基于mediapipe的姿态识别和简单行为识别
Posted 风栖柳白杨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于mediapipe的姿态识别和简单行为识别相关的知识,希望对你有一定的参考价值。
文章目录
学习目标
1、可以识别到人体姿态关键点
2、可以通过角度识别的方法识别到人体的动作(自定义)
源码地址:🚀🚀🚀🚀
一、mediapipe的安装
其实这部分很简单,直接在windows命令行的环境下
pip install mediepipe
就可以啦
二、使用mediapipe检测关键点
1、mediapipe的介绍
Mediapipe是一个用于构建机器学习管道的框架,用户处理视频、音频等时间序列数据。这个跨平台框架适用于桌面/服务器、android、ios和各类嵌入式设备。
目前mediapipe包含16个solutions,分别为
人脸检测
Face Mesh
虹膜
手
姿态
人体
人物分割
头发分割
目标检测
Box Tracking
instant Motion Tracking
3D目标检测
特征匹配
AutoFlip
MediaSequence
YouTuBe_8M
,谷歌官方将这种人体姿态识别的方法叫做Blazepose。
(0)检测前的准备工作
'''导入一些基本的库'''
import cv2
import mediapipe as mp
import time
from tqdm import tqdm
import numpy as np
from PIL import Image, ImageFont, ImageDraw
# ------------------------------------------------
# mediapipe的初始化
# 这一步是必须的,因为要使用到以下定义的几个类
# ------------------------------------------------
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
pose = mp_pose.Pose(static_image_mode=True)
(1)检测图片
def process_frame(img):
start_time = time.time()
h, w = img.shape[0], img.shape[1] # 高和宽
# 调整字体
tl = round(0.005 * (img.shape[0] + img.shape[1]) / 2) + 1
tf = max(tl-1, 1)
# BRG-->RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB图像输入模型,获取 关键点 预测结果
results = pose.process(img_RGB)
keypoints = ['' for i in range(33)]
if results.pose_landmarks:
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
for i in range(33):
cx = int(results.pose_landmarks.landmark[i].x * w)
cy = int(results.pose_landmarks.landmark[i].y * h)
keypoints[i] = (cx, cy) # 得到最终的33个关键点
else:
print("NO PERSON")
struction = "NO PERSON"
img = cv2.putText(img, struction, (25, 100), cv2.FONT_HERSHEY_SIMPLEX, 1.25, (255, 255, 0),
6)
end_time = time.time()
process_time = end_time - start_time # 图片关键点预测时间
