李宏毅2020机器学习深度学习 Seq2seq 作业详解
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅2020机器学习深度学习 Seq2seq 作业详解相关的知识,希望对你有一定的参考价值。
主要对应课程笔记:Conditional Generation by RNN&Attention
项目已上传至github,项目地址
私以为这部分知识,李宏毅老师讲的不是很完美,推荐学习斯坦福cs224n相关课程。
1. 任务描述
英语翻译中文
输入:
一句英文(e.g.,Tom is a student.)
输出:
中文翻译 (e.g. 汤姆 是 个 学生。 )
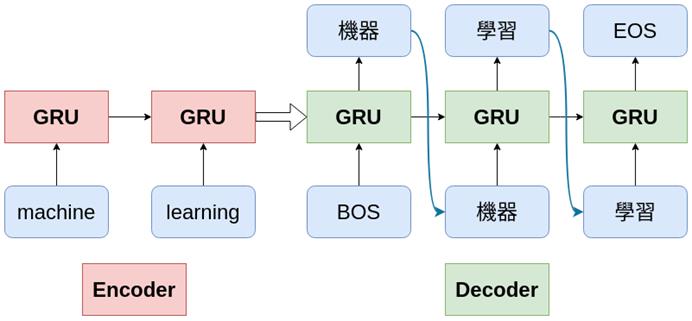
1.1 网络结构
Encoder-Decoder 是一个通用的框架,编码器将现实问题转化为数学问题,解码器求解数学问题,并转化为现实世界的解决方案。
Seq2Seq不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型的范畴。
本作业中要训练一个由GRU组成的Encoder-Decoder结构,完成英翻中的任务。
编码器:3层双向GRU
解码器:3层单向GRU
最大序列长度:50
1.2 数据预处理
使用的数据集为manythings的cmn-eng,是一个较小的机器翻译数据集。
训练数据:18000句
检验数据:500句
测试数据:2636句
格式为:
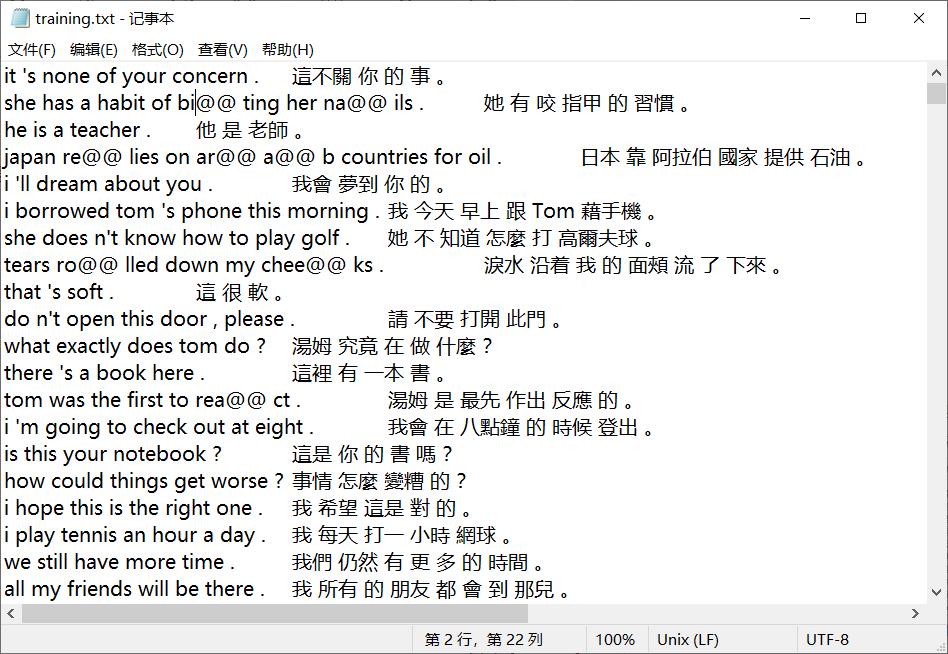
每一行英文和中文之间用TAB(’/t’)分开
字与字之间用空格分开。
1.2.1 英文处理
- 用subword-nmt 组件将word转为subword 建立字典:
- 取出标签中出现频率高于定值的subword
1.2.2 中文处理
- 用jieba将中文句子分词
- 建立字典:取出标签中出现频率高于定值的subword
1.2.3 特殊字符处理
< PAD > :无意义,將句子拓展到相同长度
< BOS > :Begin of sentence
< EOS > :End of sentence
< UNK > :单字没有出现在字典里的字
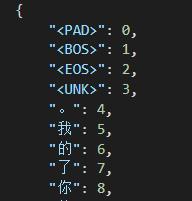
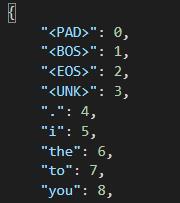
1.2.4 制作look-up table
将字典里每个subword(词)用一个整数表示,分为英文和中文的词典,方便之后转为one-hot vector
如下图所示
2. 必要前置知识
2.1 GRU
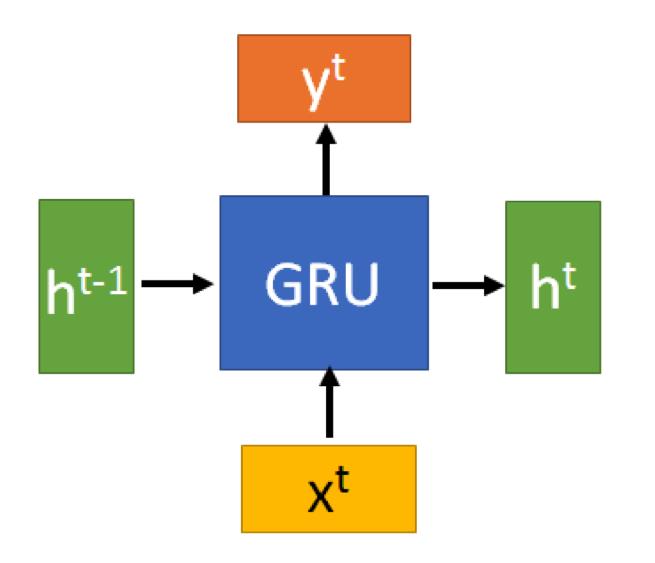
虽然可以这么理解,但是要指出,GRU的输出
y
t
y^t
yt就是
h
t
h^t
ht
还是参考pytorch文档为准
https://pytorch.org/docs/stable/generated/torch.nn.GRU.html#torch.nn.GRU
或者参考一下我这篇博客: GRU
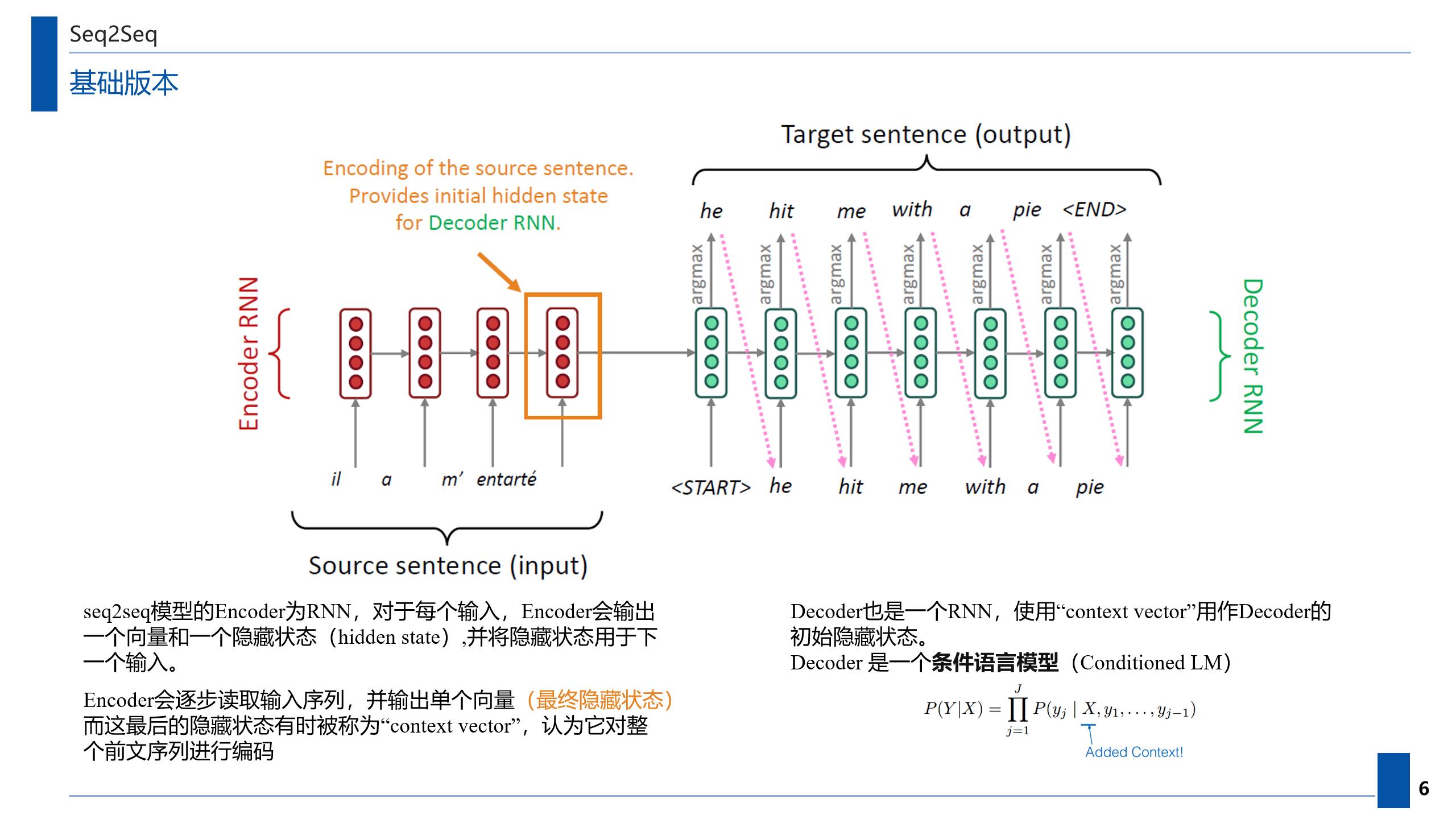
2.2 使用Seq2seq进行机器翻译
这里直接放一张自己做的PPT
2.3 翻译评估指标BLEU
作业提供的示例代码使用了BLEU-1指标,所以计算出来的BLEU值相当高。
有关BLEU的相关知识,请参考我的这篇博客:NLP基础知识点:BLEU
简述计算过程
