李宏毅老师2020年深度学习系列讲座笔记2
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅老师2020年深度学习系列讲座笔记2相关的知识,希望对你有一定的参考价值。
瞎看吧。。。。至少做个笔记
https://www.bilibili.com/video/BV1UE411G78S?from=search&seid=11796990666136537025
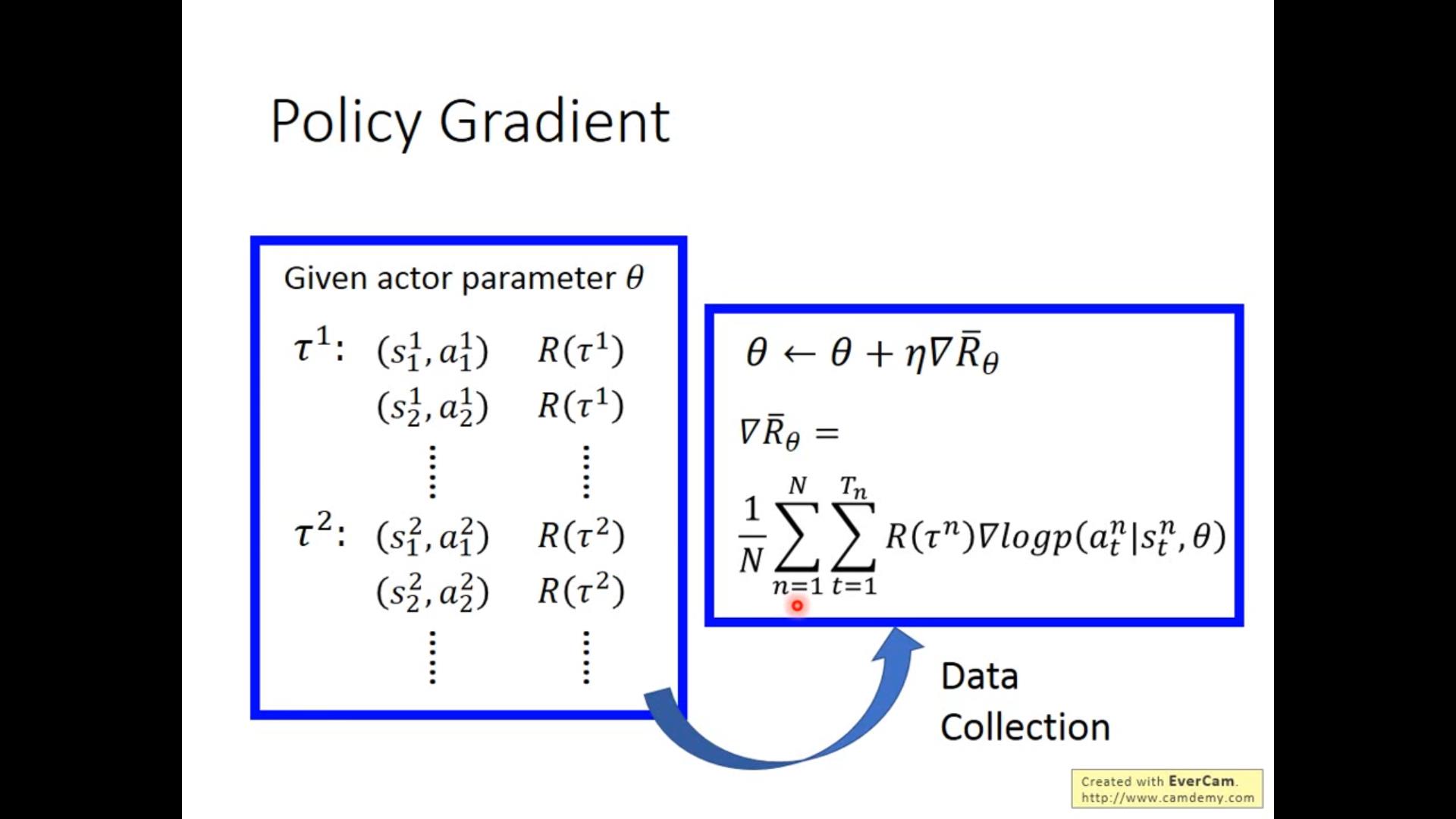
Policy Gradient(看起来不全)
主要思路:
有一个state-agent takes an action-the state changes to another state-agent get a reward-
