ST-GCN 实现人体姿态行为分类
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ST-GCN 实现人体姿态行为分类相关的知识,希望对你有一定的参考价值。
作者 | 李秋键
出品 | AI科技大本营(ID:rgznai100)
引用
人体行为识别是计算机视觉及机器学习方面的热门研究领域。它在对视频中的人类行为进行运动分析、行为识别乃至延伸至人机交互领域都有着非常广泛的应用。研究初期,人体行为识别主要是以基于静态图像为研究对象。通过提取静态图像中的人体动作特征并对动作进行分类。然而仅基于静态图像来进行识别人体行为的局限性在于人体行为是连续、动态的,单凭一张静态图像无法进行判断识别。而基于视频为研究对象,可以将视频看作连续静态图像的时间序列。近两年,很多基于视频为对象的人体行为识别取得了不错的成果,例如,Gao等人以多视角的视频为基础开发出了一种自适应融合和类别级词典学习模型。
在通常情况下,人体行为识别有着例如外观、光流、身体骨骼和深度等多种模态,人们可以通过这些模态建模并传达重要信息进而实现人体行为识别。近几年,比较热门的深度领域有着很多的成果,Kamel等人利用使用卷积神经网络从深度图和姿势数据中进行人体行为识别。Ji等人利用深度图来将骨骼信息嵌入从而达到对人体进行分区的目的,以及Zhao等人提出了一种贝叶斯分层动态模型用于人类动作识别也取得了不错的效果。而在这些模态当中,人类身体骨骼通常能与其他模态相辅相成并传达重要信息。同时也因为骨骼信息的清晰直观且不易受到人体外观等其他因素的影响,具有良好的鲁棒性。
基于骨架的人体行为识别方法因对复杂场景具有较强的鲁棒性,因此近些年涌现很多基于骨架的动作识别方法。一般分为两种方法:
(1)基于人工特征选择的方法,通过人工设定的特性来捕捉关节运动动态。例如关节的相对位置、关节轨迹的协方差矩阵或是身体部分之间的平移旋转等特性。
(2)深度学习方法,基于深度学习进行骨架建模,端到端的动作识别模型通过使用递归神经网络和临时CNNs来学习。ST-GCN不同于这些方法,虽然强调了人体关节建模的重要性,但这些部分一般使用领域知识明确分配指定。ST-GCN将GCN应用于基于骨架的人体行为识别系统中,在此基础上加入了对识别人体行为非常重要的关节之间的空间关系这一因素,以人体关节为节点,同时连接关节之间的自然联系和相同关节的跨连续时间联系,然后以此为基础构造多个时空图卷积层,沿时空维度进行集成信息。
故本项目通过搭建ST-GCN实现对视频时空流进行姿态估计和行为分类。最终可实现效果如下:

1、ST-GCN 介绍
ST-GCN是香港中文大学提出一种时空图卷积网络,可以用它进行人类行为识别。这种算法基于人类关节位置的时间序列表示而对动态骨骼建模,并将图卷积扩展为时空图卷积网络而捕捉这种时空的变化关系。
1.1 模型通道
基于骨架的数据可以从动作捕捉设备中获得,也可以从视频中获得姿态估计算法。通常数据是一个坐标系序列,每个坐标系都有一组关节坐标。ST-GCN就是构建一个以关节为图节点,以人体结构和时间为图边的自然连接为图节点的时空图。ST-GCN的输入是图节点上的关节坐标向量。这可以看作是对基于图像的cnn的模拟,其中输入是由驻留在2D图像网格上的像素强度向量构成的。对输入数据进行多层次的时空图卷积运算,在图上生成更高层次的特征图。然后它将被标准的SoftMax分类器分类到相应的动作类别。
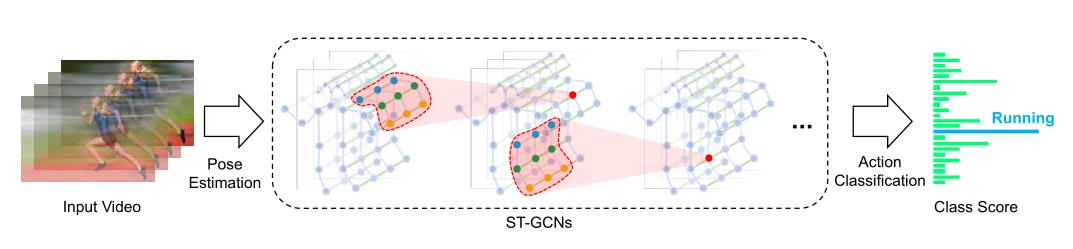
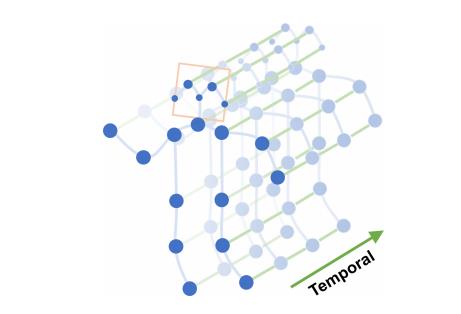
1.2 骨骼图结构
骨骼序列通常由每一帧中每个人体关节的2D或3D坐标表示。使用卷积进行骨骼动作识别,将所有关节的坐标向量连接起来,形成每帧的单一特征向量。

