李宏毅2020机器学习深度学习笔记1+2 &&深度学习基础与实践课程笔记2
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅2020机器学习深度学习笔记1+2 &&深度学习基础与实践课程笔记2相关的知识,希望对你有一定的参考价值。
机器学习:研究如何从观测数据 (observations) 中寻找“规律”(skill),这些规律可以在未知数据上的表现有所改进。
目的:使用“高质量”的训练数据,构建“合适”的模型,以“更佳地”完成任务。
本质:让机器自动帮人类找函数。
历史:早期称为模式识别,当时更偏向于具体的应用任务,比如字符识别、语音识别。
寻找最优函数的过程称为学习或者训练。
应用:分类、聚类、回归、关系预测、目标检测、语义分割、机器翻译、生成……
分类:判断/创造

方法:1.定义模型 2.定义损失函数 3.转化为优化问题 4.开始train
————
李宏毅课程笔记1
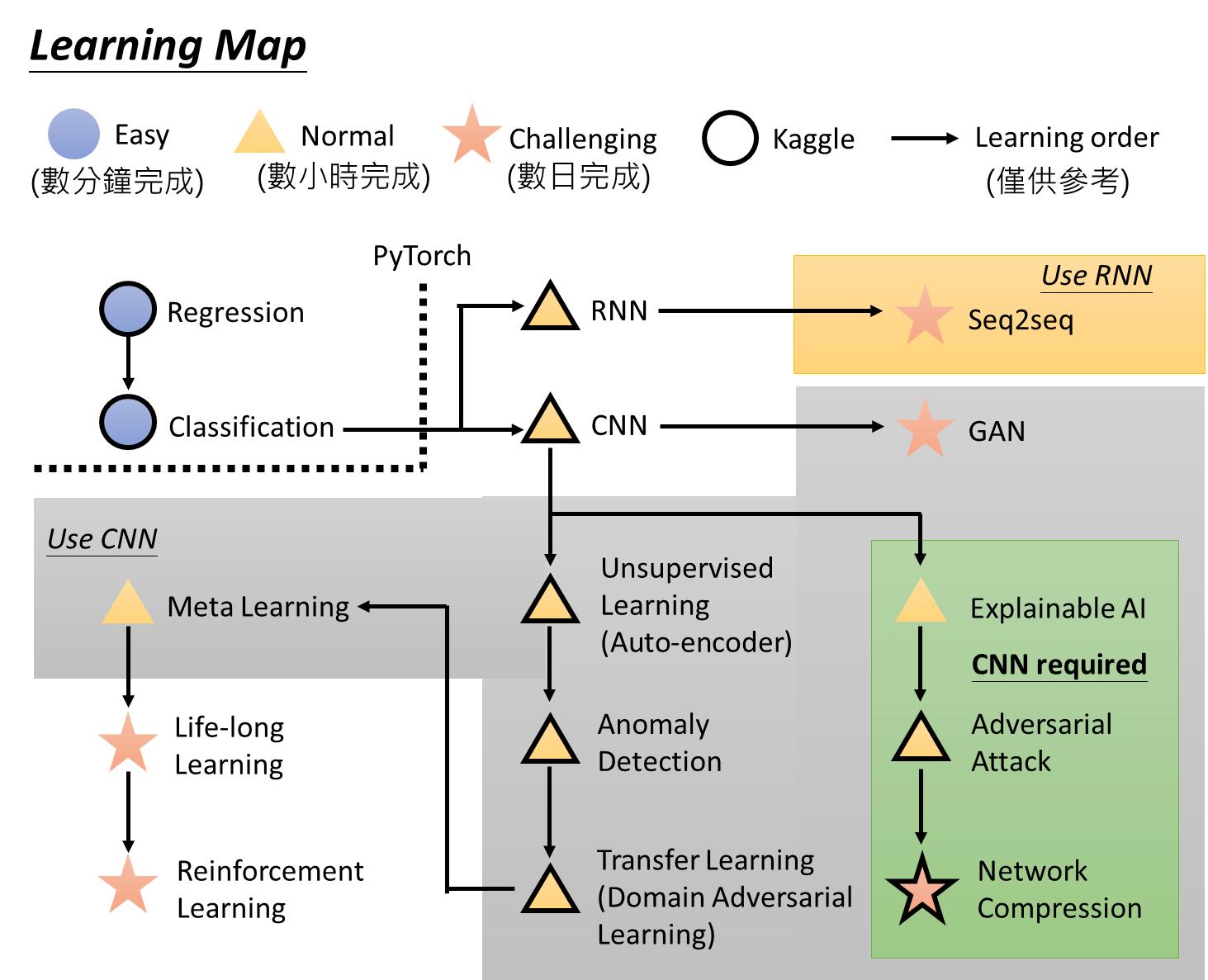
supervised learning:提前想好想让电脑输出什么类型的函数-需要给电脑一些训练数据集和训练结果(是猫还是狗)
