Pytoch Note17 优化算法3 Adagrad算法
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytoch Note17 优化算法3 Adagrad算法相关的知识,希望对你有一定的参考价值。
Pytoch Note17 优化算法3 Adagrad算法
全部笔记的汇总贴:Pytorch Note 快乐星球
Adagrad 算法
在前面,我们能够根据误差函数的斜率调整我们的更新并反过来加速 SGD,接着我们还希望可以根据参数的重要性而对不同的参数进行不同程度的更新。
这个算法就可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性,例如识别 Youtube 视频里面的猫,训练 GloVe word embeddings,因为它们都是需要在低频的特征上有更大的更新。
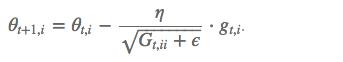
其中 g g g为:t时刻参数 θ i \\theta_i θi的梯度
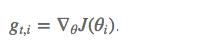
如果是普通的 SGD, 那么 θ i \\theta_i θi在每一时刻的梯度更新公式为:
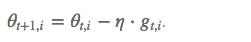
但这里的 learning rate η 也随 t 和 i 而变:
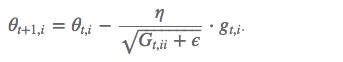
其中 G t G_t Gt是个对角矩阵, (i,i) 元素就是 t 时刻参数 θ i θ_i θi 的梯度平方和。
自适应学习率
其实再简单来说,想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上,然后在更新这个参数的时候,学习率就变为
η
s
+
ϵ
\\frac{\\eta}{\\sqrt{s + \\epsilon}}
s+ϵη
这里的
ϵ
\\epsilon
ϵ 是为了数值稳定性而加上的,因为有可能
s
s
s的值为 0,那么 0 出现在分母就会出现无穷大的情况,通常
ϵ
\\epsilon
ϵ 取
1
0
−
10
10^{-10}
10−10,这样不同的参数由于梯度不同,他们对应的 s 大小也就不同,所以上面的公式得到的学习率也就不同,这也就实现了自适应的学习率。
Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那么这个参数的学习率就变大一点,使得其能够更快地更新
缺点:Adagrad 也有一些问题,因为 s 不断累加梯度的平方,所以会越来越大,导致学习率在后期会变得较小,导致收敛乏力的情况,可能无法收敛到表较好的结果,所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。
代码从0实现
我们依旧用前面的minst数据集
import numpy as np
import torch
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
from torch import nn
from torch.autograd import Variable
import time
import matplotlib.pyplot as plt
%matplotlib inline
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
# 定义 loss 函数
criterion = nn.CrossEntropyLoss()
我们根据我们的公式,手动实现我们的Adagrad算法:
def sgd_adagrad(parameters, sqrs, lr):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = sqr + param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
# 初始化梯度平方项
sqrs = []
for param in net.parameters():
sqrs.append(torch.zeros_like(param.data))
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
net.zero_grad()
loss.backward()
sgd_adagrad(net.parameters(), sqrs, 1e-2) # 学习率设为 0.01
