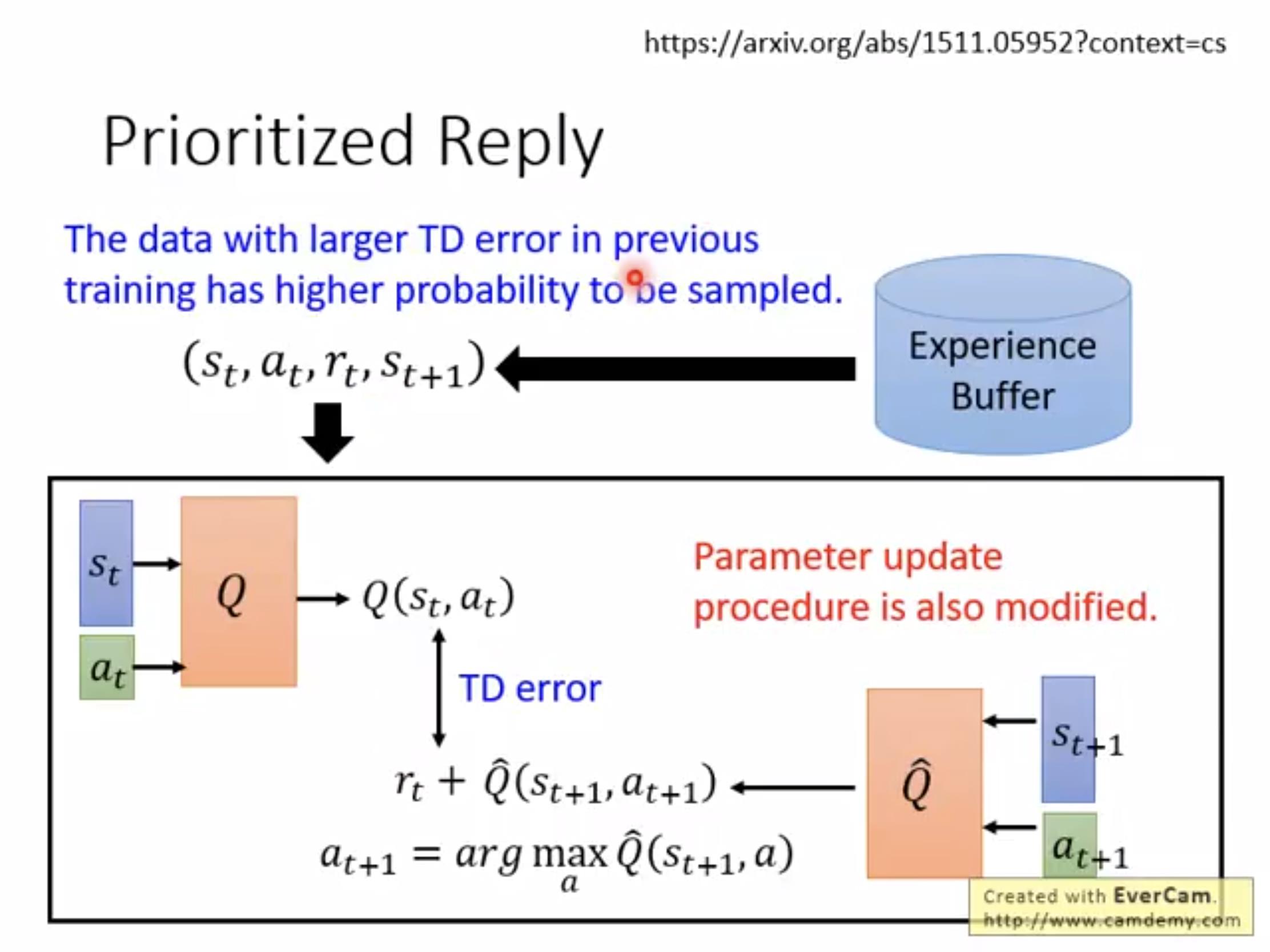
1.Prioritized reply:
在学习的时候设置一个buffer,在里面存储一些已经学习过的(st,at,rt,st+1),如果TD-error大就增大学习的可能性(多学学不好的)。
或者可以结合TD和MC,制作的一个多步的(不像TC只用一步或者MC要用很多很多步到最后)