reinforcement learning:不直接给结果而是给部分(不直接告诉机器下一步下到哪里,而是以下很多盘的不同结果来作为训练数据)【AlphaGo最早是先supervised再RL】
unsupervised learning:只有数据没有结果
explanable AI:不仅要知道输出“是猫”,还要输出“为什么是”
Adversarial Attack:怎样给予一个可能肉眼无法识别的attack使得网络识别出故障
Network compression:怎样让网络在手机、甚至更小的载体上运行
anomaly detection:怎么知道不知道这个东西
domain adversary:怎样在domain变化之后保持学习能力(甲方给换了背景hhh)
Meta learning:如何让机器自己学习假设一个模型让机器自己跑(functional)
2:regression:
假设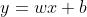 →loss function:
→loss function: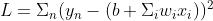
以宝可梦为例,本来只考虑种类,然后考虑高度、层级……;本来只考虑一次函数,然后二次、三次……机器学习炼丹开始hhhh
改进思路
Regulation:
目的:让参数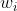 们尽量小,从而让函数更加平滑,因变量对自变量不敏感,从而小error不太影响……奥卡姆剃刀原理。
们尽量小,从而让函数更加平滑,因变量对自变量不敏感,从而小error不太影响……奥卡姆剃刀原理。
Note:在实际过程中不考虑b这个bias的,因为我们更关心函数的平滑程度
----------
error来源:bias & variance(用于优化算法)
无偏估计:E=\\miu
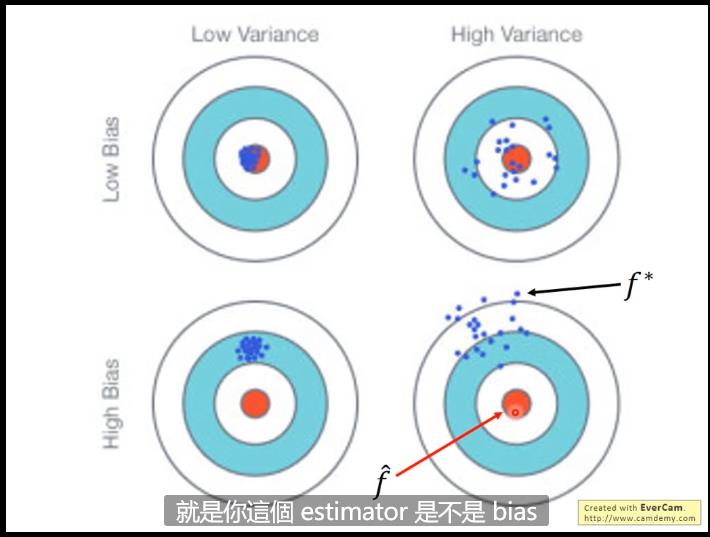

因为越简单的model越不依赖于data,最极端的情况就是constant的model直接与data无关。
正常来说,简单的model可能(由于对data依赖性低)variance较小,但是由于model简单bias大(underfitting),复杂的model均值来看可能比较符合但是variance会大(over fitting)
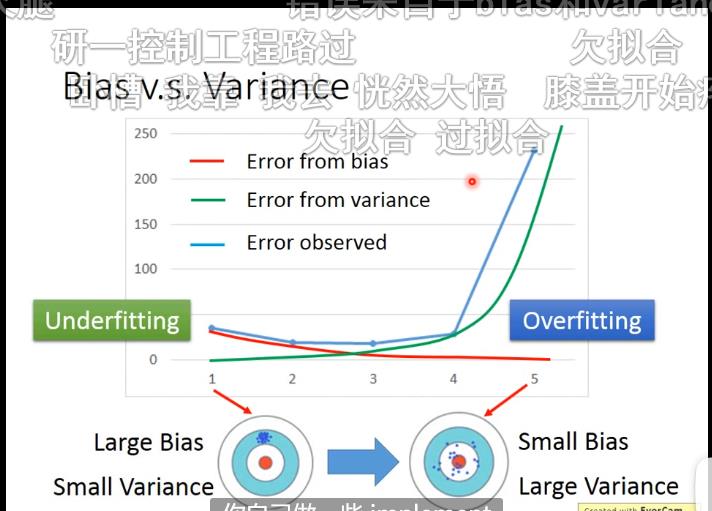 如果出现预测的函数与实际函数偏差较大的话,我们认为出现了under fitting的情况,这种情况下我们考虑redesign这个model;如果模型在训练集上的error很小但是在验证集上error很大,那么很有可能出现了over fitting的情况,这时候我们可以考虑
