基于DNN的3D点云语义分割
Posted 新缸中之脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于DNN的3D点云语义分割相关的知识,希望对你有一定的参考价值。
由于增强现实/虚拟现实的发展及其在计算机视觉、自动驾驶和机器人领域的广泛应用,点云学习最近备受关注。深度学习已成功地用于解决二维视觉问题,然而在点云上使用深度学习技术还处于起步阶段。语义分割的目标是将给定的点云根据点的语义含义分成几个子集。本文重点研究基于点的方法这一技术路线中最先进的语义分割技术。
深度学习的早期尝试,是将点云预处理成结构化的网格格式,但代价是计算成本的增加或深度信息的丢失。3D 点云分割是将点云分类到不同区域的过程,同一区域中的点具有相似的属性。由于冗余性高、采样密度不均匀以及点云数据缺乏明确的结构,3D 点云分割是一项具有挑战性的任务。
将点云分割成前景和背景是处理 3D 点云的基本步骤,可以精确确定 3D 数据中对象的形状、大小和其他属性。但是,在 3D 点云中分割对象并不是简单的任务。点云数据通常是嘈杂、稀疏并且无组织的。通常来说点的采样密度不均匀,表面形状可以任意,数据中业没有统计分布模式。而且由于 3D 传感器的限制,背景与前景纠缠在一起。此外,很难有一个计算高效、内存开销低的深度学习模型来执行分割任务。
点云分割有助于分析各种应用中的场景,如定位和识别对象、分类和功能提取。3D 点云分割可部署在场景级别(语义细分)、对象级别(实例细分)和部件级别(部件细分)。语义分割检测每个像素所属的对象类别,并将同一类的多个对象视为单个实体。
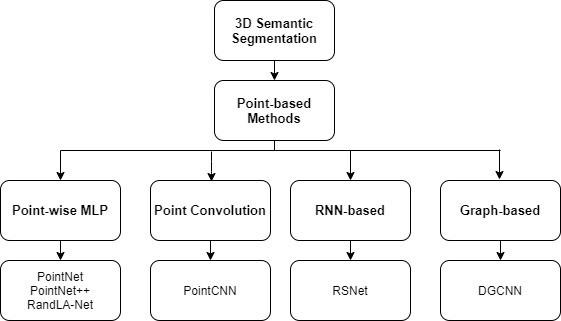
各种基于点的 3D 语义细分技术的分类法可按 4 个范式给出: (a)逐点 MLP、(b) 点卷积、(c) 基于RNN (d) 基于图。
1、PointNet
卷积架构需要高度规整的输入数据格式,以便共享权重或执行核优化。由于点云和网格不是常规格式,大多数方法将数据转换为常规的 3D体素网格或图像集合,然后再将其送入深度网络架构。
然而,这种变换使由此产生的数据变得不必要的庞大,并引入了量化副作用,从而掩盖数据的自然不变性。PointNet直接利用并考虑输入点云中的不变性。
PointNet 架构包含三个关键模块:最大池化层对称地聚合来自所有点的信息、本地和全局信息组合结构、输入点和点特征的联合对齐网络。为了找到无需输入的对称函数,在变换元素上应用对称函数,在点集上定义一般函数近似。