Precision = 正确字数 / c
c是要计算得句子长度,r是目标句子的长度
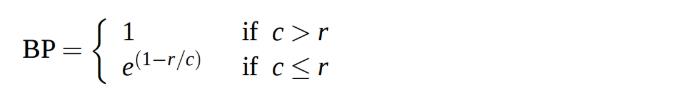
BLEU@1 = BP * Precision
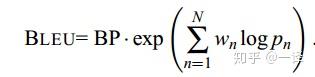

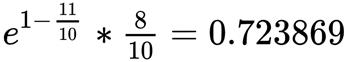
2.4 bidirectional RNN和多层RNN堆叠
示例代码中,编码器使用了双向GRU,因此要特别注意hidder layer的参数量变化。
下面以BiLSTM举例:
参考链接:详解BiLSTM及代码实现
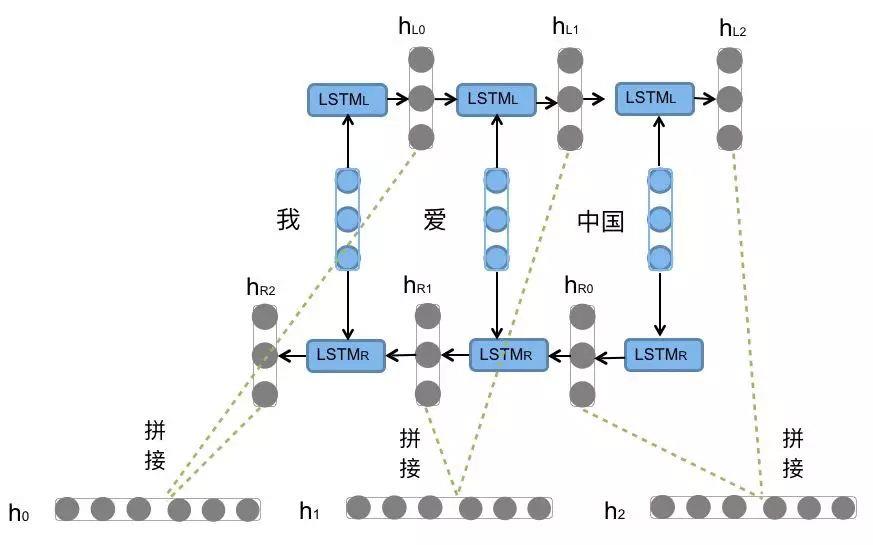
前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码,模型如图所示。

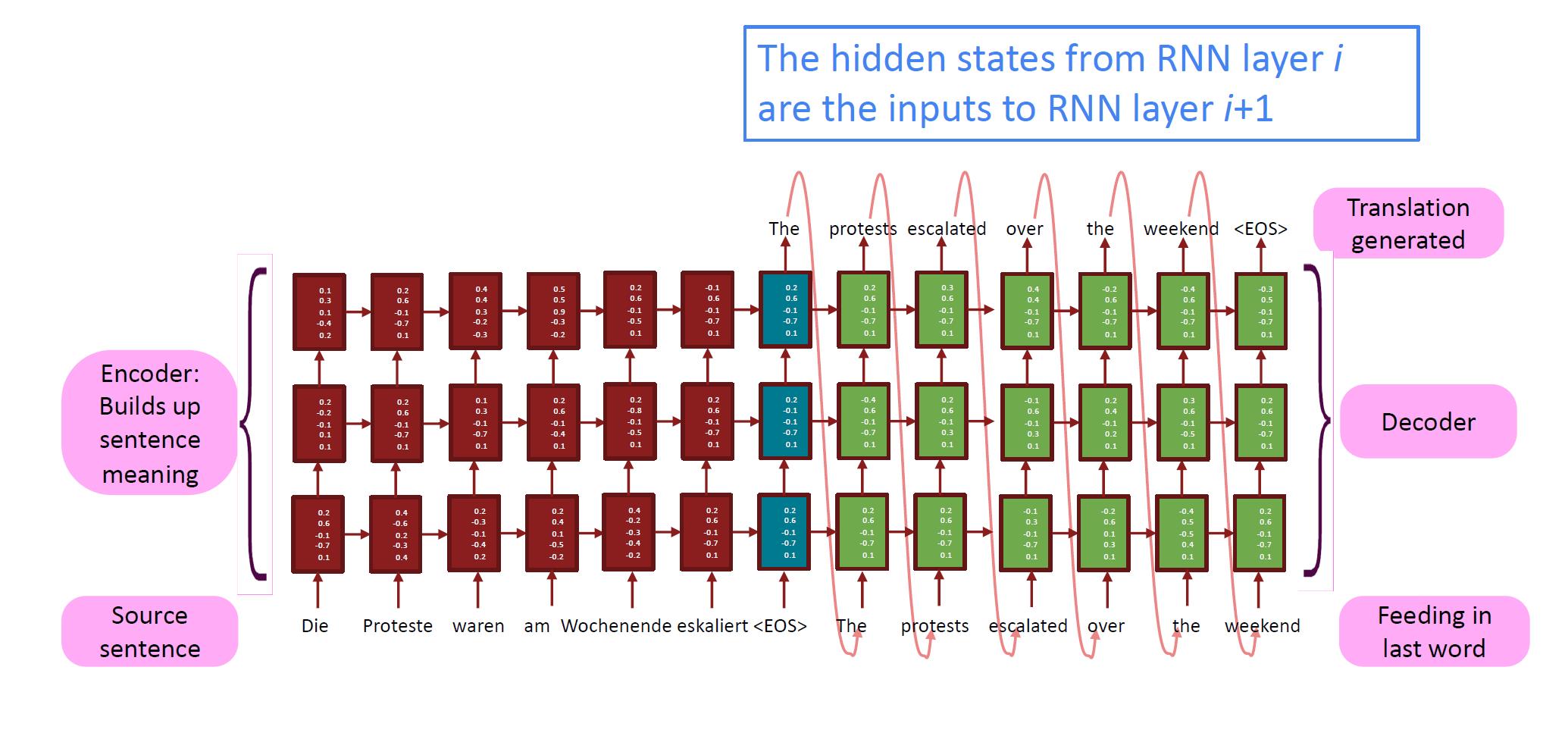
同时要注意,编码器和解码器RNN均是多层的,下图来自cs224n的课件。
我们需要搞清楚多层RNN中,我们使用哪一层的输出。
- Encoder中最上层RNN全部的输出,可以用Attention再进行处理。
- Encoder每层最后的隐藏状态,将传导到Decoder进行解码。
- Decoder中多层RNN最后一层的输出再接入下一个RNN的输入
搞清楚上面这些问题,我们就可以开始来看代码了。
3. 详解代码
这里只介绍跑通示例代码的版本(Hw8_base),自己加了一个Schedule Sampling,但是默认没开启,还是使用teacher forcing。
硬件配置:

如果要在自己的电脑上运行,需要确保自己的显卡足够强劲。
hid_dim=512时直接把2060的6G显存爆了
所以把hid_dim数值砍掉一半,变为256
或者把batch_size设为30。
训练采用teaching force方式
没有使用注意力机制
整个文件结构为
下面对一些重要代码进行解释
(可能敲的有错,以github上的版本为准)
Config.py
此程序存放了整个训练过程所需参数
做测试时,创建configurations实例时要记得设置载入模型的路径
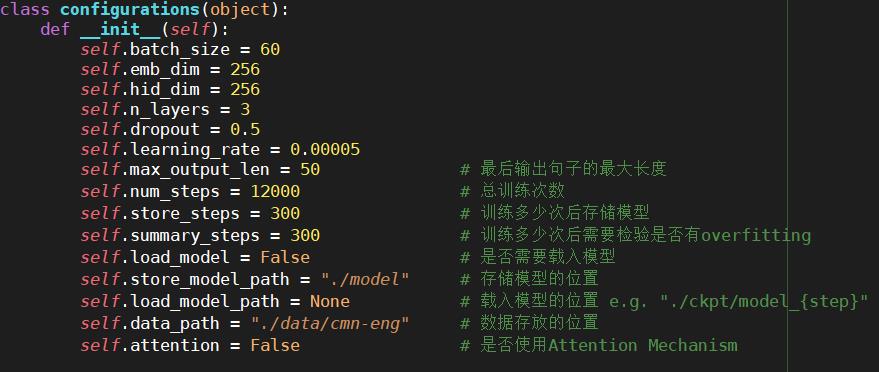
class configurations(object):
def __init__(self):
self.batch_size = 60
self.emb_dim = 256
self.hid_dim = 256
self.n_layers = 3
self.dropout = 0.5
self.learning_rate = 0.00005
self.max_output_len = 50 # 最后输出句子的最大长度
self.num_steps = 12000 # 总训练次数
self.store_steps = 300 # 训练多少次后存储模型
self.summary_steps = 300 # 训练多少次后需要检验是否有overfitting
self.load_model = False # 是否需要载入模型
self.store_model_path = "./model" # 存储模型的位置
self.load_model_path = None # 载入模型的位置 e.g. "./ckpt/model_{step}"
self.data_path = "./data/cmn-eng" # 数据存放的位置
