基于Mediapipe与Unity的人体姿态捕捉系统
Posted TonyZhang老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Mediapipe与Unity的人体姿态捕捉系统相关的知识,希望对你有一定的参考价值。
基于Mediapipe与Unity的人体姿态捕捉系统
1. 工程整体介绍
整个工程主要分成三部分:1.基于Mediapipe的人体姿态估计;2.基于Unity的人体姿态展示;3.从Mediapipe到Unity的通讯,即Mediapipe估计的姿态如何实时传递给Unity。
2. 基于Mediapipe的人体姿态估计
姿态估计部分,使用opencv进行人体采集,然后调用Mediapipe对读取的每一帧图像进行姿态估计。
2.1 环境搭建
版本要求:python >= 3.7
pip install mediapipe
pip install opencv-python
pip install opencv-contrib-python
参考官方文档:
链接: https://google.github.io/mediapipe/solutions/pose.
2.2 代码片段
博主假设你已经掌握了最基础的python语法
import cv2
import mediapipe as mp
import numpy as np
def Pose_Images():
#使用算法包进行姿态估计时设置的参数
mp_pose = mp.solutions.pose
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.8) as pose:
#打开摄像头
cap = cv2.VideoCapture(0)
while(True):
#读取摄像头图像
hx, image = cap.read()
if hx is False:
print('read video error')
exit(0)
image.flags.writeable = False
# Convert the BGR image to RGB before processing.
# 姿态估计
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
print(results.pose_landmarks)
cv2.imshow('image', image)
if cv2.waitKey(10) & 0xFF == ord('q'): # 按q退出
break
cap.release()