fps = 1 / process_time # 帧率
colors = [[random.randint(0,255) for _ in range(3)] for _ in range(33)]
radius = [random.randint(8,15) for _ in range(33)]
for i in range(33):
cx, cy = keypoints[i]
#if i in range(33):
img = cv2.circle(img, (cx, cy), radius[i], colors[i], -1)
'''str_pose = get_pos(keypoints) #获取姿态
cv2.putText(img, "POSE-".format(str_pose), (12, 100), cv2.FONT_HERSHEY_TRIPLEX,
tl / 3, (255, 0, 0), thickness=tf)'''
cv2.putText(img, "FPS-".format(str(int(fps))), (12, 100), cv2.FONT_HERSHEY_SIMPLEX,
tl/3, (255, 255, 0),thickness=tf)
return img
如果需要执行代码,则在文末的主函数中使用
if __name__ == '__main__':
# 读取图片
img0 = cv2.imread("./data/outImage--20.jpg")
# 因为有中文路径,所以加上此行
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), -1)
img = image.copy()
# 检测关键点,得到的image是检测过后的图片
image = process_frame(img)
# 使用matplotlib画图
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(img0[:,:,::-1])
axes[0].set_title("原图")
axes[1].imshow(image[:,:,::-1])
axes[1].set_title("检测并可视化后的图片")
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams["axes.unicode_minus"] = False
plt.show()
fig.savefig("./data/out.png")
最后附上检测效果。

(2)检测视频
任何不涉及3D卷积的机器视觉方法,检测视频其实就是检测图片。因为视频是由多帧图片融合得来的。
比如说一个30帧的视频,那么它的每一秒钟,就是由30张图片叠加而成。
将这些分割出的图片分别进行检测,最后将检测的图片进行融合,得到的就是检测后的视频。
有了这个依据,我们就可以把图片检测过程写成一个函数,在视频的每一帧中调用这个函数就可以啦
一般使用opencv库将视频分解为图片帧的形式,示例代码如下:
def video2image(videoPath="./video/demo1.mp4",
image_dir="./image"):
'''videoPath是视频路径, image_dir是图片保存的文件夹路径'''
cap = cv2.VideoCapture(videoPath)
frame_count = 0
while(cap.isOpened()):
success,frame = cap.read()
if not success:
break
frame_count += 1
print("视频总帧数:", frame_count)
cap.release()
cap = cv2.VideoCapture(videoPath)
count = 0
with tqdm(total=frame_count-1) as pbar:
try:
while(cap.isOpened()):
success, frame = cap.read()
if not success:
break
#处理帧
try:
if count % 20 == 0:
cv2.imwrite("/outImage--.jpg".format(image_dir, count), frame)
except:
print("error")
pass
if success == True:
pbar.update(1)
count+=1
except:
print("中途中断")
pass
cv2.destroyAllWindows()
cap.release()
print("视频已经处理结束,进行下一步操作!!!")
那么落实到本文想要实现的功能上,就可以在视频分解出的帧后面加上图片检测函数。
代码如下所示:
def process_video(video_path="./Data.mp4"):
video_flag = False
cap = cv2.VideoCapture(video_path)
out_path = "./out_Data.mp4"
print("视频开始处理……")
frame_count = 0
while (cap.isOpened()):
success, frame = cap.read()
frame_count += 1
if not success:
break
cap.release()
print("总帧数 = ", frame_count)
cap = cv2.VideoCapture(video_path)
if video_flag == False:
frame_size = cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT) #处理图像的尺寸。
fourcc = cv2.VideoWriter_fourcc(*'mp4v') #保存视频文件的格式为mp4
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(out_path, fourcc, fps, (int(frame_size[0]),int(frame_size[1])), ) #输出图像的句柄
with tqdm(total=frame_count-1) as pbar:
try:
while cap.isOpened():
success, frame = cap.read()
if success:
pbar.update(1)
frame = process_frame(frame) # frame就是视频截取的帧,process_frame表示对其检测。
cv2.namedWindow("frame", cv2.WINDOW_NORMAL)
cv2.imshow("frame", frame)
out.write(frame)
if cv2.waitKey(1) == 27:
break
else:
break
except:
print("中途中断")
pass
cap.release()
cv2.destroyAllWindows()
out.release()
print("视频已保存至", out_path)
有了视频的代码,那么就可以在主函数中对其进行调用,可视化效果就不展示了。
三、使用mediapipe-BlazePose检测自定义简单行为
1、原理介绍
将Mediapipe用于行为检测是比较复杂的一件事;如果这样做,那么行为检测的精度就完全取决于Mediapipe关键点的检测精度。
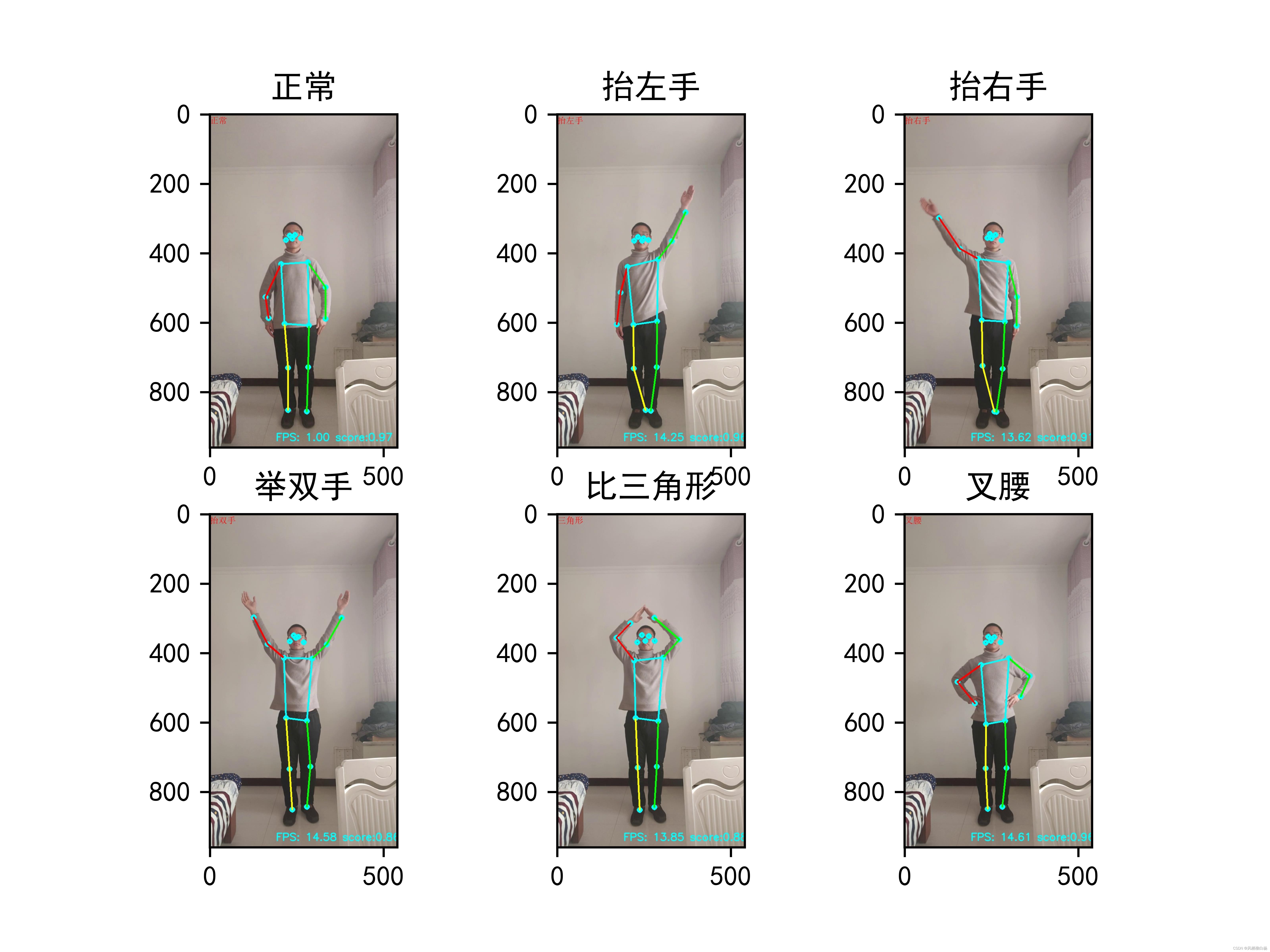
于是可以根据下图中人的关节夹角来对人的位姿进行检测。

如举手的时候,大臂与水平方向夹角是一定大于0度的。
叉腰的时候,双手垂下,大臂与小臂的夹角大于60度小于120度
那么这样就可以完成一些基本动作的分类。
我这里只列出几种比较简单的。