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
epoch: 0, Train Loss: 0.402093 epoch: 1, Train Loss: 0.259254 epoch: 2, Train Loss: 0.219965 epoch: 3, Train Loss: 0.194622 epoch: 4, Train Loss: 0.176588 使用时间: 35.53398 s
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='adagrad')
plt.legend(loc='best')
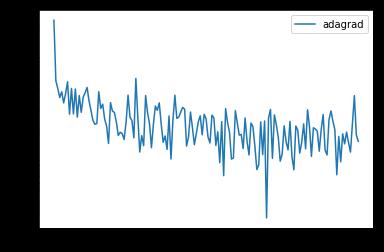
可以看到,使用自适应的学习率跑 5 个 epoch 可以得到比随机梯度下降得到更小的 loss,学习率能够自适应地降低,所以能够有着更好的效果
pytorch内置优化器
当然 pytorch 也内置了 adagrad 的优化算法,只需要调用 torch.optim.Adagrad() 就可以了,下面是例子
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
# 使用 Sequential 定义 3 层神经网络
net = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(),
nn.Linear(200, 10),
)
optimizer = torch.optim.Adagrad(net.parameters(), lr=1e-2)
# 开始训练
losses = []
idx = 0
start = time.time() # 记时开始
for e in range(5):
train_loss = 0
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
if idx % 30 == 0:
losses.append(loss.data)
idx += 1
print('epoch: {}, Train Loss: {:.6f}'
.format(e, train_loss / len(train_data)))
end = time.time() # 计时结束
print('使用时间: {:.5f} s'.format(end - start))
epoch: 0, Train Loss: 0.407681 epoch: 1, Train Loss: 0.253942 epoch: 2, Train Loss: 0.214138 epoch: 3, Train Loss: 0.187972 epoch: 4, Train Loss: 0.169992 使用时间: 29.27360 s
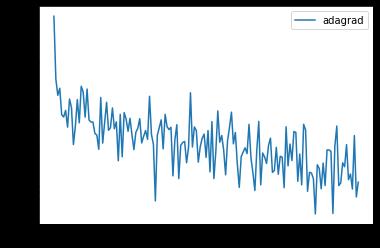
比较Compare
x_axis = np.linspace(0, 5, len(losses), endpoint=True)
plt.semilogy(x_axis, losses, label='adagrad')
plt.semilogy(x_axis, losses1, label='SGD + momentum')
plt.semilogy(x_axis, losses2, label='SGD + no momentum')
plt.legend(loc='best')
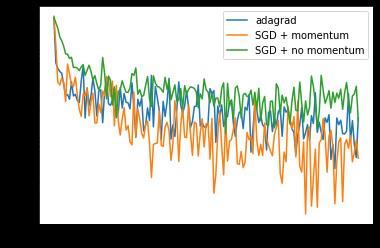
我们可以看出,Adam的自适应学习率跑 5 个 epoch 可以得到比随机梯度下降得到更小的 loss,但是似乎SGD + momentum 会降的更快。
可视化
同样对于之前的函数,我只迭代了几次,然后我的学习率设置为2,对于Adam来说,若我们设置太小的学习率,可能会需要多次迭代才能得到结果。
若学习率太小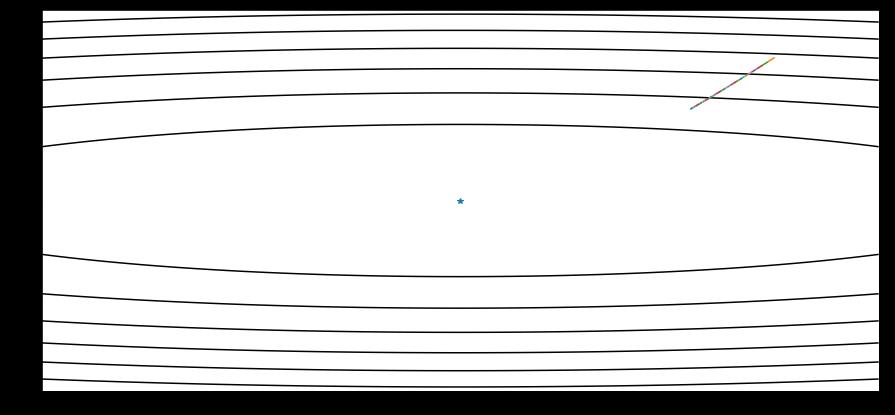
学习率如果比较大,比如1,就可以在短时间进入最优点
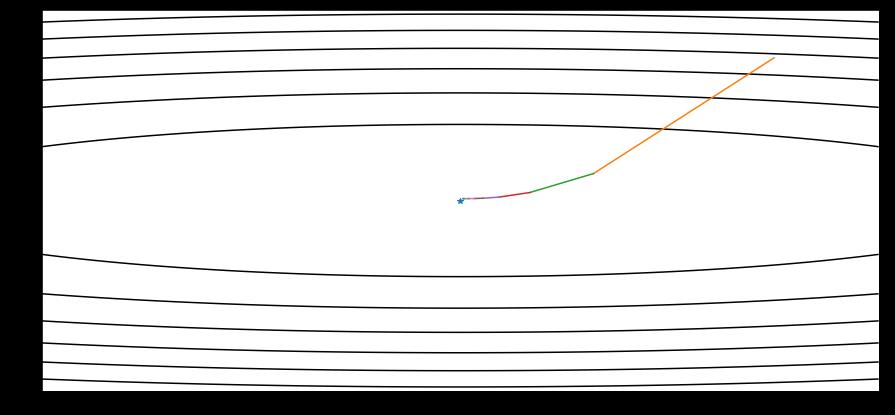
如果学习率很大,就可能会远离我们的最优解,甚至达不到
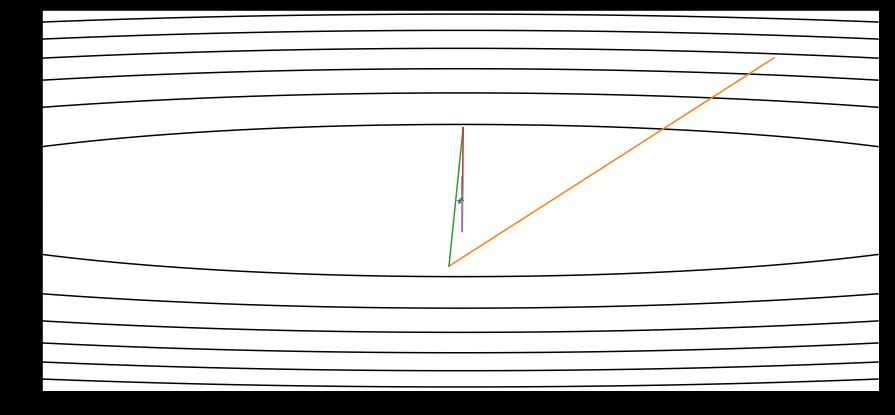
下一章传送门:Note 18 RMSprop算法
以上是关于Pytoch Note17 优化算法3 Adagrad算法的主要内容,如果未能解决你的问题,请参考以下文章
Pytorh Note19 优化算法5 Adadelta算法