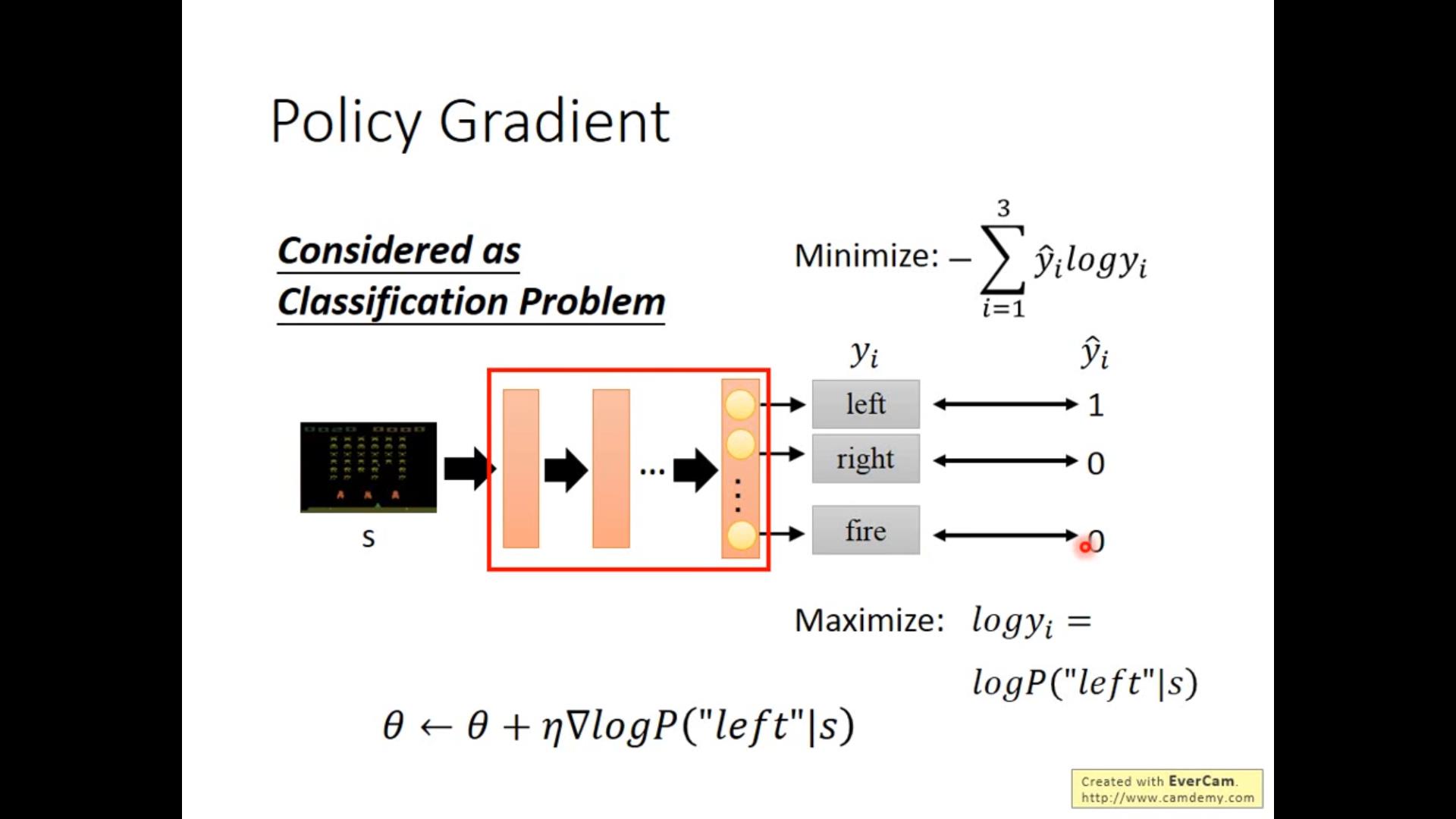
例子:分类问题对应的优化的目标函数是交叉熵损失(cross entropy loss)函数
希望输出的结果是(1,0,0)(向左走),\\theta更新的方向也是‘left’
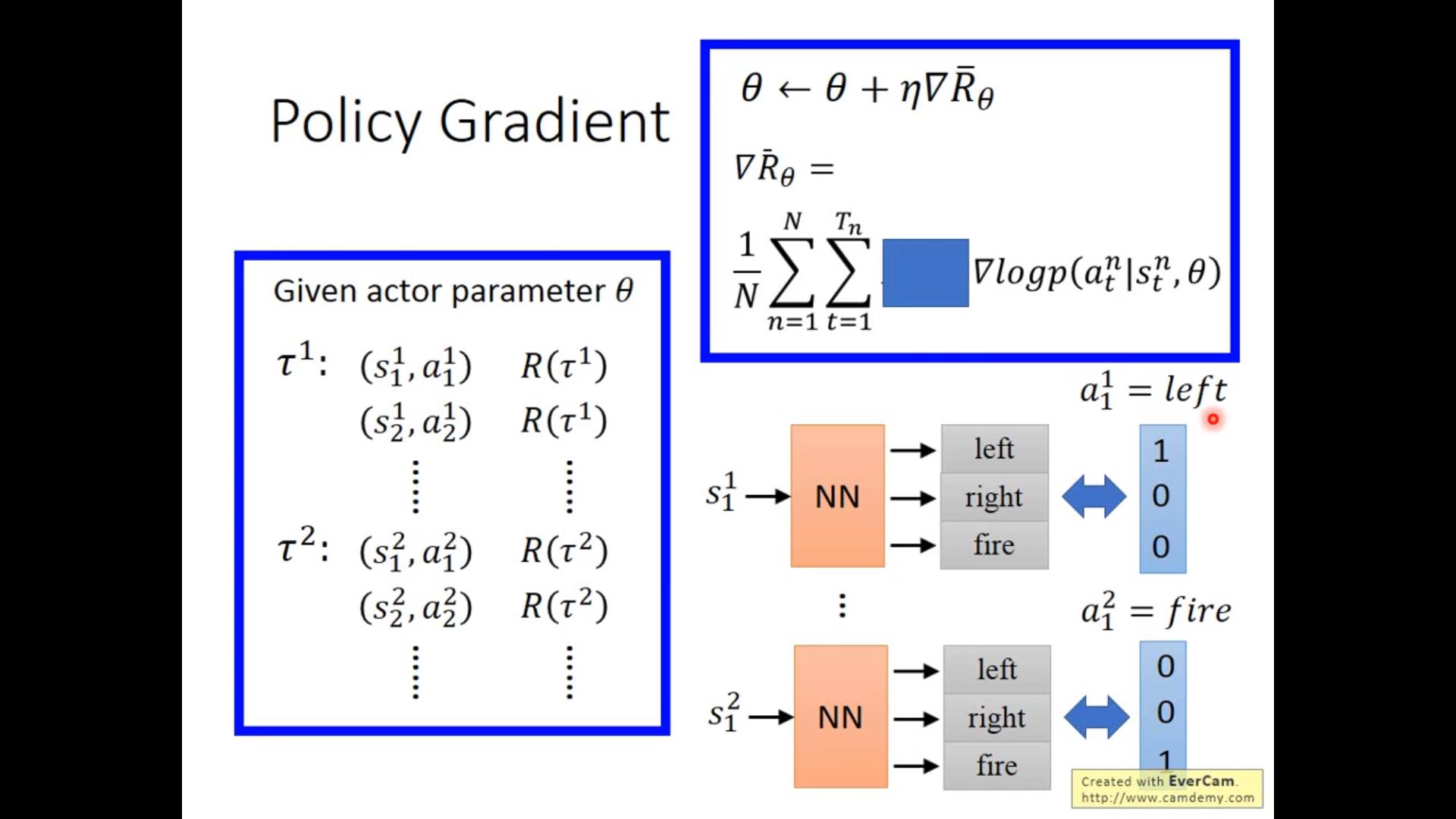
问题可以看作,当状态是s_1^1的时候我们target是a_1,想让agent做这个action。