(1)举双手(2)举左手(3)举右手(4)叉腰(5)比三角形
先看一下效果图
2、实现过程
首先要知道,由坐标求得矢量的公式,其实就是两个坐标相减。
那么求两个矢量之间的夹角公式:

那么到代码中就是:
v1 = (x1, y1) - (x2, y2)
v2 = (x0, y0) - (x2, y2)
def get_angle(v1, v2):
angle = np.dot(v1, v2) / (np.sqrt(np.sum(v1 * v1)) * np.sqrt(np.sum(v2 * v2)))
angle = np.arccos(angle) / 3.14 * 180
cross = v2[0] * v1[1] - v2[1] * v1[0]
if cross < 0:
angle = - angle
return angle
这样就可以得到两个矢量的夹角。
之后,就可以通过夹角对行为进行判断,这里的规则是
举双手 左手矢量小于0右手矢量夹角大于0
举左手 左手矢量小于0右手矢量小于0
举右手 左手矢量大于0右手矢量大于0
比三角形 举双手的同时,大臂与小臂的夹角小于120度
正常 左手矢量大于0右手矢量夹角小于0
叉腰 正常情况下,左手肘夹角小于120度,右手肘夹角也小于0
给出的代码示例如下:
def get_pos(keypoints):
str_pose = ""
# 计算左臂与水平方向的夹角
keypoints = np.array(keypoints)
v1 = keypoints[12] - keypoints[11]
v2 = keypoints[13] - keypoints[11]
angle_left_arm = get_angle(v1, v2)
#计算右臂与水平方向的夹角
v1 = keypoints[11] - keypoints[12]
v2 = keypoints[14] - keypoints[12]
angle_right_arm = get_angle(v1, v2)
#计算左肘的夹角
v1 = keypoints[11] - keypoints[13]
v2 = keypoints[15] - keypoints[13]
angle_left_elow = get_angle(v1, v2)
# 计算右肘的夹角
v1 = keypoints[12] - keypoints[14]
v2 = keypoints[16] - keypoints[14]
angle_right_elow = get_angle(v1, v2)
if angle_left_arm<0 and angle_right_arm<0:
str_pose = "LEFT_UP"
elif angle_left_arm>0 and angle_right_arm>0:
str_pose = "RIGHT_UP"
elif angle_left_arm<0 and angle_right_arm>0:
str_pose = "ALL_HANDS_UP"
if abs(angle_left_elow)<120 and abs(angle_right_elow)<120:
str_pose = "TRIANGLE"
elif angle_left_arm>0 and angle_right_arm<0:
str_pose = "NORMAL"
if abs(angle_left_elow)<120 and abs(angle_right_elow)<120:
str_pose = "AKIMBO"
return str_pose
得到的str_pose就是行为字符串,在process_frame中可以在图片帧中可视化。
到这里,关键点检测与简单行为检测已经全部介绍结束了,如果实在复现不成的,可以直接看我代码仓库中的源码
计划:将在未来的博客里,把基于wxpython的UI设计与Mediapipe进行融合,实现可视化的交互过程,请持续关注。
学习之路逆水行舟,加油加油!!!