self.attention = False # 是否使用Attention Mechanism
def set_load_model_path(self, load_model_path):
self.load_model_path = load_model_path
LabelTransform.py
这个类负责将不同答案拓展到相同长度,以便训练模型
import numpy as np
Class LabelTransform(object):
def __init__(self, size, pad):
self.size = size # 要把句子序列填充到size大小
self.pad = pad # 用于填充的字符在字典中的index
def __call__(self, label):
label = np.pad(label, (0, (self.size - label.shape[0])),
mode="constant",
constant_values=self.pad)
return label
dataset.py
此程序负责进行数据预处理,组装Dataset
我们要使用的数据是这样的:
- 对于英文,用subword-nmt套件,将word转为subword
建立字典,取出标签中出现频率高于定值的subword - 对于中文,用jieba将中文句子分词
建立字典,取出标签中出现频率高于定值的词
以及定义一些特殊字符
| 字符 | 功能 |
|---|---|
| < PAD > | 无意义,將句子拓展到相同长度 |
| < BOS > | Begin of sentence |
| < EOS > | End of sentence |
| < UNK > | 单字没有出现在字典里的字 |
将字典里每个subword(词)用一个整数表示,分为英文和中文的词典,方便之后转为one-hot向量
处理后的数据:
- 字典:
int2word_.json 将整数转为文字,如int2word_en.json
word2int_.json 将文字转为整数,如word2int_en.json - 训练数据:
不同语言的句子用TAB(’\\t’)分开
字与字之间用空格分开
在将答案传出去之前,在答案开头加入< BOS >,在答案结尾加入< EOS >符号
以上都已经被处理好了,解压数据集即可得到
import re
import json
import os
from LabelTransform import LabelTransform
import numpy as np
import torch
import torch.utils.data as data
class EN2CNDataset(data.Dataset):
# root为数据根目录
# max_output_len为输出句子的最大长度
# set_name为载入数据的名称
def __init__(self, root, max_output_len, set_name):
self.root = root
self.word2int_cn, self.int2word_cn = self.get_dictionary('cn')
self.word2int_en, self.int2word_en = self.get_dictionary('en')
# 载入数据
self.data = []
with open(os.path.join(self.root, f'{set_name}.txt'), "r", encoding='UTF-8') as f:
for line in f:
self.data.append(line)
print(f'{set_name} dataset size: {len(self.data)}')
self.cn_vocab_size = len(self.word2int_cn) # 中文词表大小
self.en_vocab_size = len(self.word2int_en) # 英文词表大小
# 创建一个LabelTransform的实例
# 用<PAD>对应的整数作填充
self.transform = LabelTransform(max_output_len, self.word2int_en['<PAD>'])
# 载入字典
def get_dictionary(self, language):
with open(os.path.join(self.root, f'word2int_{language}.json'), "r", encoding='UTF-8') as f:
word2int = json.load(f)
with open(os.path.join(self.root, f'int2word_{language}.json'), "r", encoding='UTF-8') as f:
int2word = json.load(f)
return word2int, int2word # 返回的是两个dict
def __len__(self):
return len(self.data)
# 处理每一行数据
def __getitem__(self, Index):
# 先将中英文分开
sentences = self.data[Index]
sentences = re.split('[\\t\\n]', sentences)
sentences = list(filter(None, sentences))
assert len(sentences) == 2
# 预备特殊字符
BOS = self.word2int_en['<BOS>']
EOS = self.word2int_en['<EOS>']
UNK = self.word2int_en['<UNK>']
# 在开头添加<BOS>,在结尾添加<EOS>,不在字典中的subword(词)用<UNK>取代
# 初始化代表英文与中文的index序列
en, cn = [BOS], [BOS]
# 将英文句子拆解为subword并转为整数
# e.g. < BOS >, we, are, friends, < EOS > --> 1, 28, 29, 205, 2
sentence = re.split(' ', sentences[0])
sentence = list(filter(None, sentence))
for word in sentence:
en.append(self.word2int_en.get(word, UNK))
en.append(EOS)
# 将中文句子拆解为单词并转为整数
sentence = re.split(' ', sentences[1])
sentence = list(filter(None, sentence))
for word in sentence:
cn.append(self.word2int_cn.get(word, UNK))
cn.append(EOS)
en, cn = np.asarray(en), np.asarray(cn)