与直接做action有什么区别?A:在前面(蓝色糊住的地方)会乘以R(reward)
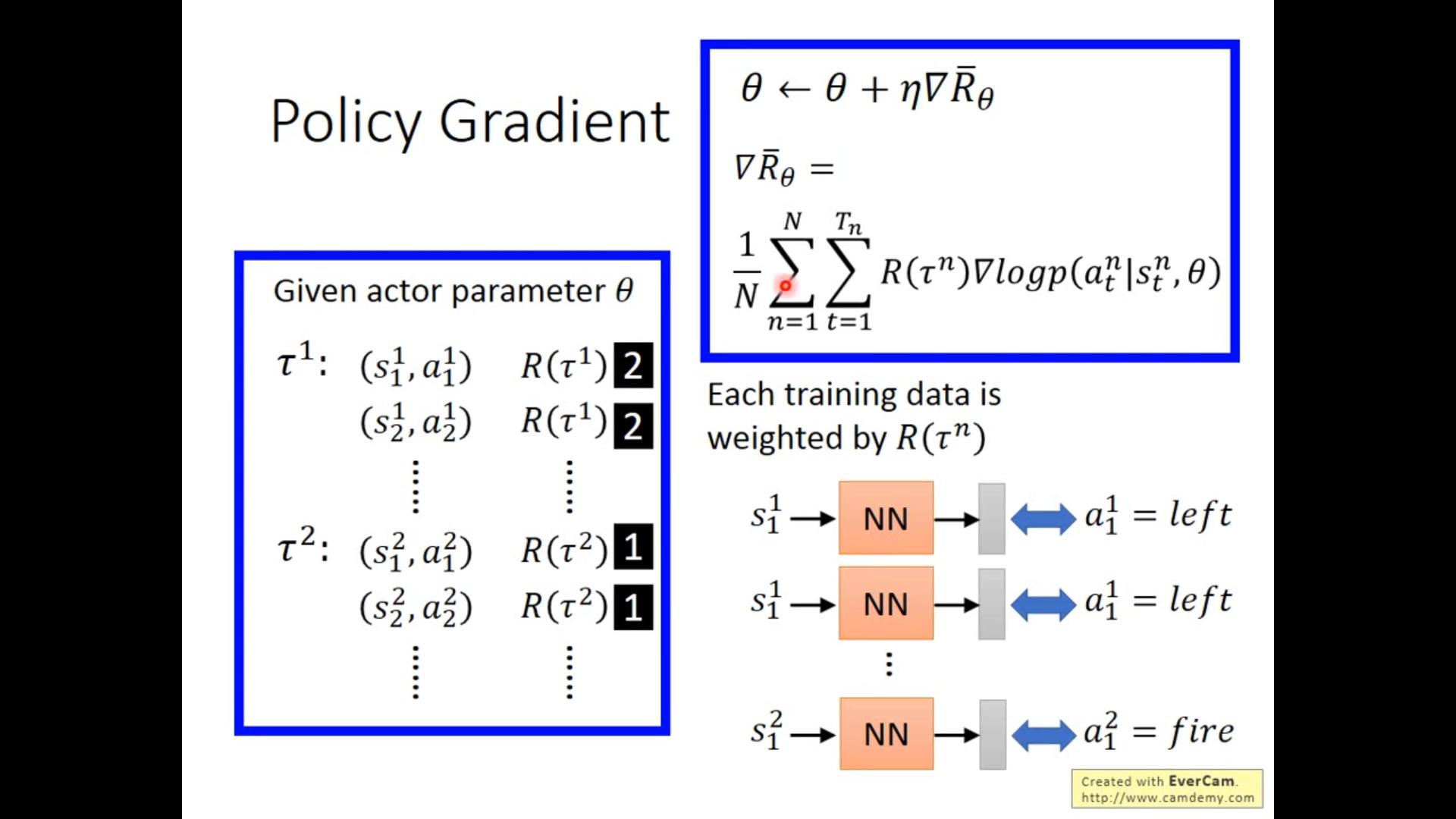
唯一区别是加入weight,每收集一次数据就要train一次network。。。。
以上是关于李宏毅老师2020年深度学习系列讲座笔记2的主要内容,如果未能解决你的问题,请参考以下文章