PointNet 利用多层感知器网络近似一个函数,并通过单变量函数和最大汇总函数的组合转换函数。函数的输出形成矢量,该载体被视为输入集的全局签名,并通过将全局特征与每个点特征对联,馈送到每个点特征。然后,根据组合点功能提取新的每点功能,因为每个点将同时了解本地和全局信息。
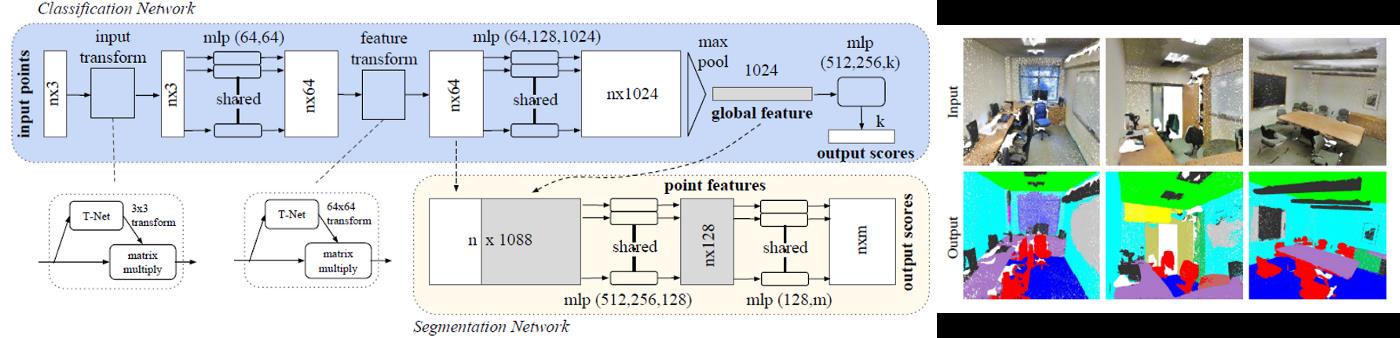
形成第三个模块联合对齐网络的灵感来自这样一个事实,即如果点云进行几何转换,点云的语义标记必须是不变的。PointNet 利用T-net 架构预测仿射转换矩阵,并将此转换直接应用于输入点的坐标。T-net 由点独立功能提取、最大池和完全连接层组成。功能空间中的转换矩阵具有更高的维度。因此,为了优化,在softmax训练损失中增加了一个约束特征转换矩阵接近正交矩阵的正则参数。下图提供了PointNet的详细架构和语义分割输出:
2、PointNet++
PointNet 不能捕获由于点所在空间而诱发的本地结构,从而限制其识别细粒度模式的能力和对复杂场景的泛化能力。PointNet+ 引入了一个分层神经网络,该网络将 PointNet 递归应用于输入点集的嵌套分区。
通过利用空间距离,PointNet++ 能够通过不断增加的上下文比例来学习本地功能。PointNet++按基础空间的距离指标将一组点划分为重叠的局部区域。与 CNN 类似,它从小的淋雨提取捕获精细几何结构的本地特征,这些本地特征进一步组合成更大的单元并经过处理,以产生更高级的功能。此过程重复,直到获得整个点集的功能。
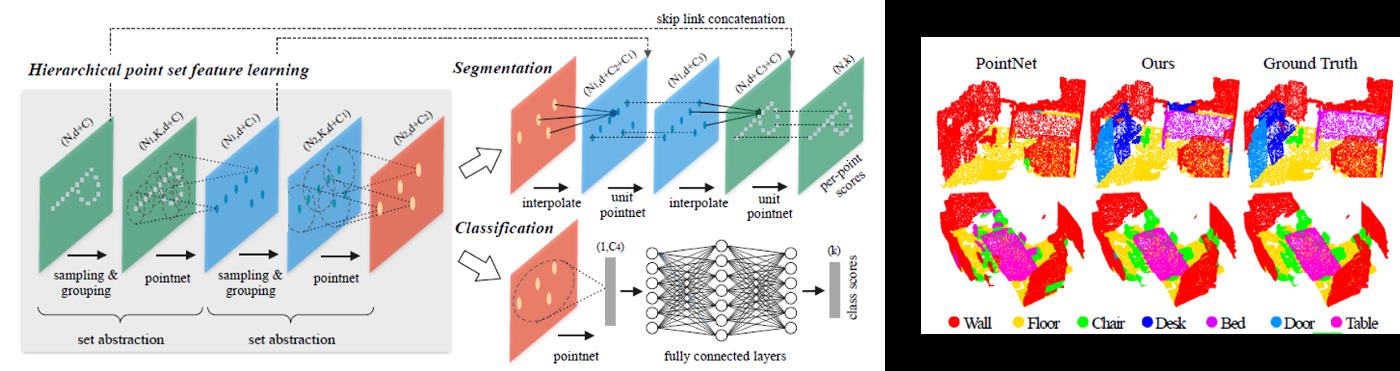
PointNet++的设计解决了两个问题:如何生成点集的分区,以及如何通过本地学习抽象点集或局部功能。虽然 PointNet 使用单个最大池来聚合整个点集,但 PointNet++ 构建了点的分层分组,并沿分层逐步抽象较大的局部区域。此分层结构由多个抽象级别组成,在每个级别上,对一组点进行处理和抽象,以产生一组元素较少的新组。抽象层由三层组成:采样层、分组层和PointNet层。采样层从输入点中选择一组点,从而定义了局部区域的中心。然后,分组层通过在中心周围找到"邻近"点来构建区域集。PointNet 层使用迷你点网将局部区域模式编码为特征矢量。图中说明了用于 PointNet++ 的架构细节及其与PointNet的比较。