另外一个思路是改变随机化的对象,原本我们为了防止agent一意孤行会给一个小概率让他不止探索目前发现的"最优行为",但是发现给到参数效果更好

这样做有什么好处呢?见下图

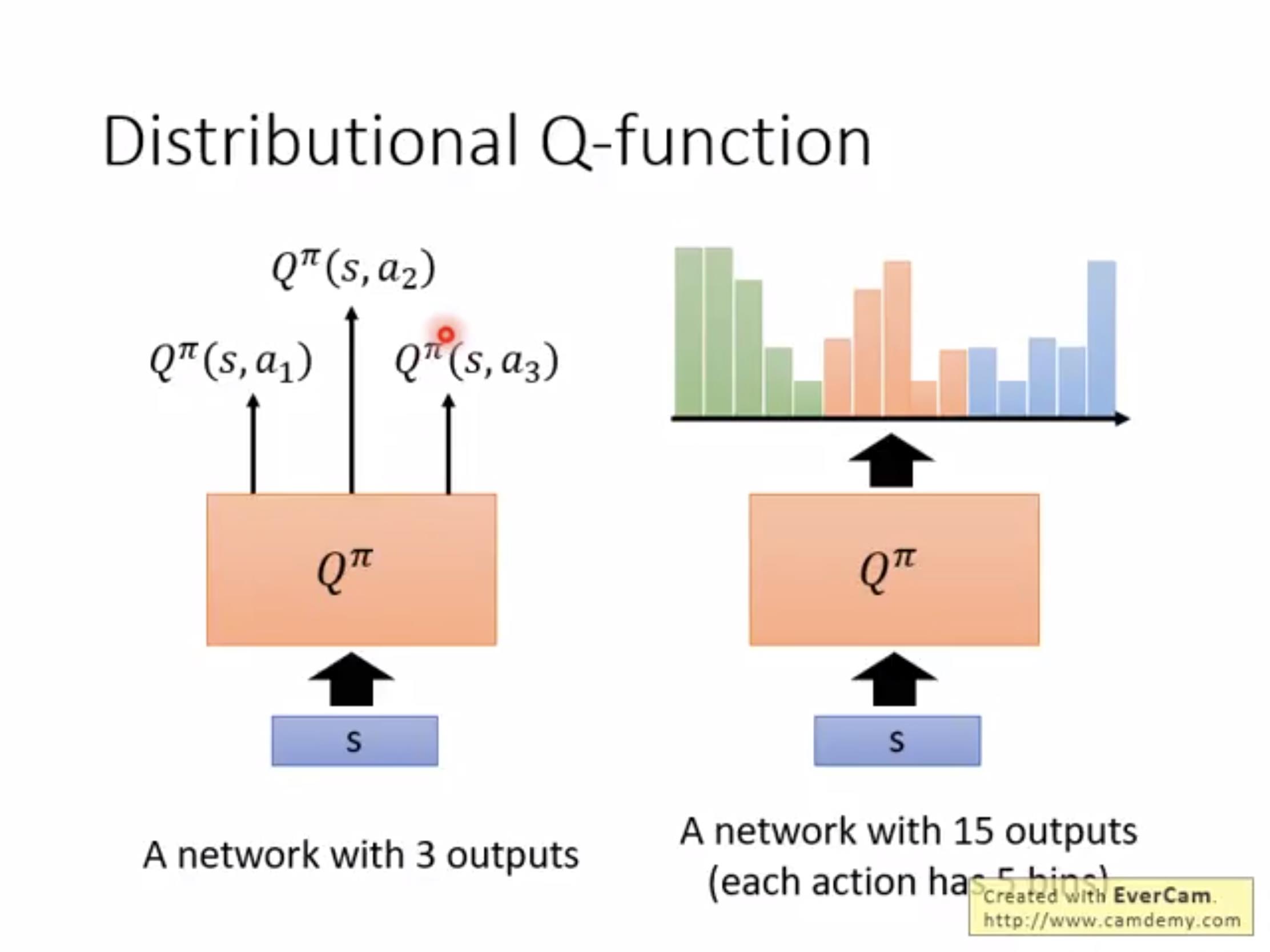
另一种DQN的优化方式是分布;只需要知道Q- learning也可以输出一个分布就行,这样可以便于做出很多优化,比如分析分布的性质可能可以在期望差不多的时候选择方差小的,但是由于相对复杂现在不太火。

给了一个例子如下:
在本堂课的最后给出了这几个优化思路的结果分析如下:

其中A3C之后会讲到,可以看到,各个优化都用的rainbow方法效果最好。之后给出另一种方式量化。可以看到,没有多步和对"短板的开小灶"学习效果很差,没用分布或者没有噪音加入学习很快但是最终收敛效果不好,没有dueling也是,但是为啥没有double的看着差不多呢?文中给出了一个解释:因为double是为了抑制over- estimate,但是有了distribution加入之后,本质上给出的就是一定range之内的概率分布,概率过大过小的情况都被忽略掉了,因此太大的情况不会出现。

以上是关于李宏毅老师2020年深度学习系列讲座笔记7的主要内容,如果未能解决你的问题,请参考以下文章