if __name__ == '__main__':
Pose_Images()
2.3 结果展示
在你的控制台可以看到一个一个点的输出,如下,那么姿态估计就完成了第一步。
landmark
x: 0.7439931035041809
y: 3.0562074184417725
z: -0.25115278363227844
visibility: 0.00022187501599546522
landmark
x: 0.5690034627914429
y: 3.0262765884399414
z: -0.44416818022727966
visibility: 0.00034665243583731353
......
2.4 结果分析
下面我们来分析一下这些点的坐标到底代表了什么。
每一张图片都会产生一组坐标,每组坐标包含32个坐标点。
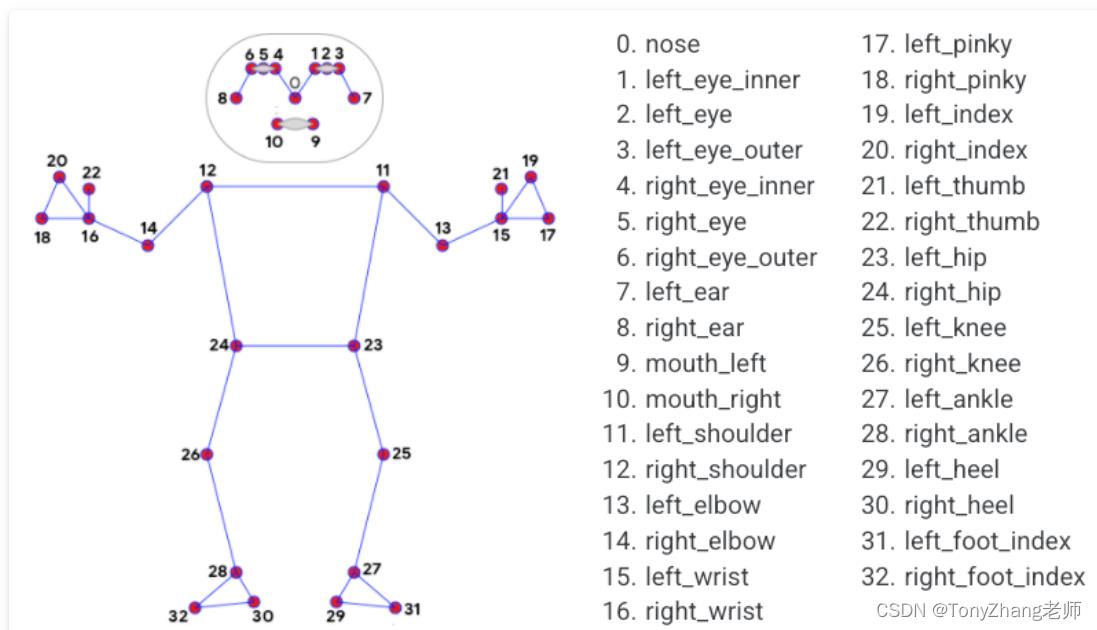
每个地标包括以下内容:
- x和y:通过图像宽度和高度分别归一化为[0.0, 1.0],通俗点说是,真实的x,y坐标,分别除以图像的宽度跟高度。
- z: 代表坐标的深度,臀部中点的深度为原点,数值越小,地标就越靠近摄像机。z的大小使用与x大致相同的比例。
- visibility:一个[0.0, 1.0]的值,表示坐标在图像中可见(存在且不被遮挡)的可能性。
2.5 本章总结
我们通过使用opencv库,打开摄像头采集照片,将照片传递给Mediapipe进行姿态坐标估计,后续我们将坐标放到Unity中进行展示就可以了。
3. 基于Unity的人体姿态展示
博主假设你已经掌握了unity的基础知识。
3.1 Unity 人体骨骼动画
我们可以从Unity商店中或者在此网站https://www.mixamo.com选择任意一个3D的人物模型导入到工程中。
3.2 Mediapipe坐标到Unity的映射
具体转换细节会专门写一篇文件来解释,数据是驱动骨骼运动的。整体的实现参考了开源的解决方案。
参考:
https://github.com/digital-standard/ThreeDPoseTracker
VNectModel.cs 文件实现了从预测坐标到Unity骨骼坐标的转换。
4. 从Mediapipe到Unity的数据传递
姿态预测跟unity的姿态展示毕竟属于不同的进程,对于进程之间的通讯有不同的实现方式。本文选择网络通讯中的UDP通讯,因为UDP通讯具有延迟小的特点,同时我们对于数据的丢失存在一定的容忍性。
4.1 使用Python发送数据
#代码片段示例:
json_data = json.dumps(pose_data)