3、RandLA-Net
RandLA-Net 引入了一种轻量级神经结构,可以处理大型点云,速度是其他架构的 200 倍,这是因为大多数现有架构都使用昂贵的采样技术以及预处理/后处理方法。
PointNet 在计算效率上是有效的,但无法捕获每个点的上下文信息。RandLA-Net 在单次传递中处理大型 3D 点云,无需任何预处理步骤,如体素化、块分区或图形构造。RandLA-Net 仅依赖于网络内的随机采样,因此需要的内存和计算要少得多。本地特征聚合器通过考虑本地空间关系和点的特征,连续获得更大的接受领域。
整个RandLA-Net网络包含共享的多层感知器,无需依赖图构建和内核化,因此效率很高。不同的采样方法,如最远点采样、反向密度重要性采样、基于生成器的采样等,在计算效率方面非常显著。但是,它们可能导致显著特征的下降。因此,RandLA-Net提出了一个本地聚合模块。此模块并行应用于每个 3D 点,它由三个神经单元组成。
LocSE:在这个模块中,所有特征都明确用于编码点云的三维坐标信息。它使用 K-最近邻居算法收集相邻点,然后执行相对点位置编码,这往往有助于网络学习局部特征。最后,在点特征增强中,编码的相对点位置与相应的点特征对联,并获取增强的特征矢量。此矢量编码本地几何结构。
注意力池:对于给定的一组局部特征,使用一个共享函数来聚合邻近点特征集并学习注意力评分。共享的多层感知器之后是Softmax函数,随后汇总这些学习的注意力分数。
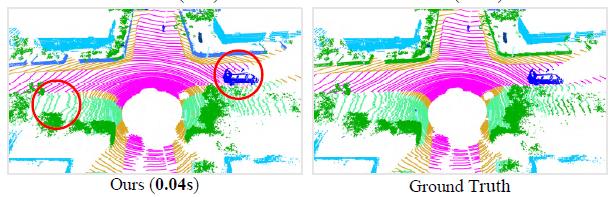
扩张残留块:由于随机采样不断降采样输入点云,因此有必要增加每个点的接受场。使用 Resnet 架构以及Skip连接,多个 LocSE 和注意力池连接形成扩张残留块。此块负责膨胀接受域并扩展有效邻域。下图图将RandLA-Net的输出与PointNet++进行比较。
4、PointCNN
PointCNN 能够利用网格中密集表示的空间局部相关性,并为从点云中学习功能提供了框架。PointCNN 从输入点学习χ转换,以促进与点相关的输入特征的加权,并将点排列成规范顺序。PointCNN 的架构包含两种设计:
-
分层卷积:在常规网格中,卷积会递归于本地网格片端,这通常会降低网格分辨率,同时增加通道数。同样,在点云中,χ-Conv会递归地应用于"项目"或"聚合",从邻里信息中获取的代表点较少,但每个点的信息都更丰富。
