基于python-mediapipe手部识别
Posted Rgylin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python-mediapipe手部识别相关的知识,希望对你有一定的参考价值。
前言
今天学习了一个非常神奇的手部识别模块mediapipe,只是其中一个功能还有很多功能以后有时间再去学习

效果如图
在这里做一下记录
学习记录
首先呢我们先安装必要的模块
mediapipe
opencv-python =>cv2
我们用的工具时pycharm 直接在那个模块下点加号搜索其模块安装就行
好了 安装好了之后就开始用了
首先是
cap= cv2.VideoCapture()
参数是0的话表示打开笔记本的内置摄像头,参数是视频文件路径则打开视频 返回一个对象
有了对象之后就可以按帧来读了
success,img= cap.read() 读取图像帧 有两个返回值,第一个是是否读取成功,第二个是每一帧的图像
再就是cv2.waitKey()用法
参数是1,表示延时1ms切换到下一帧图像,对于视频而言
参数为0,如cv2.waitKey(0)只显示当前帧图像,相当于视频暂停
今天的主角是这个
生成手部对象,注意的是,在后面处理的是RGB格式图像 所以使用 hands.process()处理的图像必须是RGB格式
myHands= mediapipe.soultions.hands
hands= myHands.Hands()
当然也离不开画图模块
#对产生的result.multi_hand_landmarks标志物进行连接
mpDraw = mediapipe.soultions.drawing_utils
img_R= cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
result = hands.process(img_R)
#result.multi_hand_landmarks是检测到所有手的列表,对该列表进行访问我们可以得到每只手对应标志位的信息
for handLms in result.multi_hand_landmarks:
mpDraw.draw_landmarks(img, handLms, myHands.HAND_CONNECTIONS)
也可以用cv2.putText()方法进行标记
cv2.putText(img, str(int(id)), (cx , cy ), cv2.FONT_HERSHEY_PLAIN,1, (0, 0, 255), 2)
贴大佬的解释
参数:
image:它是要在其上绘制文本的图像。
text:要绘制的文本字符串。
org:它是图像中文本字符串左下角的坐标。坐标表示为两个值的元组,即(X坐标值,Y坐标值)。
font:它表示字体类型。一些字体类型是FONT_HERSHEY_SIMPLEX,FONT_HERSHEY_PLAIN,等
fontScale:字体比例因子乘以font-specific基本大小。
color:它是要绘制的文本字符串的颜色。对于BGR,我们通过一个元组。例如:(255,0,0)为蓝色。
thickness:它是线的粗细像素。
lineType:这是一个可选参数,它给出了要使用的行的类型。
bottomLeftOrigin:这是一个可选参数。如果为true,则图像数据原点位于左下角。否则,它位于左上角。

相关代码为
import cv2
import mediapipe as mp
import time
#视频操作函数
#也可以导入视频
cap = cv2.VideoCapture(0)
#手部跟踪 处理的事RGB格式 所以使用 hands.process()处理的图像必须是RGB格式
myHands= mp.solutions.hands
hands= myHands.Hands()
mpDraw = mp.solutions.drawing_utils
pTime = 0
cTime = 0
while 1:
#读取摄像头每一帧并显示
success,img= cap.read()
cv2.imshow("image",img)
#必须是RGB格式 而得到的图像默认是BGR格式所以要转
img_R= cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
result = hands.process(img_R)
#检测所有手的列表,对列表进行访问可以获得 手的位置信息
if(result.multi_hand_landmarks):
for handLms in result.multi_hand_landmarks:
#每一个标志位都有一个id 获取并将其显示
for id,lm in enumerate(handLms.landmark):
h, w, c = img.shape
#获取界面中的坐标 ,这里经过测试是获取的小数需要*界面获取真正坐标
cx, cy = int(lm.x*w), int(lm.y*h)
cv2.putText(img, str(int(id)), (cx , cy ), cv2.FONT_HERSHEY_PLAIN,
1, (0, 0, 255), 2)
cv2.imshow("Image", img)
cv2.waitKey(1)
换成
mpDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS)
就成了一开始图片的结果
当然也可以加
fps
操作为
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 255), 3)
所以最后效果为
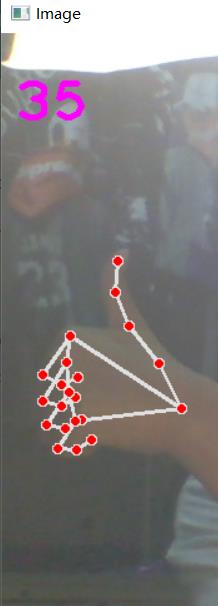
贴一下写的代码
import cv2
import mediapipe as mp
import time
#视频操作函数
#也可以导入视频
cap = cv2.VideoCapture(0)
#手部跟踪 处理的事RGB格式 所以使用 hands.process()处理的图像必须是RGB格式
myHands= mp.solutions.hands
hands= myHands.Hands()
mpDraw = mp.solutions.drawing_utils
pTime = 0
cTime = 0
while 1:
#读取摄像头每一帧并显示
success,img= cap.read()
cv2.imshow("image",img)
img_R= cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
result = hands.process(img_R)
#检测所有手的列表,对列表进行访问可以获得 手的位置信息
if(result.multi_hand_landmarks):
for handLms in result.multi_hand_landmarks:
for id,lm in enumerate(handLms.landmark):
h, w, c = img.shape
#获取界面中的坐标
cx, cy = int(lm.x*w), int(lm.y*h)
#cv2.putText(img, str(int(id)), (cx , cy ), cv2.FONT_HERSHEY_PLAIN,
# 1, (0, 0, 255), 2)
#mpDraw.draw_landmarks(img, handLms, myHands.HAND_CONNECTIONS)
#然后进行画图
mpDraw.draw_landmarks(img, handLms, myHands.HAND_CONNECTIONS)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 255), 3)
cv2.imshow("Image", img)
cv2.waitKey(1)
最后的总结是:太神奇了,学到了模块的一小部分,就可以实现这个,还有更多东西需要学习.
以上是关于基于python-mediapipe手部识别的主要内容,如果未能解决你的问题,请参考以下文章