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
dest_addr = ('127.0.0.1', 5052)
text = json_data.encode('utf-8')
udp_socket.sendto(text, dest_addr)
4.2 使用C#接收数据
此代码片段借鉴了此博主的文章(如有侵权,联系删除)。
Link
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using System;
using System.Text;
using System.Net;
using System.Net.Sockets;
using System.Threading;
public class UDPRecive : MonoBehaviour
Thread receiveThread;
UdpClient client;
public int port = 5052;
public bool startRecieving = true;
public string data;
// Start is called before the first frame update
void Start()
receiveThread = new Thread(
new ThreadStart(ReceiveData));
receiveThread.IsBackground = true;
receiveThread.Start();
// Update is called once per frame
void Update()
private void ReceiveData()
client = new UdpClient(port);
while (startRecieving)
Debug.Log("startRecieving");
try
IPEndPoint anyIP = new IPEndPoint(IPAddress.Any, 0);
byte[] dataByte = client.Receive(ref anyIP);
data = Encoding.UTF8.GetString(dataByte);
Debug.Log(data);
catch (Exception err)
print(err.ToString());
5. 成果展示
从姿态预测到3D展示就完成了,那么我们来看一下效果吧。
11月25日
6. 后续展望
后续会根据需求,出一个对全部代码的讲解,可以帮助读者一步步实现自己的工程。