-
χ-Conv 操作符:χ- Conv 操作符在局部操作,并将相关点和临近点作为输入并执行卷积。相邻点转换为代表点的局部坐标系统,然后分别提升这些本地坐标并结合相关功能。
具有两个χ-Conv层的PointCNN将输入点转换为较少的特征表示,但每个都具有更丰富的功能。然而,顶级χ-Conv层的训练样本数量迅速下降,使得训练效率低下。为了解决这个问题,PointCNN 使用更密集的连接,其中在χ-Conv 层中保留更具代表性的点。此外,为了保持网络的深度,同时保持接受场增长率,采用扩张卷积。对于分割任务,需要高分辨率点计算输出,因此使用 Conv-DeConv 架构并遵循 U-Net 设计。
5、递归切片网络
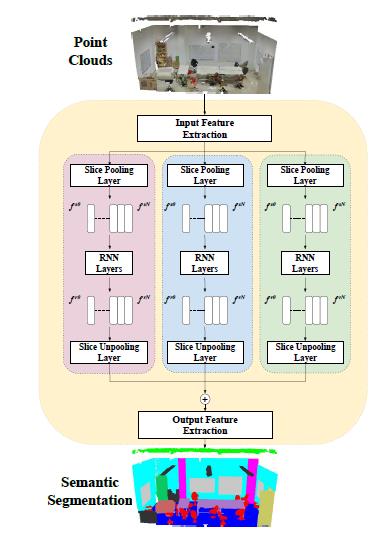
大多数其他语义分割网络不对点云之间的依赖关系建模。RSNet 的关键组件是轻量级的局部依赖模块。局部依赖模块效率高,具有切片池/拆卸层的时间复杂性,如 O(n) w.r.t 输入点数和 O(1) w.r.t 局部上下文分辨率。
RSNet 将原始点云作为输入,输出语义标签。给定一组未排序点和候选标签集,RSNets 的任务是给每个点分配一个语义标签。输入和输出提取块用于独立特征生成。中间是本地依赖模块。输入特征块处理输入点并生成特征,输出块以处理的特征作为输入,并为每个点生成最终预测。两个块都使用多个 1 x 1 卷积层的序列来为每个点生成独立特征表示。
局部依赖模块包含新颖的切片池层、双向循环神经网络 (RNN) 层和切片去池化层。局部上下文问题通过首先将无序点投影到有序的功能中,然后应用传统的端到端学习算法来解决。投影通过一个新的切片池层实现。在此图层中,输入是未排序点的特征,输出是聚合特征的有序序列。接下来,RNN 应用于此序列中的模型依赖关系。最后,切片去池化层将序列中的功能分配回原始的点。下图提供了 RSNet 的详细架构。RSNet 在三个广泛使用的基准上超越以前的先进方法,同时需要较少的推断时间和内存。
6、动态Graph CNN
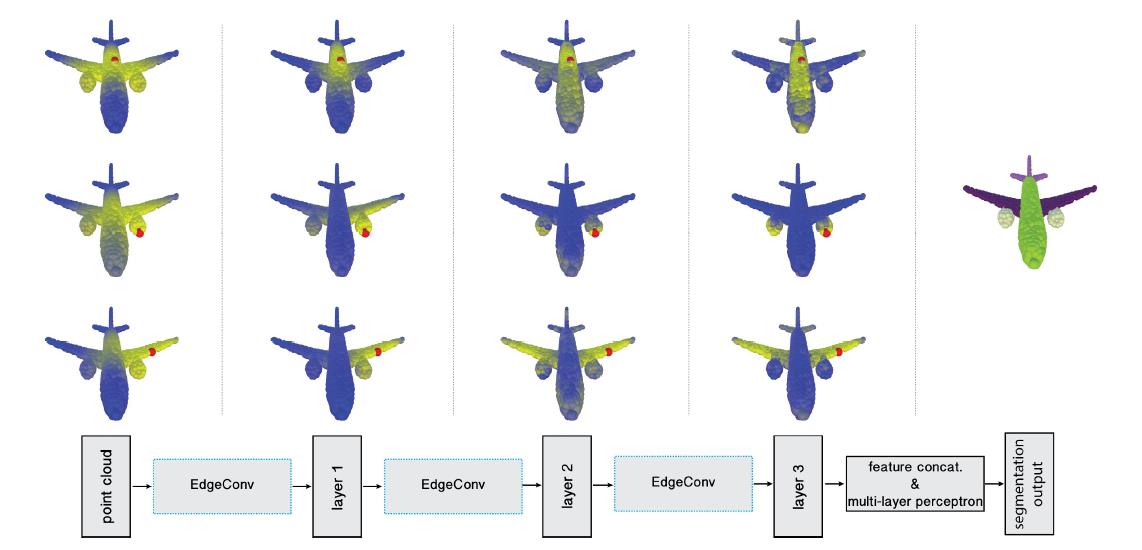