# 用<PAD>将句子补到相同长度
en, cn = self.transform(en), self.transform(cn)
en, cn = torch.LongTensor(en), torch.LongTensor(cn)
return en, cn
utils.py
主要存放了一些工具函数,注释已经写的很清楚了,这里只说明一个。
训练流程中会调用build_model函数构造一个model
创建一个encoder类的实例,创建一个decoder类的实例,再将其作为参数传入一个Seq2Seq类的实例model。
# 构建模型
def build_model(config, en_vocab_size, cn_vocab_size):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
encoder = Encoder(en_vocab_size, config.emb_dim, config.hid_dim, config.n_layers, config.dropout)
decoder = Decoder(cn_vocab_size, config.emb_dim, config.hid_dim, config.n_layers, config.dropout, config.attention)
model = Seq2Seq(encoder, decoder, device)
print(model)
# 构建 optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
print(optimizer)
if config.load_model_path:
model = load_model(model, config.load_model_path)
model = model.to(device)
return model, optimizer
model.py
整个作业的重中之重,Seq2Seq的原理,注意力的计算基本都在这部分
Encoder
seq2seq模型的编码器为RNN。
对于每个输入,RNN会输出一个向量和一个隐藏状态(hidden state),并将隐藏状态用于下一个输入。
Encoder会逐步读取输入序列,并输出单个向量(最终隐藏状态)。
参数:
- en_vocab_size是英文词典的大小,也就是英文的subword的个数
- emb_dim是embedding的维度,将one-hot的单词向量压缩到指定的维度
- 可以使用预先训练好的word embedding,如Glove和word2vector(设置
self.embeddings.weight.requires_grad = False) - hid_dim是RNN输出和隐藏状态的维度
- n_layers是RNN要叠多少层
- dropout是决定有大多的几率将某个节点变为0,主要是防止overfitting,一般在训练时使用,测试时不使用
Encoder的输入和输出: - 输入:英文的整数序列,例如:1,28,29,205,2
- 输出:outputs:最上层RNN全部的输出,可以用Attention再进行处理;hidden:每层最后的隐藏状态,将传导到Decoder进行解码
class Encoder(nn.Module):
def __init__(self, en_vocab_size, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
