SignAll SDK:基于 MediaPipe 的手语接口现已开放
Posted 谷歌开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SignAll SDK:基于 MediaPipe 的手语接口现已开放相关的知识,希望对你有一定的参考价值。

客座博文 / 由 SignAll 与 MediaPipe 团队联合完成。请注意,以下内容中的信息、用途及应用场景完全来自 SignAll 客座作者的观点。
SignAll SDK
当 Google 发布第一个基于 MediaPipe 的设备端手部追踪技术时,它便成为了开发者构建手语识别解决方案应用的基础。Google 之后对这个手部跟踪解决方案的进一步更新,将其准确率提升至其他技术所无法达到的水平(图 1)。

图 1 随着时间推移,MediaPipe 的改进:较早版本(2020 年 2 月 10 日)和最新版本(2020 年 12 月 16 日)的手部骨架追踪输出。这种手形经常在手语中使用,但由于缺少表示法的训练数据集而经常被遗漏
SignAll 是一家研发手语翻译技术的初创公司。该公司的使命是为失聪人士普及手语翻译,让他们能够与听力正常的人群以及计算机进行交流。SignAll 的产品采用了复杂的多摄像头设置和带有彩色标记的手套,广泛用于美国的通信和教育领域。虽然手语的复杂性不仅限于手形(还包括面部特征、肢体、语法等),但准确追踪手部确实已经给预处理程序(即计算机视觉)造成了巨大阻碍。MediaPipe 为 SignAll 的解决方案提供了更多可能性,不仅能够免除手套,还可以使用单摄像头设置。SignAll 已经宣布针对此类型开放首版 SDK,所以开发者现在能够在自己的应用中启用手语输入。
SignAll
https://www.signall.us/首版 SDK
https://signall.us/sdk
近期,该公司在 App Store 上发布了一个互动式教育应用,该应用可以让用户通过即时反馈来练习手语,还能够展现出 SDK 的潜力。
SignAll 与 MediaPipe Hands
我们的系统在手语识别方面采用多个数据层,各层数据的抽象性越来越高。低级数据层从 2D 和 3D 摄像头中提取关键的手部、躯体和面部数据。在我们的第一个实现中,此数据层会检测手套的颜色,并创建 3D 手部数据。将其替换为 MediaPipe Hands(MediaPipe Pose 和 MediaPipe Face Mesh 作为补充)具有颠覆性的重要意义,因为你不再需要手套或特殊光线来使用我们的系统。
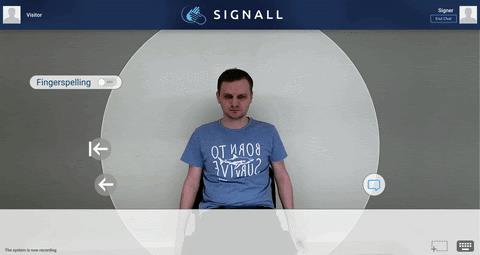

图 2 使用 MediaPipe 开发的 SignAll SDK 的演示
如上文所述,我们使用了多个带有深度传感器的摄像头,并在实际中对这些传感器进行了校准。相较于本地摄像头或张量空间,这种方法能够实现更加准确的 3D 世界空间探测,但每个摄像头都需要进行手部特征点检测。摄像头的位置和屏幕方向各不相同,因此可以实现更高的手部可视频率,因为从一个摄像头的角度来看,手部可能会被另外一只手遮挡,但从另一个摄像头的角度来看,可能并不存在遮挡。

图 3 在三个摄像头的基础上纠正 3D 手形。由于其镜头方向的特殊性,正前方的摄像头检测有误,但侧面的摄像头能够纠正结果
接下来的步骤是过滤数据,并进行数据平滑处理,以复制彩色手套标记提供的精确测量值。虽然 SignAll 的标记与 MediaPipe 提供的界标不同,但我们使用了手部模型并根据界标生成彩色标记。因此,新的动作捕捉数据与之前的数据完全兼容。
虽然我们主要关注手部,但我们同时整合了 MediaPipe Pose 和 MediaPipe Face Mesh。即便在彼此接触,或距离很近的情况下,姿态界标都能提供准确的手部姿态信息。
虽然这两个版本的动作捕捉是兼容的,但工件的性质不同:一种是直接测量各个标记,另一种是根据全局检测的手部模拟标记。因为存在差异,所以我们必须在更高层级对参数进行优化。另一方面,我们仍可以利用我们的大型手语数据库来进行无手套配置。我们可以通过替换低级数据,优化高级数据,以无手套形式测试我们的系统。实现无手套化,对于手语识别技术的全球推广具有重要意义。