机器学习实验四基于Logistic Regression二分类算法实现手部姿态识别
文章目录
本次实验的所有代码已上传个人github仓库:https://github.com/Scienthusiasts/Machine-Learning
Logistic 回归实现手势识别
其实好久以前博主本人就有构思实现一个有界面的完整的手势识别系统,即不仅可以实现手部姿态的检测,还能判断手部的姿势对应所要表达的信息。基于这个想法可以实现很多事情,比如说根据手势进行隔空绘图,操作游戏场景等等(可以和VR结合),除此之外还可以控制鼠标,控制PPT翻页等。基于手势识别的应用前景可以说是非常广泛的(也可以拿来搞课设🐛🐛🐛)。
1. 想法构思
现有的网上开源的手势识别算法主要基于两种思路:
一是通过图像形态学处理,肤色检测,图像滤波等方法提取出手部轮廓或者手部边缘,再根据边缘信息提取出手部特征。在进行识别时将测试数据与建立的手部特征进行比对,这是基于传统数字图像处理的方法。
图像来源:基于OpenCV的手势识别完整项目(Python3.7)
另一个则是走深度学习的路线,通过深度网络提取出手部区域及关键点(本质也是一个回归+分类问题),再进行常规操作(比如比较关键点之间的夹角判断姿态等)。或者直接基于目标检测算法、卷积神经网络训练大量的手势图片,这和经典的图像识别/目标检测类似。
基于OpenPose的手部关键点检测:
为了和当前博主正在学习的机器学习算法联系起来,在本篇博客中,我们暂不考虑如何实现手部关键点的回归问题,仅考虑分类问题。因此博主将会基于Mediapipe开源深度学习工具包里的手部姿态检测算法提取手部关键点。然后基于这些关键点进行手势的分类。
mediapipe手部关键点检测包含21个手部关键点:

Mediapipe API传送门:https://google.github.io/mediapipe/solutions/hands
一些细节
事实上,博主也曾想过直接通过录制大量的手势图像,然后直接将这些图像喂入算法进行训练。但这实际上有一些问题:我们知道,相较于直接使用关键点进行预测,图像实则包含了更多的细节特征,然而相应的这也会带来过多的噪声。对于logistic regression这样简单的线性二分类算法而言,可能难以训练出泛化性能较好的参数,因此,只选择手部关键点作为训练数据可能是一个上策。
但是,我们又该如何预处理这些关键点使其能够表达姿态信息呢?博主一开始的想法是使用关键点的坐标。然而坐标实际上是绝对的,如果手部出现在图像中的位置不同但手势完全相同,它们的坐标也是不同的,这就会给算法的训练增添而外的负担。一个想法是使用关键点之间的距离,即关键点两两之间的距离作为训练数据的维度(这样不仅能够保证姿态数据的平移不变性,同样也能够保证旋转不变性:在三维坐标下,不同角度的两个相同姿态的手势它们各自两两关键点之间的距离是相同的)
好,训练数据既然选定,那就说干就干,效果好不好再说。
2. 实现流程
2.1 数据采集与预处理
2.1.1基于mediapipe工具包的手部关键点提取
mediapipe网站已经为我们提供了完整的手部关键点检测的相关API以及Python 代码实现,我们要做的只是Ctrl C V,不过一些细节仍然要改下:
... ...
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
... ...
在相关代码的这两行下就是提取的手部关键点,我们可以输出hand_landmarks这个变量一探究竟:
... ...
landmark
x: 0.9662408828735352
y: 0.5577888488769531
z: -0.23717156052589417
... ...
通过观察可以发现,hand_landmarks变量下包含了21个landmark属性,因此我们可以断定每一个landmark就对应一个手部关键点,其中每个landmark下又有x,y,z三个属性,很明显这便是每个关键点的空间坐标(mediapipe集成的算法可以通过单目相机预测出关键点相对于手掌关键点的深度)。不过它们都在(0,1)这个区间内,因此这些坐标应该是被归一化处理过的。
提取坐标的代码:
... ...
keypoint = []
for i in range(21):
x = hand_landmarks.landmark[i].x
y = hand_landmarks.landmark[i].y
z = hand_landmarks.landmark[i].z
keypoint.append([x,y,z])
keypoint = np.array(keypoint)
... ...
然后记住keypoint这个变量的shape:[21,3]
只提取一帧手势关键点用来训练算法显然是不够的,因此,对每个手势我们提取500帧关键点并整合为一个数据集,并保存在position变量中,最后转存为numpy二进制文件:
... ...
if CNT<500:
cv2.putText(image, str(CNT), (30,30), cv2.FONT_HERSHEY_SIMPLEX, .6, (0, 255, 0), 1)
position.append(keypoint)
CNT += 1
... ...
position = np.array(position)
print(position.shape)
np.save('./hand_frames.npy', position)
... ...