欢迎提出意见或建议。
7.联系方式
欢迎私信加我。
Mediapipe+OpenCV与Unity引擎实现动作捕捉
前言
之前写了一篇文章: Mediapipe+OpenCV图像识别技术与Unity引擎的结合
其中的技术是Python利用OpenCV图像捕捉,配合强大的Mediapipe库来实现人体动作检测与识别;将识别结果实时同步至Unity中,实现人物模型在Unity中运动身体结构识别
技术更新
因为之前的人物动作捕捉是先通过Python和Mediapipe先将人物动作进行捕捉,将捕捉到的数据format后写入到txt中,在Unity端对txt进行数据读取,进而实现Unity人物运动;其中的缺点是:没有时效性
而本次的改进:通过利用socket和UPD通信,在localhost中数据传输,让动捕数据实时传输,到达实时动捕的效果
Demo演示
之前的Demo展示:https://hackathon2022.juejin.cn/#/works/detail?unique=WJoYomLPg0JOYs8GazDVrw
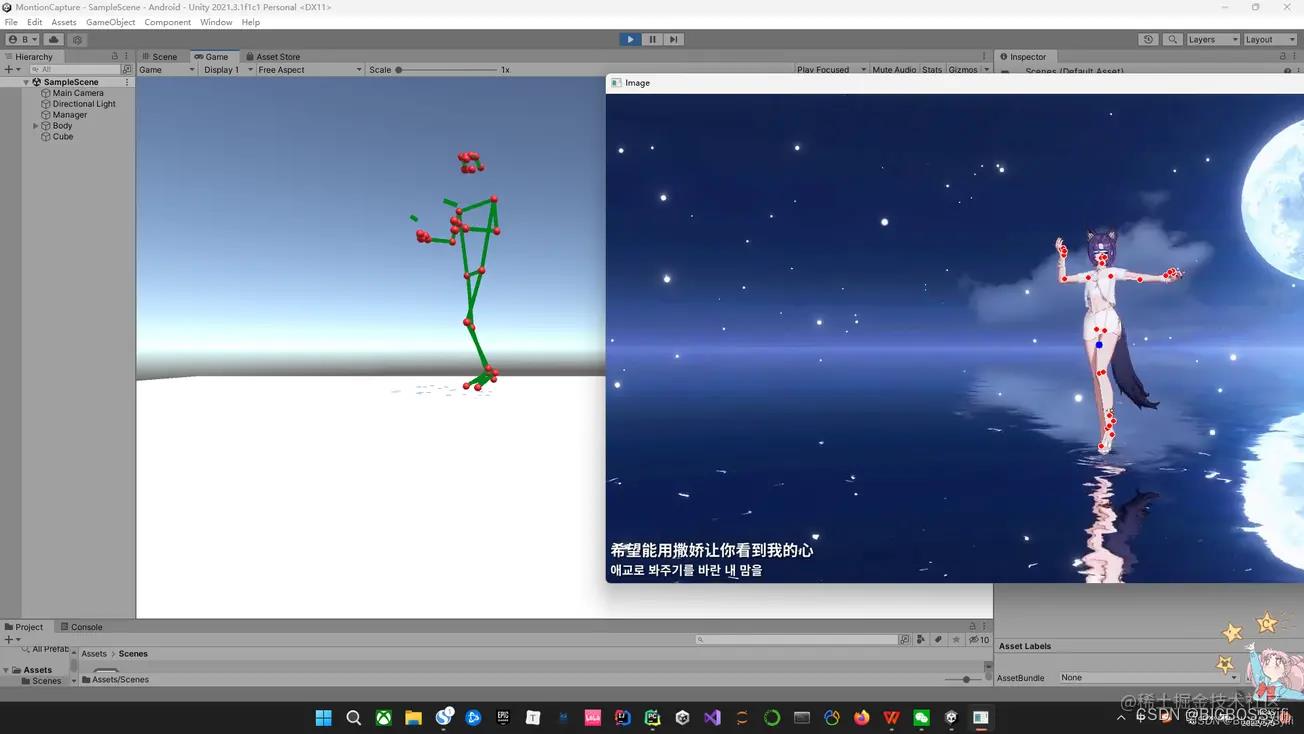
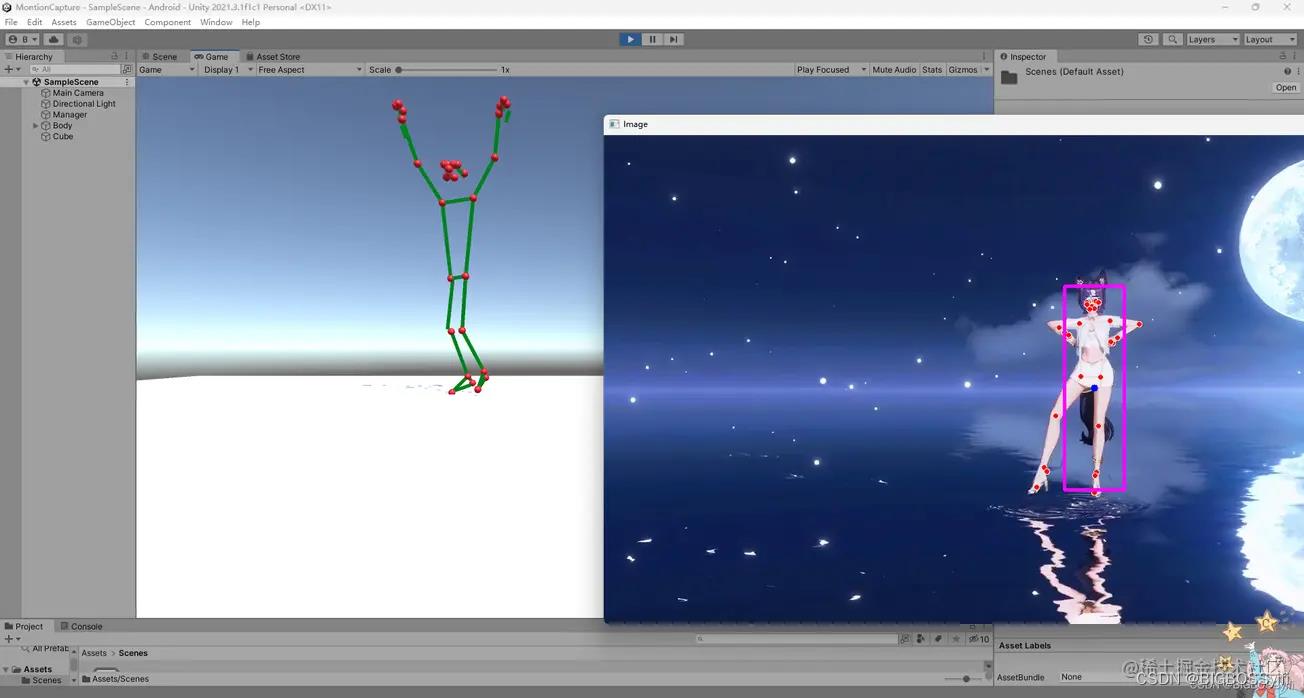
更新后效果
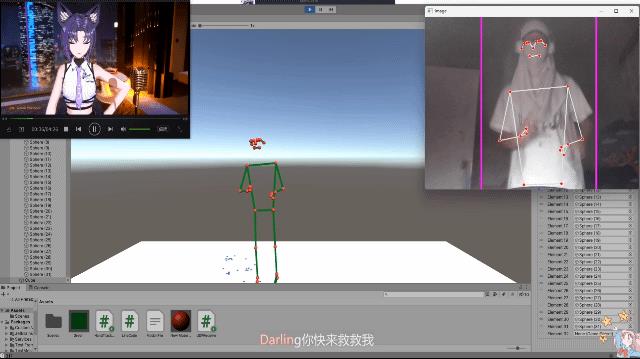
可以和珈乐同步互动…
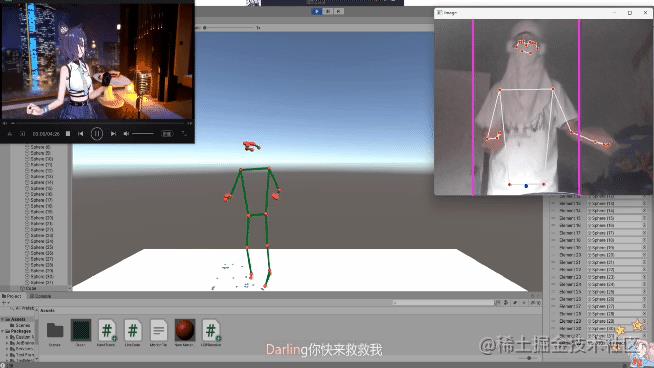
本篇文章所用的技术会整理后开源,后续可以持续关注:
项目地址:https://github.com/BIGBOSS-dedsec/OpenCV-Unity-To-Build-3DPerson
GitHub:https://github.com/BIGBOSS-dedsec
CSDN: https://blog.csdn.net/weixin_50679163?type=edu
同时本篇文章实现的技术参加了稀土掘金2022编程挑战赛-游戏赛道-优秀奖
作品展示:https://hackathon2022.juejin.cn/#/works/detail?unique=WJoYomLPg0JOYs8GazDVrw
认识Mediapipe
项目的实现,核心是强大的Mediapipe ,它是google的一个开源项目:
| 功能 | 详细 |
|---|---|
| 人脸检测 FaceMesh | 从图像/视频中重建出人脸的3D Mesh |
| 人像分离 | 从图像/视频中把人分离出来 |
| 手势跟踪 | 21个关键点的3D坐标 |
| 人体3D识别 | 33个关键点的3D坐标 |
