李宏毅《机器学习》丨4. Deep Learning(深度学习)
Posted AXYZdong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅《机器学习》丨4. Deep Learning(深度学习)相关的知识,希望对你有一定的参考价值。
Author:AXYZdong
李宏毅《机器学习》系列
参考视频地址:https://www.bilibili.com/video/BV1Ht411g7Ef
参考文档:DataWhale文档
文章目录
一、深度学习发展历史
- 1958: Perceptron (linear model)
- 1969: Perceptron has limitation
- 1980s: Multi-layer perceptron
Do not have significant difference from DNN today - 1986: Backpropagation
Usually more than 3 hidden layers is not helpful - 1989: 1 hidden layer is “good enough”, why deep?
- 2006: RBM initialization (breakthrough)
- 2009: GPU
- 2011: Start to be popular in speech recognition
- 2012: win ILSVRC image competition
二、深度学习三个步骤
2.1 Step1:神经网络(Neural network)
以神经元(neuron)为基本单位,通过神经元之间的互相连接,建立神经网络。
神经元之间有很多不同的连接方式,这样就会产生不同的结构(structure)。
- 完全连接前馈神经网络:相邻层神经元之间都有连接,而且传递的方向是由后往前传。
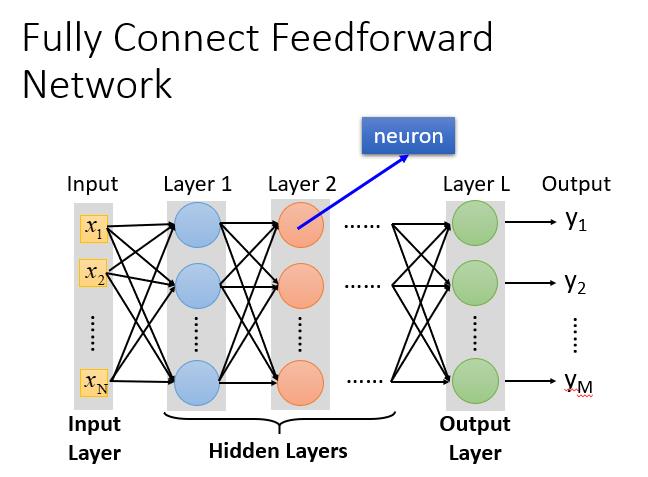
深度(Deep)的理解
Deep = Many hidden layer
- 2012 AlexNet:8层
- 2014 VGG:19层
- 2014 GoogleNet:22层
- 2015 Residual Net:152层
- 101 Taipei:101层

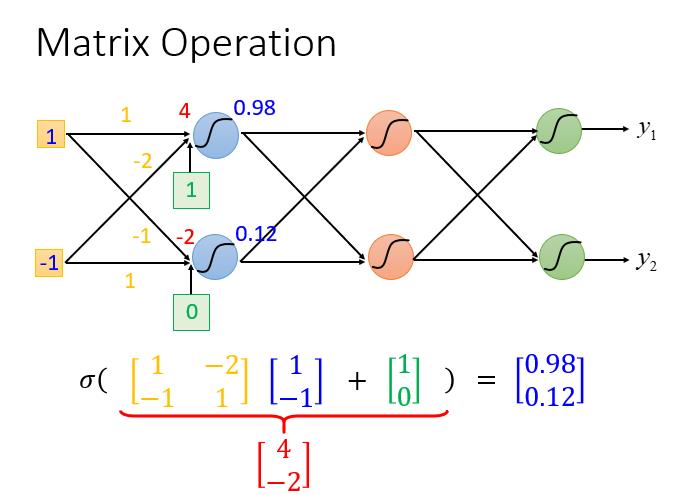
矩阵计算(Matrix Operation)
随着层数变多,错误率降低,随之运算量增大,通常都是超过亿万级的计算。对于这样复杂的结构,我们一定不会一个一个的计算,对于亿万级的计算,使用loop循环效率很低。因此,利用矩阵计算(Matrix Operation)提高运算的速度以及效率。
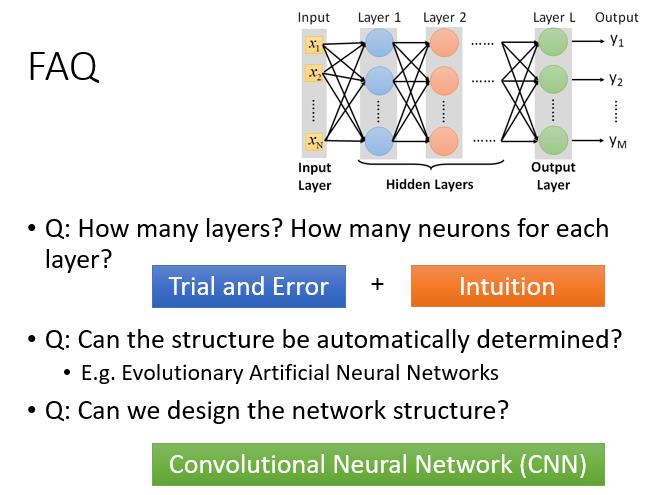
FAQ(Frequently Asked Questions)
- 多少层? 每层有多少神经元?
- 结构可以自动确定吗?
- 我们可以设计网络结构吗?
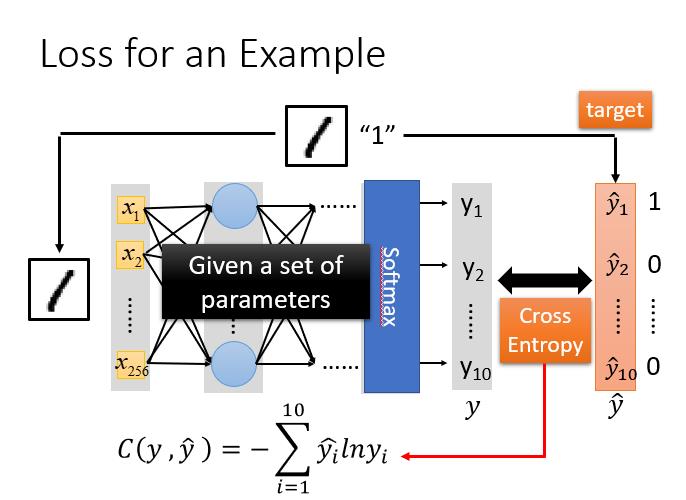
2.2 Step2:模型评估(Goodness of function)
对于模型的评估,我们一般采用损失函数来反应模型的好差,所以对于神经网络来说,我们采用交叉熵(cross entropy)函数来对损失进行计算,通过调整参数,让交叉熵误差越来越小。
2.3 Step3:选择最优函数(Pick best function)
-
梯度下降(Gradient Descent): 李宏毅《机器学习》丨3. Gradient Descent(梯度下降)
-
反向传播(Backpropagation):BP(Back Propagation)神经网络——原理篇
三、深度学习思考
为什么要用深度学习,深层架构带来哪些好处?那是不是隐藏层越多越好?


四、总结
Datawhale组队学习,李宏毅《机器学习》Task4. Deep Learning(深度学习)。主要包括深度学习发展历史、深度学习三个步骤:神经网络 模型评估 选择最优函数、深度学习思考。
如果以上内容有任何错误或者不准确的地方,欢迎在下面 👇 留言。或者你有更好的想法,欢迎一起交流学习~~~
更多精彩内容请前往 AXYZdong的博客
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于李宏毅《机器学习》丨4. Deep Learning(深度学习)的主要内容,如果未能解决你的问题,请参考以下文章