然后记住position这个变量的shape:[500,21,3]
手部关键点可视化
得到了手部500帧的关键点坐标,接下来就可以进行预处理转化为关键点两两之间的距离。不过在此之前,我觉得先可视化一下这500帧关键点应该也蛮有意思的哈哈🤣
手部关键点可视化:
# 绘制随时间变化下的手势数据集
def draw(X, ax, step):
lines = []
# 绘制点与点之间的连线
lines.append(X[[0,1,2,3,4]])
lines.append(X[[0,5,6,7,8]])
lines.append(X[[0,17,18,19,20]])
lines.append(X[[5,9,13,17]])
lines.append(X[[9,10,11,12]])
lines.append(X[[13,14,15,16]])
for line in lines:
ax.plot(line[:,0], line[:,1], line[:,2], linewidth=2)
ax.set_xlim(0,1)
ax.set_ylim(0,1)
ax.set_zlim(-0.5,0.5)
plt.pause(0.01)
plt.cla()
# 三维手势数据集可视化
def show_frames(hand_frame):
fig = plt.figure()
# 3D绘图
ax = fig.add_subplot(111, projection='3d')
for step, hand in enumerate(hand_frame):
draw(hand, ax, step)
if __name__ == "__main__":
# 录制的手势数据集
hand_frames = np.load('./hand_frame/hand_frame_one.npy')
show_frames(hand_frames)
可视化效果(左图为五指张开的姿态,右图为紧握双拳的姿态):

2.1.2 将关键点的绝对坐标转化为相对距离
在计算距离时,利用numpy的广播机制可以一次性得出一个关键点和其余所有关键点两两之间的距离矩阵deal_hand_frame.py:
# 计算手势关键点一点和所有点之间的距离
def calc_dist(p1, p2):
x = (p1[0]-p2[:,0]) * (p1[0]-p2[:,0])
y = (p1[1]-p2[:,1]) * (p1[1]-p2[:,1])
z = (p1[2]-p2[:,2]) * (p1[2]-p2[:,2])
dist = x + y + z
return dist
def distance(X):
dataSets = []
for hand in X:
dist_matrix = []
for i in range(21):
dist_matrix.append(calc_dist(hand[i], hand))
# plt.imshow(dist_matrix)
# plt.pause(0.01)
# plt.cla()
dataSets.append(dist_matrix)
return np.array(dataSets)
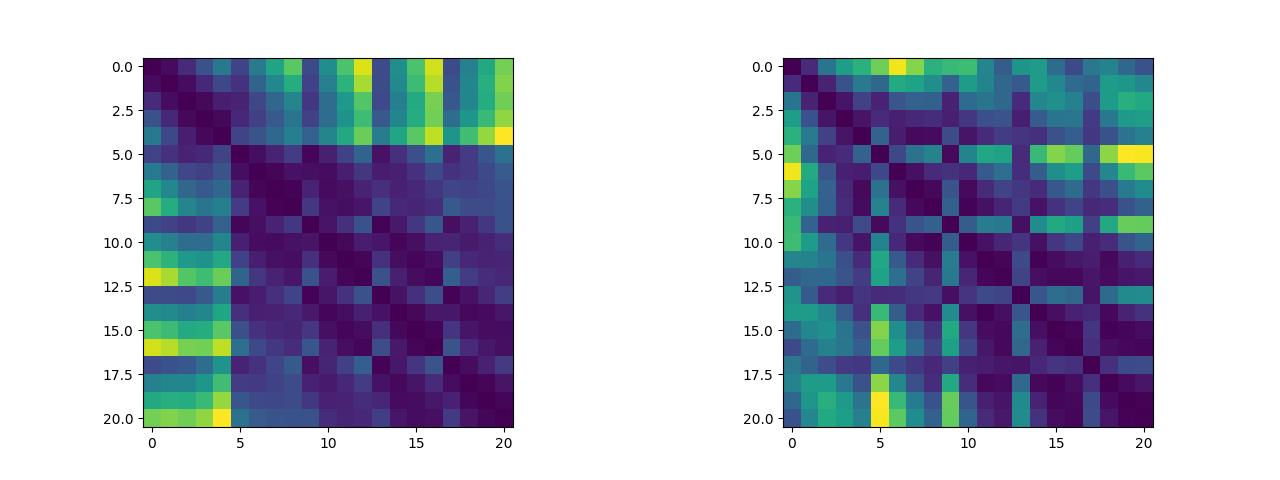
除此之外,我们可以将关键点两两之间的距离绘制成距离矩阵,我们可以来可视化这个距离矩阵看看其中是否有有迹可循的特征(说实话看不太出来)(左图为五指张开姿态下的距离矩阵,右图为紧握双拳姿态下的距离矩阵,这两个数据集将作为逻辑斯蒂回归二分类算法的训练集):
2.2 算法实现
搭建logistic回归算法
logistic算法的原理以及损失函数我已在前两篇【机器学习算法】博客中有了相对详细的介绍,本次实验就不再涉及,感兴趣的小伙伴们可以看看我前两篇撰写的博客。
logistic回归算法代码细节logistic.py:
import sklearn.datasets as datasets # 数据集模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 划分训练集和验证集
import sklearn.metrics # sklearn评估模块
from sklearn.preprocessing import StandardScaler # 标准归一化
from sklearn.metrics import accuracy_score
# 设置超参数
LR= 1e-5 # 学习率
EPOCH = 20000 # 最大迭代次数
BATCH_SIZE = 200 # 批大小
class logistic:
def __init__(self, X=None, y=None, mode="pretrain"):
self.X = X
self.y = y
# 记录训练损失,准确率
self.train_loss = []
self.test_loss = []
self.train_acc = []