图 4 不同低级追踪的兼容动作捕捉的演示:右图是无手套的情况,左图是有手套的情况。因为具有这种兼容性,所以我们能够利用 SignAll 精心标记的 300000 多个手语视频数据集,在不同低级数据的基础上训练识别模型
使用 MediaPipe 框架的 SignAll 系统
将 MediaPipe Hands 整合至系统后,我们还希望能够利用 MediaPipe 框架在多个平台上提供的自定义和扩容机会。这样我们不仅可以用 Python 原型化我们的状态研究方法,而且还可以为 Windows、ios、android 甚至 Web 提供最终用户解决方案。由于我们的模块图系统和 MediaPipe 的计算图之间具有相似性,现有的处理单元只需稍作修改就可以在这个新框架中重用。尽管如此,扩展平台组还面临着其他挑战,例如在大多数情况下我们只能使用单个 2D 摄像头而不是经过校准的多摄像头系统。
我们开发并使用的模型、算法和技术,主要是为了在 3D 全局世界中处理动作捕捉数据。毫无疑问,从单摄像头设置中提取的数据达不到同样的详细程度。所以我们必须对实现进行一些调整,微调算法并添加一些额外逻辑(例如,动态适应手持摄像头用例导致的空间变化)。幸运的是,MediaPipe 框架让我们能够用 C ++ 实现核心处理单元,因此我们仍然可以从先前开发的运行时优化核心解决方案中受益。
为了更好地处理来自单个 2D 源的数据,一些基于 3D 数据训练的高级模型需要重新训练。MediaPipe 界标由 3D 坐标定义,因此可以重复使用现有的训练方法和概念。另一方面,2D 信息的提取比三维坐标更为直接也更为稳定,在修改设计训练时需要考虑到这一点。
幸运的是,我们无需为实现此目标而进行全新的数据记录。我们仍然可以使用注释详细的大型视频数据库。预处理的动作捕捉数据可以从我们的记录中提取,并在 3D 世界中解释,从而用来模拟任何虚拟摄像头视图中的手部、骨架或面部界标检测。
在虚拟摄像头视图的数据中,我们同时使用传统的 2D 记录,以足够的比例覆盖界标检测的独特噪点特征。由于大多数此类数据已经提前收集了,所以我们可以专注于尝试最新技术并训练新模型。
总结
在 MediaPipe 助力的改进,让 SignAll 可以更改其模型。除了提供用于手语教学和翻译的多合一产品之外,SignAll 现在也开始提供面向开发者的 SDK。此 SDK 的功能取决于摄像头的类型和可用的算力。SDK 可以启用的功能包括:
通过用手语表示联系人的姓名来发起视频通话
通过手语(与语音输入相对应)在导航中添加地址,或在快餐店的信息亭或直通车道中进行点餐。
面向开发者的 SDK
https://signall.us/sdk
SignAll 的使命是让手语能够全方位替代语音,而我们非常高兴看到越来越多的应用实现了此功能。
我们十分期待 MediaPipe 未来的更新,这些更新能够帮助我们进一步实现终极目标:让所有人在任何设备上都能使用我们的解决方案。最值得期待的更新是能够建立自定义的 MediaPipe 图,并添加我们自己的计算器,从而在 WebAssembly 技术的辅助下实现基于网络的解决方案,这样网站就能够为失聪访问者提供全新水平的无障碍功能。
更多 AI 相关阅读:



以上是关于SignAll SDK:基于 MediaPipe 的手语接口现已开放的主要内容,如果未能解决你的问题,请参考以下文章
使用Python基于OpenCV+MediaPipe追踪手势并控制音量