# nn.Embedding进行默认随机赋值
# 参数1:num_embeddings (int) – size of the dictionary of embeddings
# 参数2:embedding_dim (int) – the size of each embedding vector
self.embedding = nn.Embedding(en_vocab_size, emb_dim)
self.hid_dim = hid_dim
self.n_layers = n_layers
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers,
dropout=dropout, batch_first=True, bidirectional=True)
self.dropout = nn.Dropout(dropout)
def forward(self, input):
# input = [batch size, sequence len]
# 每个元素为一个int,取值在[1, en_vocab_size]
# 注意nn.embedding的输入只能是编号!这里的注释有迷惑性!
embedding = self.embedding(input)
outputs, hidden = self.rnn(self.dropout(embedding))
# outputs = [batch size, sequence len, hid dim * directions]
# hidden = [num_layers * directions, batch size , hid dim]
# outputs 是最上层RNN的输出
return outputs, hidden
Decoder
Decoder是另一个RNN,在最简单的seq2seq decoder中,仅使用Encoder每一层最后的隐藏状态进行解码
而这最后的隐藏状态有时被称为"content vector",因为可以想象它对整个前文序列进行编码
此"content vector"用作Decoder的初始隐藏状态
而Encoder的输出通常用于注意力机制计算
参数:
- en_vocab_size是英文词典的大小,也就是英文的subword的个数
- emb_dim是embedding的维度,将one-hot的单词向量压缩到指定的维度,可以使用预先训练好的word embedding,如Glove和word2vector
- hid_dim是RNN输出和隐藏状态的维度
- output_dim是最终输出的维度,一般是将hid_dim转到one-hot vector的单词向量
- n_layers是RNN要叠多少层
- isatt是决定是否使用注意力机制
Decoder的输入和输出: - 输入:前一次解码出来的单词的整数表示
- 输出:hidden: 根据输入和前一次的隐藏状态,现在的隐藏状态更新的结果;output: 每个字有多少概率是这次解码的结果
class Decoder(nn.Module):
def __init__(self, cn_vocab_size, emb_dim, hid_dim, n_layers, dropout, isatt):
super().__init__()
self.cn_vocab_size = cn_vocab_size
# 因为Encoder采用双向GRU
self.hid_dim = hid_dim * 2
self.n_layers = n_layers