self.test_acc = []
# 标准归一化
self.scaler = StandardScaler()
# 1. 初始化W参数
if mode == "pretrain":
self.W = np.load("../eval_param/Weight.npy")
else:
# 随机初始化W参数 初始化参数太大会导致损失可能太大,导致上溢出
self.W = np.random.rand(X.shape[1]+1, 1) * 0.1 # 均匀分布size = [n,1]范围为[0,1]
# 将概率转化为预测的类别
def binary(self, y):
y = y > 0.5
return y.astype(int)
# 二分类sigmoid函数
def sigmoid(self, x):
return 1/(1 + np.exp(-x))
# 二分类交叉熵损失
def cross_entropy(self, y_true, y_pred):
# y_pred太接近1会导致后续计算np.log(1 - y_pred) = -inf
crossEntropy = -np.sum(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred)) / (y_true.shape[0])
return crossEntropy
# 数据预处理(训练)
def train_data_process(self):
self.y = self.y.reshape(-1,1)
# 划分训练集和验证集,使用sklearn中的方法
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, test_size=0.3)
# 标准归一化
self.std = np.std(X_train, axis=0) + 1e-8
self.mean = np.mean(X_train,axis=0)
X_train = (X_train - self.mean) / self.std
X_test = (X_test - self.mean) / self.std
# 加入偏置
X_train = np.concatenate((np.ones((X_train.shape[0], 1)), X_train), axis=1)
X_test = np.concatenate((np.ones((X_test.shape[0], 1)), X_test), axis=1)
# 每个epoch包含的批数
NUM_BATCH = X_train.shape[0]//BATCH_SIZE+1
print('训练集大小:', X_train.shape[0], '验证集大小:', X_test.shape[0])
return X_train, X_test, y_train, y_test, NUM_BATCH
def test_data_process(self, X):
X = X.reshape(1,-1)
# 标准归一化
self.std = np.load('../eval_param/std.npy')
self.mean = np.load('../eval_param/mean.npy')
X = (X - self.mean) / self.std
X = np.concatenate((np.ones((X.shape[0], 1)), X), axis=1)
return X
def train(self, LR, EPOCH, BATCH_SIZE):
X_train, X_test, y_train, y_test, NUM_BATCH = self.train_data_process()
for i in range(EPOCH):
# 这部分代码打乱数据集,保证每次小批量迭代更新使用的数据集都有所不同
# 产生一个长度为m的顺序序列
index = np.arange(X_train.shape[0])
# shuffle方法对这个序列进行随机打乱
np.random.shuffle(index)
# 打乱
X_train = X_train[index]
y_train = y_train[index]
# 在验证集上评估:
pred_y_test = self.sigmoid(np.dot(X_test, self.W))
self.test_loss.append(self.cross_entropy(y_true=y_test, y_pred=pred_y_test))
self.test_acc.append(accuracy_score(y_true=y_test, y_pred=self.binary(pred_y_test)))
# 在训练集上评估:
pred_y_train = self.sigmoid(np.dot(X_train, self.W))
