深度学习李宏毅《机器学习》学习笔记
Posted 晓乐丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习李宏毅《机器学习》学习笔记相关的知识,希望对你有一定的参考价值。
【深度学习】李宏毅《机器学习》学习笔记
2021年8月16日
P1-P2节-机器学习介绍和为什么要学习机器学习
1950年,人工智能就出现了好厉害~~

机器学习中包含了深度学习。
早期的人工智能其实都是想当于给河狸装上一个先天的本能,并且这个是永远无法超越创造者的。
我们要做的其实是让机器他有自己学习的能力,也就我们要做的应该machine learning的方向。讲的比较拟人化一点,所谓machine learning的方向,就是你就写段程序,然后让机器人变得了很聪明,他就能够有学习的能力。接下来,你就像教一个婴儿、教一个小孩一样的教他,你并不是写程序让他做到这件事,你是写程序让它具有学习的能力。然后接下来,你就可以用像教小孩的方式告诉它。假设你要叫他学会做语音辨识,你就告诉它这段声音是“Hi”,这段声音就是“How are you”,这段声音是“Good bye”。希望接下来它就学会了,你给它一个新的声音,它就可以帮你产生语音辨识的结果。
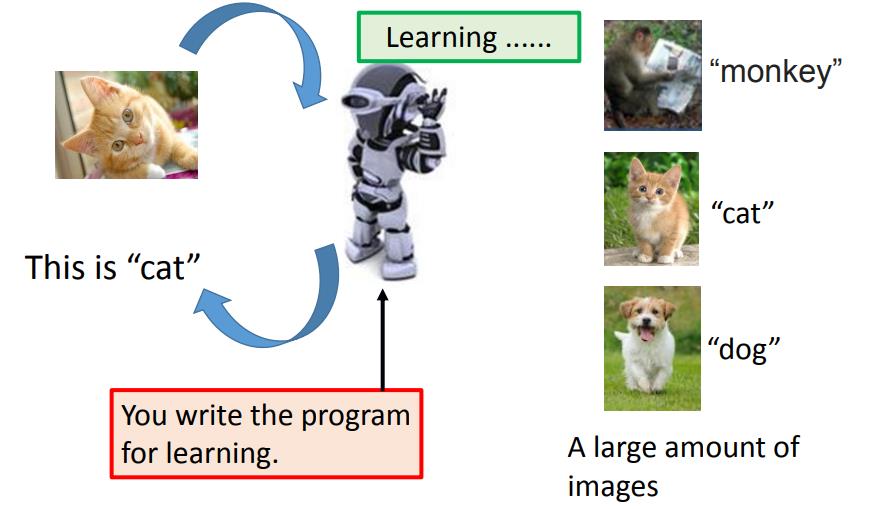
你只是需要交换下告诉它:看到这张图片,你要说这是猴子;看到这张图片,然后说是猫;看到这张图片,可以说是狗。它具有影像辨识的能力,接下来看到它之前没有看过的猫,希望它可以认识。
机器学习相当于寻找一个function,让机器具有一个能力。
机器学习相关的技术
主要包括监督学习、半监督学习、迁移学习、无监督学习、监督学习中单结构化学习、强化学习
监督学习
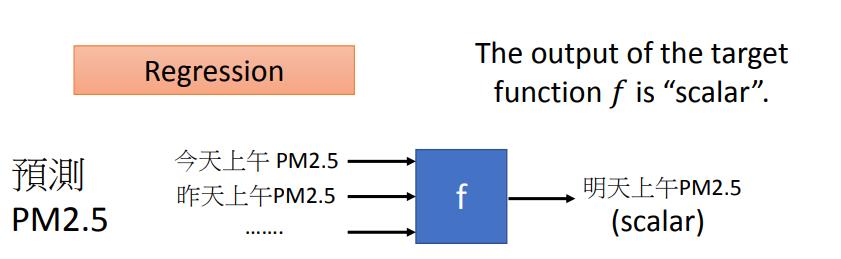
相当于我们告诉他过去的PM2.5资料是什么,让他去预测未来新的PM2.5的资料。output往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,这些function的output叫做label。
分类问题
这里说的是需要让机器做选择,一个是二分类,一个是多分类。这里还有一个模型选择,就是是否是线性的或者非线性的,比如线性最简单的就是线性回归,。深度学习大部分是非线性的 ,机器学习中SVM支持向量机也是非线性的。
半监督学习
其实就是少量有标记的数据,大部分是未标记的数据。让机器自己去识别,这里老师说这个可能没有标记的数据可能会对机器学习的学习过程有帮助,说后面会说。
迁移学习
假设我们要做猫和狗的分类问题,我们也一样,只有少量的有label的data。但是我们现在有大量的data,这些大量的data中可能有label也可能没有label。但是他跟我们现在要考虑的问题是没有什么特别的关系的,我们要分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片(凉宫春日,御坂美琴)你有这一大堆不相干的图片,它到底可以带来什么帮助。这个就是迁移学习要讲的问题。
无监督学习
通俗,就是没有任何标记的数据下,让机器自己学习。
监督学习中的结构化学习
很多教科书说,机器学习只有分类和回归问题,其实还有大量的结构化学习,没有探究问题。
强化学习
原来Alpha GO就是强化学习的产物啊。
P2为什么要学机器学习
再厉害的AI也需要一个AI训练师提供可靠的模型和损失函数。冲冲冲!~~
学习笔记出处:
开源bijidatawhale:
麻烦大家一键三连~~
本次组队队伍名称:时空跳跃的节点
感谢Datawhale开源社区
以上是关于深度学习李宏毅《机器学习》学习笔记的主要内容,如果未能解决你的问题,请参考以下文章