self.embedding = nn.Embedding(cn_vocab_size, emb_dim)
self.isatt = isatt
self.attention = Attention(hid_dim)
# 如果使用 Attention Mechanism 會使得輸入維度變化,請在這裡修改
if isatt:
# e.g. Attention 接在输入后面会使维度变化,所以输入维度改为
self.input_dim = emb_dim + hid_dim * 2
else:
self.input_dim = emb_dim
# 这里提前知不知道翻译结果,不能双向注意力流
self.rnn = nn.GRU(self.input_dim, self.hid_dim,
self.n_layers, dropout=dropout, batch_first=True)
self.embedding2vocab1 = nn.Linear(self.hid_dim, self.hid_dim * 2)
self.embedding2vocab2 = nn.Linear(self.hid_dim * 2, self.hid_dim * 4)
self.embedding2vocab3 = nn.Linear(self.hid_dim * 4, self.cn_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size, vocab size]
# hidden = [batch size, n layers * directions, hid dim]
# Encoder的输出:outputs = [batch size, sequence len, hid dim * directions]
# Decoder 只会是单向,所以 directions=1
input = input.unsqueeze(1) # [batch size,1,vocab size ]
embedded = self.dropout(self.embedding(input)) # [batch_size,1, emb_dim]
if self.isatt:
# encoder_outputs:最上层RNN全部的输出,可以用Attention再进行处理
attn = self.attention(encoder_outputs, hidden)
# TODO: 在這裡決定如何使用 Attention,e.g. 相加 或是 接在後面, 請注意維度變化
output, hidden = self.rnn(embedded, hidden)
# output = [batch size, 1, hid dim]
# hidden = [num_layers, batch size, hid dim]
# 将RNN的输出转为每个词的输出概率
# 相当于通过连接一个前馈神经网络,实现词表大小的多分类器
output = self.embedding2vocab1(output.squeeze(1))
output = self.embedding2vocab2(output)
prediction = self.embedding2vocab3(output)
# prediction = [batch size, vocab size]
return prediction, hidden
Seq2Seq
Seq2Seq由Encoder和Decoder组成