DGCNN 是一个EdgeConv,适用于基于 CNN 的点云(包括分类和细分)的高层任务。EdgeConv 在网络的每个层动态计算的图上工作。它捕获局部几何结构,同时保持排列不变。EdgeConv 不会直接从嵌入中生成点功能,而是生成描述点与其邻居之间关系的边缘特征。EdgeConv 的设计旨在对邻余的排序保持不变。
由于 EdgeConv 构建了局部图并学习边缘嵌入,因此该模型能够将点分组到欧几里德空间和语义空间中。DGCNN 没有像 PointNet 那样处理单个点,而是利用本地几何结构,构建本地邻域图,并在连接相邻点对的边缘应用类似卷积的操作。边缘卷积 (EdgeConv), 具有变换不变和非局部之间的属性。与图CNN 不同,DGCNN 的图不是固定的,而是在网络的每一层之后动态更新的。即一个点的 k 最近邻居集从一层到一层地改变网络,并从嵌入序列进行计算。DGCNN 可以执行分类和分割任务。分类模型以输入 n 点为特征,EdgeConv 层中每个点的大小 k 边缘功能集,并在每个集内聚合功能,以计算相应的点的 EdgeConv 响应。最后一个 EdgeConv 层的输出功能在全球范围内聚合,以形成 1D 全球描述符,用于生成 cc 类的分类分数。细分模型通过将 1D 全球描述符和每个点的所有 EdgeConv 输出(作为本地描述符)进行配置来扩展分类模型。它输出 p 语义标签的每分分类分数。网络包含两个块:
1) 点云转换块:此块旨在通过应用估计的 3 个× 3 矩阵,将设置的输入点对齐到规范空间。为了估计3个×3个矩阵,使用一个将每个点的坐标和k相邻点之间的坐标差连接在一起的拉伸器。
2) EdgeConv 块:此块以输入形状 n × f 的张力为输入,通过应用带有层神经元数的多层感知器 (MLP) 计算每个点的边缘特征,并在相邻边缘特征之间汇集后生成形状 n ×的张数。DGCNN 架构可以轻松地将原样整合到现有管道中,用于基于点的图形、学习和视觉。
7、总结和定量分析
下表使用评估指标 OA、mIOU 对 3 个公开数据集 S3DIS、语义3D、扫描网 (v2) 和 Sem. KITTI 的结果进行定量分析。

原文链接:3D点云语义分割 — BimAnt
以上是关于基于DNN的3D点云语义分割的主要内容,如果未能解决你的问题,请参考以下文章
三十五.智能驾驶之基于PolarNet的点云语义分割及ROS系统实践
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模
国科大人工智能学院《计算机视觉》课 —三维视觉—三维表达与语义建模