| 物体颜色识别 | 可以把头发检测出来,并图上颜色 |
Mediapipe Dev
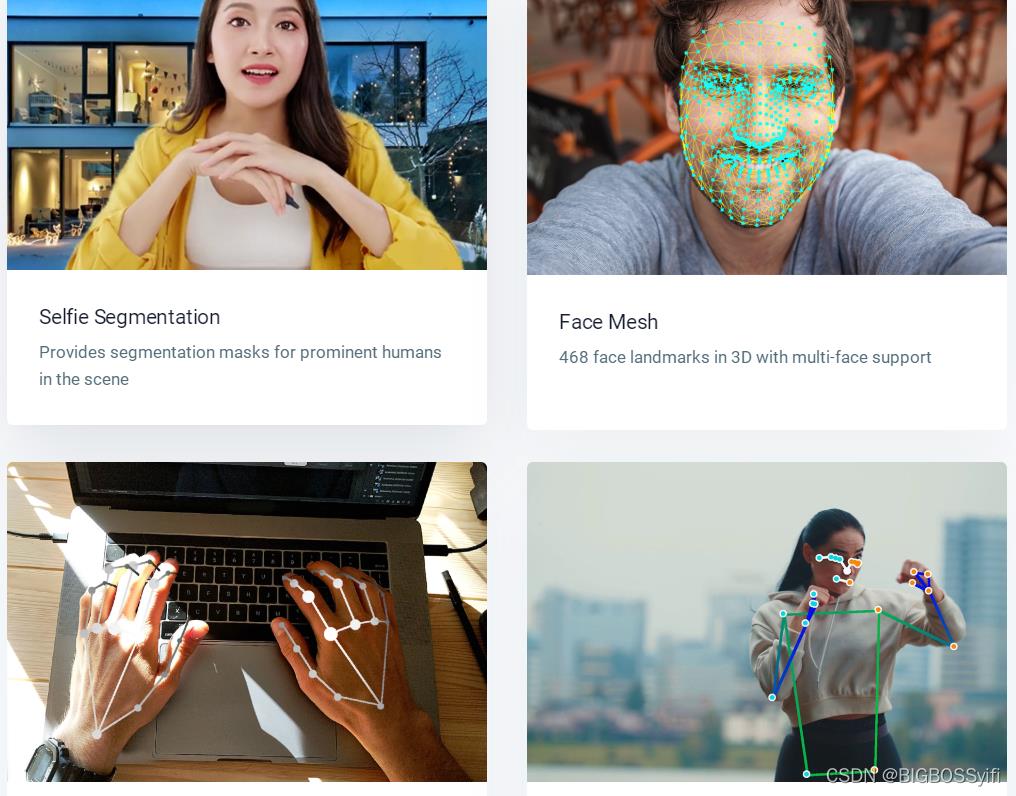
以上是Mediapipe的几个常用功能 ,这几个功能我们会在后续一一讲解实现
Python安装Mediapipe
pip install mediapipe==0.8.9.1
也可以用 setup.py 安装
https://github.com/google/mediapipe
项目环境
Python 3.7
Mediapipe 0.8.9.1
Numpy 1.21.6
OpenCV-Python 4.5.5.64
OpenCV-contrib-Python 4.5.5.64
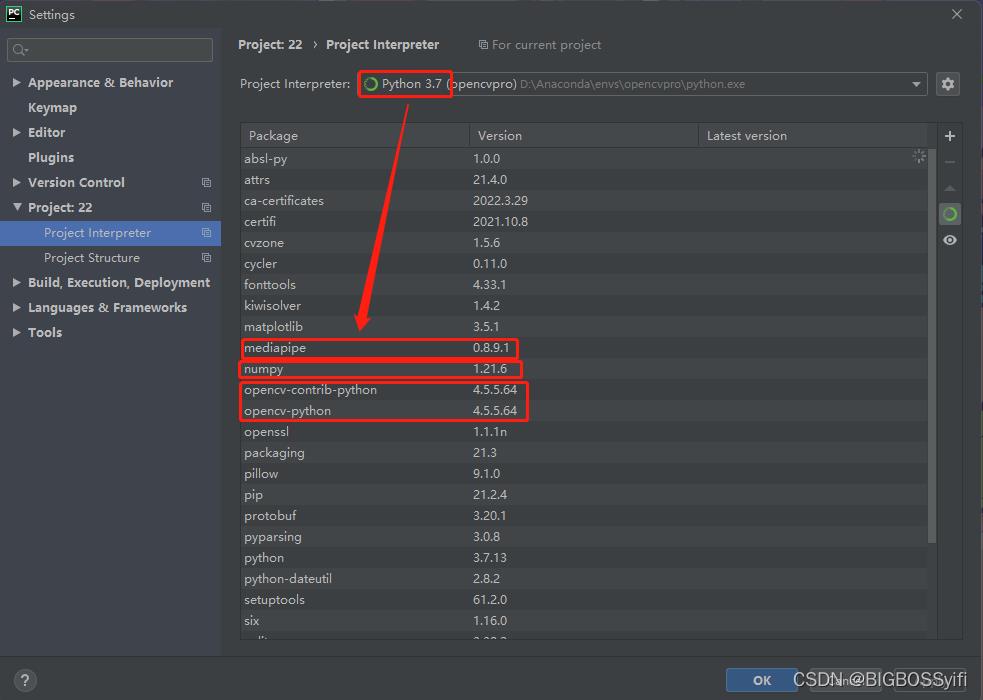
实测也支持Python3.8-3.9
身体动作捕捉部分
身体数据文件
这部分是我们通过读取视频中人物计算出每个特征点信息进行数据保存,这些信息很重要,后续在untiy中导入这些动作数据

关于身体特征点
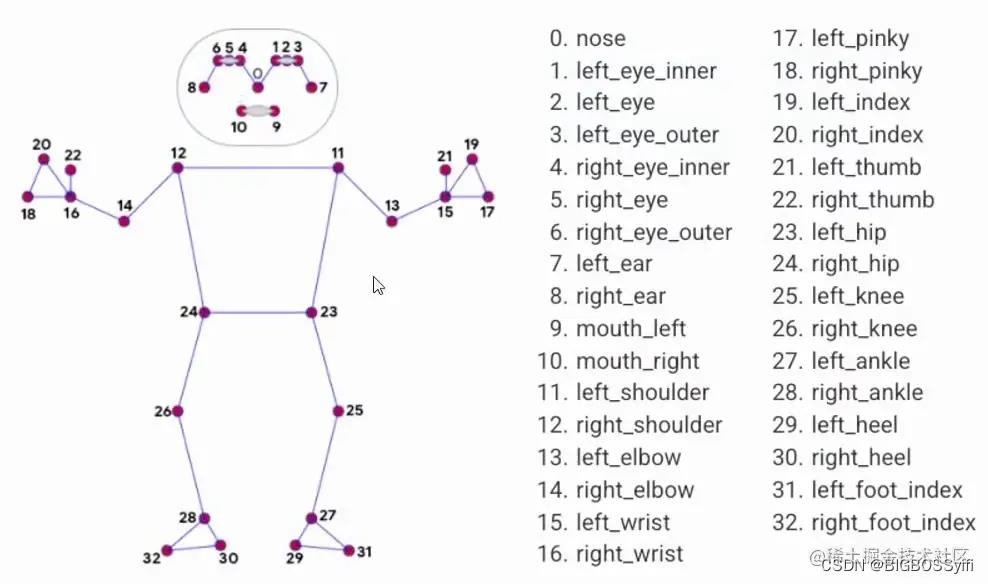
核心代码
摄像头捕捉部分:
import cv2
cap = cv2.VideoCapture(0) #OpenCV摄像头调用:0=内置摄像头(笔记本) 1=USB摄像头-1 2=USB摄像头-2
while True:
success, img = cap.read()
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #cv2图像初始化
cv2.imshow("HandsImage", img) #CV2窗体
cv2.waitKey(1) #关闭窗体
视频帧率计算
import time
#帧率时间计算
pTime = 0
cTime = 0
while True
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3,
(255, 0, 255), 3) #FPS的字号,颜色等设置
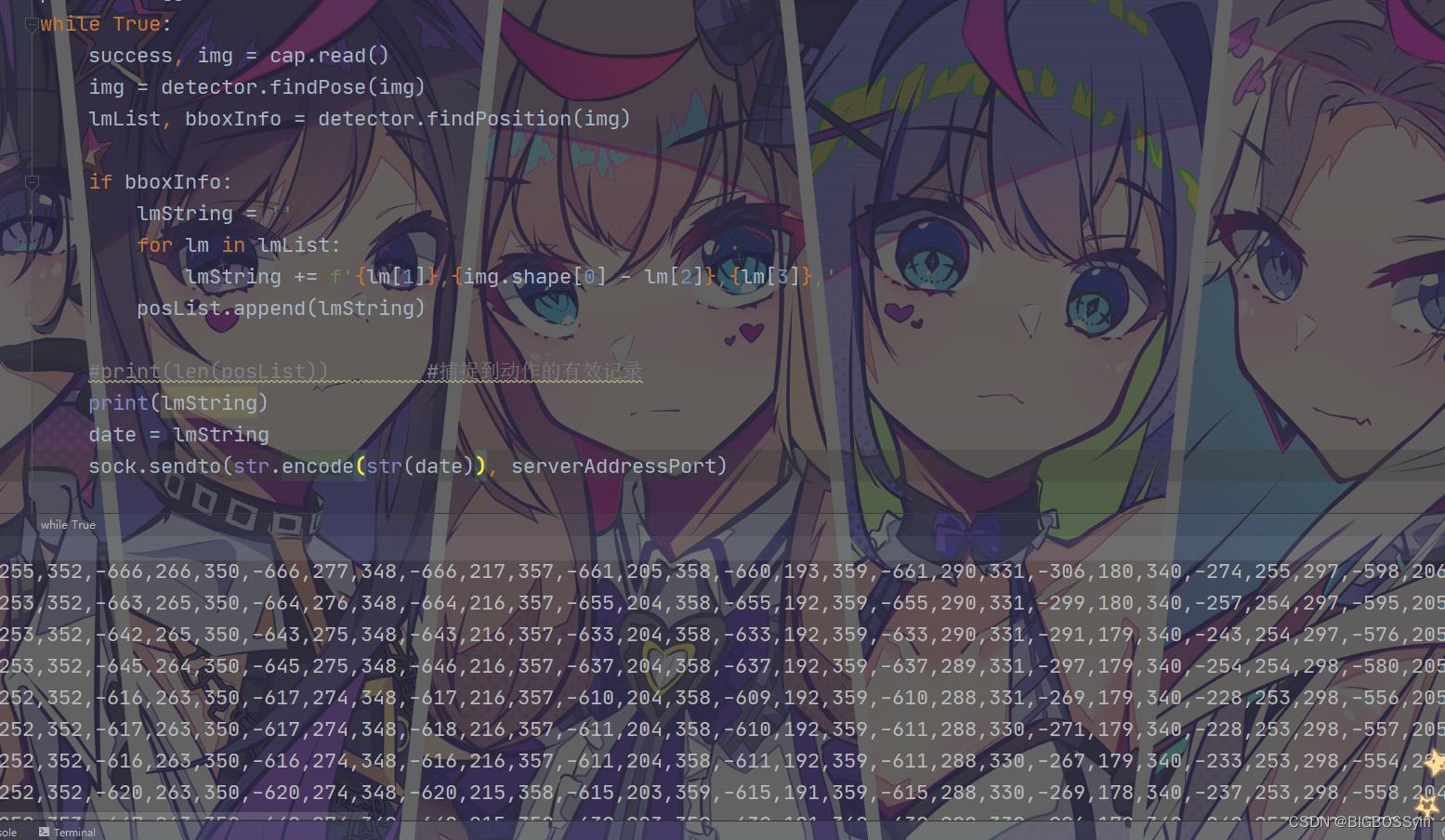
身体动作捕捉:
while True:
if bboxInfo:
lmString = ''
for lm in lmList:
lmString += f'lm[1],img.shape[0] - lm[2],lm[3],'
posList.append(lmString)
数据传输:
# 定义localhost和端口
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
serverAddressPort = ("127.0.0.1", 5054)
# 数据发送
date = lmString
sock.sendto(str.encode(str(date)), serverAddressPort)
完整代码
MotionCapPRO.py
import cv2
from cvzone.PoseModule import PoseDetector
import socket
# cap = cv2.VideoCapture('1.mp4')
cap = cv2.VideoCapture(0)
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
serverAddressPort = ("127.0.0.1", 5054) # 定义localhost与端口,当然可以定义其他的host
detector = PoseDetector()
posList = [] # 保存到txt在unity中读取需要数组列表
while True:
success, img = cap.read()
img = detector.findPose(img)
lmList, bboxInfo = detector.findPosition(img)
if bboxInfo:
lmString = ''
for lm in lmList:
lmString += f'lm[1],img.shape[0] - lm[2],lm[3],'
posList.append(lmString)
# print(len(posList))
print(lmString)
date = lmString
sock.sendto(str.encode(str(date)), serverAddressPort)
cv2.imshow("Image", img)
key = cv2.waitKey(1)
# 记录数据到本地
# if key == ord('r'):
with open("MotionData.txt", 'w') as f:
f.writelines(["%s\\n" % item for item in posList])
运行效果

Unity 部分
建模
在Unity中,我们需要搭建一个人物的模型,这里需要一个33个Sphere作为身体的特征点和33个Cube作为中间的支架
具体文件目录如下:
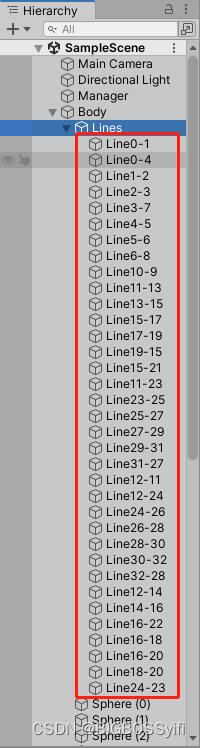