self.train_loss.append(self.cross_entropy(y_true=y_train, y_pred=pred_y_train))
self.train_acc.append(accuracy_score(y_true=y_train, y_pred=self.binary(pred_y_train)))
if i % BATCH_SIZE == 0:
print("eopch: %d | train loss: %.6f | test loss: %.6f | train acc.:%.4f | test acc.:%.4f" %
(i, self.train_loss[i], self.test_loss[i], self.train_acc[i], self.test_acc[i]))
for batch in range(NUM_BATCH-1):
# 切片操作获取对应批次训练数据(允许切片超过列表范围)
X_batch = X_train[batch*BATCH_SIZE: (batch+1)*BATCH_SIZE]
y_batch = y_train[batch*BATCH_SIZE: (batch+1)*BATCH_SIZE]
# 2. 求梯度,需要用上多元线性回归对应的损失函数对W求导的导函数
previous_y = self.sigmoid(np.dot(X_batch, self.W))
grad = np.dot(X_batch.T, previous_y - y_batch)
# 加入正则项
# grad = grad + np.sign(W) # L1正则
grad = grad + self.W # L2正则
# 3. 更新参数,利用梯度下降法的公式
self.W = self.W - LR * grad
# 打印最终结果
for loop in range(32):
print('===', end='')
print("\\ntotal iteration is : ".format(i+1))
y_hat_train = self.sigmoid(np.dot(X_train, self.W))
loss_train = self.cross_entropy(y_true=y_train, y_pred=y_hat_train)
print("train loss:".format(loss_train))
y_hat_test = self.sigmoid(np.dot(X_test, self.W))
loss_test = self.cross_entropy(y_true=y_test, y_pred=y_hat_test)
print("test loss:".format(loss_test))
print("train acc.:".format(self.train_acc[-1]))
print("test acc.:".format(self.test_acc[-1]))
def eval(self, X):
X = self.test_data_process(X)
y_hat = self.sigmoid(np.dot(X, self.W))
return y_hat
# 保存权重
def save(self):
np.save("./eval_param/Weight.npy", self.W)
np.save("./eval_param/std.npy", self.std)
np.save("./eval_param/mean.npy", self.mean)
np.save("./eval_param/train_loss.npy", self.train_loss)
np.save("./eval_param/test_loss.npy", self.test_loss)
np.save("./eval_param/train_acc.npy", self.train_acc)
np.save("./eval_param.test_acc.npy", self.test_acc)
2.3 训练
import sklearn.datasets as datasets # 数据集模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 划分训练集和验证集
import sklearn.metrics # sklearn评估模块
from sklearn.preprocessing import StandardScaler # 标准归一化
from sklearn.metrics import accuracy_score
import sys;sys.path.append('../')
from logistic import logistic
if __name__ == "__main__":
以上是关于基于mediapipe的姿态识别和简单行为识别的主要内容,如果未能解决你的问题,请参考以下文章