1.3 时空模型
针对空间时间建模。在构建了空间图之后,需要在骨骼序列中建模时空动态。在构建图的时候,图的时间方面是通过在连续的框架中连接相同的关节来构建的。从而能够定义一个非常简单的策略,将空间图CNN扩展到空间时域。
2、模型实验
2.1 环境搭建
1、首先下载好完整无误配置好的代码(包括模型等等,见文末)。
2、搭建最新版的openpose环境,并使用cmake编译。
3、配置好python的cuda环境,以及opencv等基础环境。
4、使用命令
“python main.py demo --openpose E:/cmake/environment/x64/Release --video 2.mp4”进行测试生成结果。
其中“E:/cmake/environment/x64/Release”需要改成自己的openpose环境。
2.2 主函数调用
其中主函数通过使用processors管理的设定好的分类识别、输入输出管理等程序内部函数进行整个程序的布置。
代码如下:
import argparse
import sys
import torchlight
from torchlight import import_class
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Processor collection')
processors = dict()
processors['recognition'] = import_class('processor.recognition.REC_Processor')
processors['demo'] = import_class('processor.demo.Demo')
subparsers = parser.add_subparsers(dest='processor')
for k, p in processors.items():
subparsers.add_parser(k, parents=[p.get_parser()])
arg = parser.parse_args()
Processor = processors[arg.processor]
p = Processor(sys.argv[2:])
p.start()
2.3 模型网络
通过调用空间-时间图卷积网络建立这个网络模型。其中参数in_channels (int)为输入数据中的通道数;
num_class (int)表示用于分类任务的类的数量;
graph_args (dict)表示构建图的参数;
edge_importance_weighting (bool)表示如果“True”,添加一个可学习的对图的边进行重要性加权。代码如下:
def __init__(self, in_channels, num_class, graph_args,
edge_importance_weighting, **kwargs):
super().__init__()
self.graph = Graph(**graph_args)
A = torch.tensor(self.graph.A, dtype=torch.float32, requires_grad=False)
self.register_buffer('A', A)
spatial_kernel_size = A.size(0)
temporal_kernel_size = 9
kernel_size = (temporal_kernel_size, spatial_kernel_size)
self.data_bn = nn.BatchNorm1d(in_channels * A.size(1))
kwargs0 = {k: v for k, v in kwargs.items() if k != 'dropout'}
self.st_gcn_networks = nn.ModuleList((
st_gcn(in_channels, 64, kernel_size, 1, residual=False, **kwargs0),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 128, kernel_size, 2, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 256, kernel_size, 2, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
))
2.4 ST-GCN网络建立
建立ST-GCN网络模型,其中in_channels (int)表示输入序列数据中的通道数;
out_channels (int)表示卷积产生的通道数;
kernel_size (tuple)为时态卷积核和图卷积核的大小;
stride (int,可选)为时间卷积的步幅。默认值:1;
dropout (int,可选)为最终输出的辍学率。默认值:0;
residual (bool,可选)表示如果”True “,应用残留机制。默认值:“True”。
代码如下:
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
dropout=0,
residual=True):
super().__init__()
assert len(kernel_size) == 2
assert kernel_size[0] % 2 == 1
padding = ((kernel_size[0] - 1) // 2, 0)
self.gcn = ConvTemporalGraphical(in_channels, out_channels,
kernel_size[1])
self.tcn = nn.Sequential(
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(
out_channels,
out_channels,
(kernel_size[0], 1),
(stride, 1),
padding,
),
nn.BatchNorm2d(out_channels),
nn.Dropout(dropout, inplace=True),
)
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x运行过程如下可见,在这里通过双击“test.bat”即可直接运行:

完整代码:
链接:
https://pan.baidu.com/s/1Ht7Mr6hJMt5oUKu6ue05fw
提取码:0nqh
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
以上是关于ST-GCN 实现人体姿态行为分类的主要内容,如果未能解决你的问题,请参考以下文章
二维已经 OUT 了?3DPose 实现三维人体姿态识别真香 | 代码干货
人体姿态估计应用源码文末-行为安全监测系统姿态纠正系统健身评分系统