在训练中,接受输入并传给Encoder,再将Encoder的输出传给Decoder,不断地将Decoder的输出传回Decoder,进行解码。
最终当解码完成后,将Decoder的输出传回。
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.n_layers == decoder.n_layers, \\
"Encoder and decoder must have equal number of layers!"
def forward(self, input, target, teacher_forcing_ratio):
# input = [batch size, input len, vocab size]
# target = [batch size, target len, vocab size]
# teacher_forcing_ratio 有多少几率使用正确数据来训练
batch_size = target.shape[0] # 和config中相同,为30
target_len = target.shape[1] # 和config中相同,为50
vocab_size = self.decoder.cn_vocab_size
# 準備一個儲存空間來儲存輸出
outputs = torch.zeros(batch_size, target_len,
vocab_size).to(self.device)
# 將輸入放入 Encoder
encoder_outputs, hidden = self.encoder(input)
# Encoder最后的隐藏层(hidden state)用来初始化Decoder
# encoder_outputs 主要是使用在 Attention
# 因为Encoder是双向的RNN,所以需要将同一层两个方向的hidden state接在一起
# .view()用来做reshape
# hidden = [num_layers * directions, batch size , hid dim] --> [num_layers, directions, batch size , hid dim]
hidden = hidden.view(self.encoder.n_layers, 2, batch_size, -1)
# 取切片降一维,拼成[num_layers, batch size ,hid dim*2]
hidden = torch.cat((hidden[:, -2, :, :], hidden[:, -1, :, :]), dim=2)
# 取得 <BOS> token作为第一个输入
input = target[:, 0]
preds = []
for t in range(1, target_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
# output:[batch size, vocab size]
outputs[:, t] = output
# 决定是否用正确答案来做训练
teacher_force = random.random() <= teacher_forcing_ratio
# 取出概率最大的单词(batch_size大小)
top1 = output.argmax(1)
# 如果是 teacher forc以上是关于李宏毅2020机器学习深度学习 Seq2seq 作业详解的主要内容,如果未能解决你的问题,请参考以下文章