如果出现预测的函数与实际函数偏差较大的话,我们认为出现了under fitting的情况,这种情况下我们考虑redesign这个model;如果模型在训练集上的error很小但是在验证集上error很大,那么很有可能出现了over fitting的情况,这时候我们可以考虑
1.增加训练集:这个是万灵丹,无论什么问题增加训练集都可以缓解,但是实际上可能很难,。因此码农们考虑自己生成训练集:字符识别的考虑转向、图像识别的考虑镜像对称一下、语音识别的考虑机翻……
2.regularization:加一个term,在前面有weight---表示你希望你的函数有多么平滑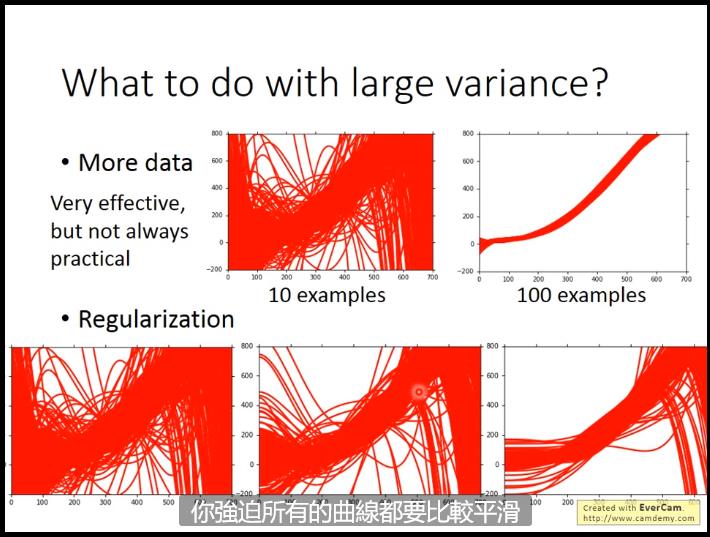
但是可能伤害bias(可能导致target不包含在set里),因此需要调整weight。
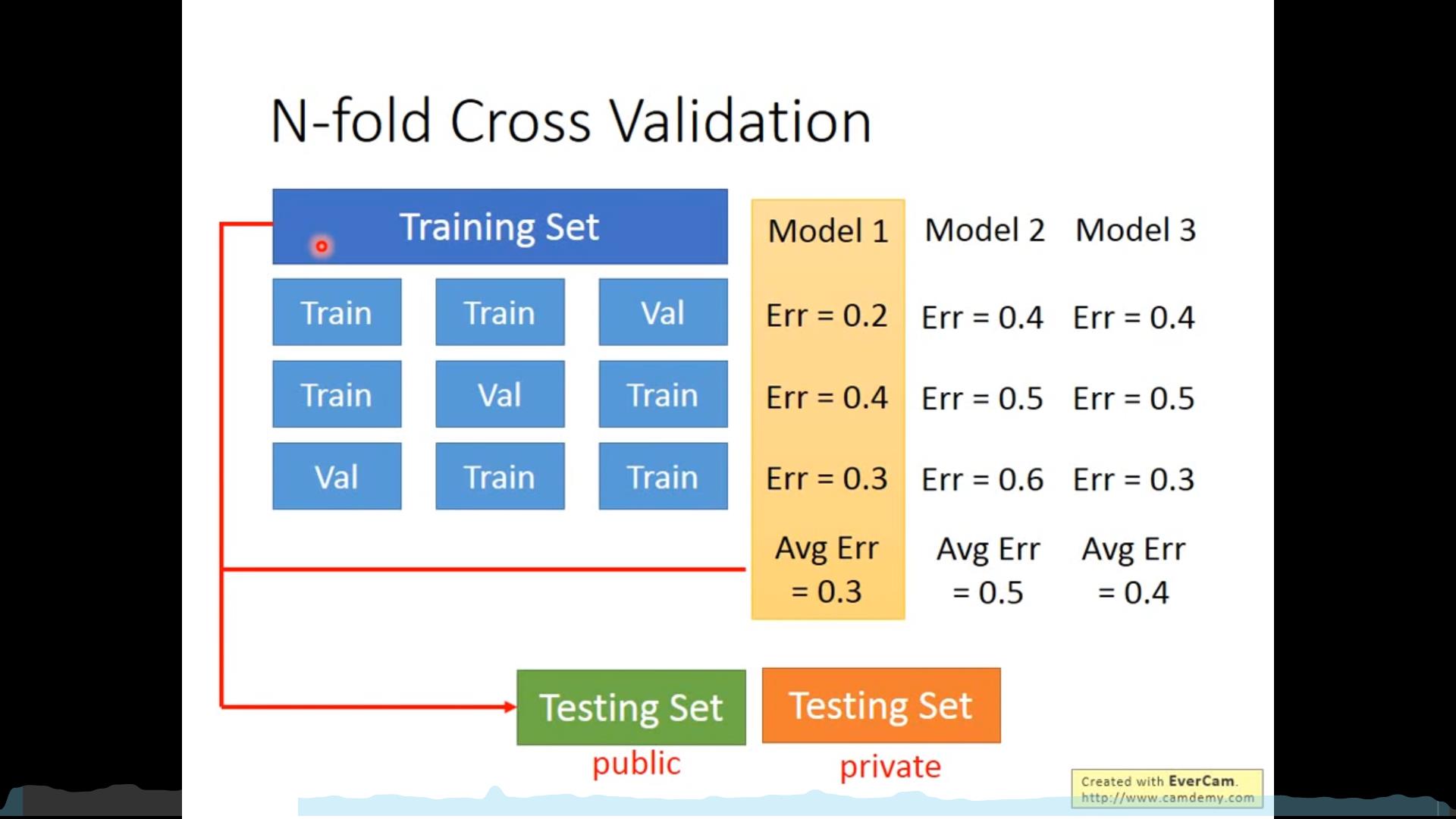
训练集、测试集和验证集

优化:
以上是关于李宏毅2020机器学习深度学习笔记1+2 &&深度学习基础与实践课程笔记2的主要内容,如果未能解决你的问题,请参考以下文章