Line的编号对应人物模型特征点
UPD.cs (用于接收端口数据)
using UnityEngine;
using System;
using System.Text;
using System.Net;
using System.Net.Sockets;
using System.Threading;
public class UDPReceive : MonoBehaviour
Thread receiveThread;
UdpClient client;
public int port = 5052;
public bool startRecieving = true;
public bool printToConsole = false;
public string data;
public void Start()
receiveThread = new Thread(
new ThreadStart(ReceiveData));
receiveThread.IsBackground = true;
receiveThread.Start();
private void ReceiveData()
client = new UdpClient(port);
while (startRecieving)
try
IPEndPoint anyIP = new IPEndPoint(IPAddress.Any, 0);
byte[] dataByte = client.Receive(ref anyIP);
data = Encoding.UTF8.GetString(dataByte);
if (printToConsole) print(data);
catch (Exception err)
print(err.ToString());
(水印是我的,非盗用)
Line.cs
这里是每个Line对应cs文件,实现功能:使特征点和Line连接在一起
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class LineCode : MonoBehaviour
LineRenderer lineRenderer;
public Transform origin;
public Transform destination;
void Start()
lineRenderer = GetComponent<LineRenderer>();
lineRenderer.startWidth = 0.1f;
lineRenderer.endWidth = 0.1f;
// 连接两个点
void Update()
lineRenderer.SetPosition(0, origin.position);
lineRenderer.SetPosition(1, destination.position);
Action.cs
这里是读取上文识别并保存的人物动作数据,并将每个子数据循环遍历到每个Sphere点,使特征点随着视频中人物动作运动
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class body : MonoBehaviour
// Start is called before the first frame update
public UDPReceive udpReceive;
public GameObject[] bodyPoints;
void Start()
// Update is called once per frame
void Update()
string data = udpReceive.data;
// data = data.Remove(0, 1);
// data = data.Remove(data.Length - 1, 1);
print(data);
string[] points = data.Split(',');
print(points[0]);
//0 1*3 2*3
//x1,y1,z1,x2,y2,z2,x3,y3,z3
for (int i = 0; i < 32; i++)
float x = float.Parse(points[0 + (i * 3)]) / 100;
float y = float.Parse(points[1 + (i * 3)]) / 100;
float z = float.Parse(points[2 + (i * 3)]) / 300;
bodyPoints[i].transform.localPosition = new Vector3(x, y, z);
最终实现效果
这里的视频与Unity运行有延时
后记
利用这一技术,后期可以开发出更多有意思的玩法,虽然比赛已经结束(也取得一个自己比较满意的成果),但是我的作品更新不会结束,我会一直完善下去,直到成为一款优秀的ASOUL游戏作品!坚持下去的所有动力都是对ASOUL的热爱,永远的五人团—“我们是AAAAAASOULLLLLLL!!!”
Good Luck,Have Fun and Happy Coding!!!
以上是关于基于Mediapipe与Unity的人体姿态捕捉系统的主要内容,如果未能解决你的问题,请参考以下文章