Pytorch Note21 优化算法对比
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch Note21 优化算法对比相关的知识,希望对你有一定的参考价值。
Pytorch Note21 优化算法对比
全部笔记的汇总贴:Pytorch Note 快乐星球
在Note15-20中,我们介绍了多种基于梯度的参数更新方法,实际中,我们可以使用Adam作为默认的优化算法,往往能够达到比较好的效果,同时SGD+Momentum的方法也值得尝试。
下面放一张各个优化算法的对比图
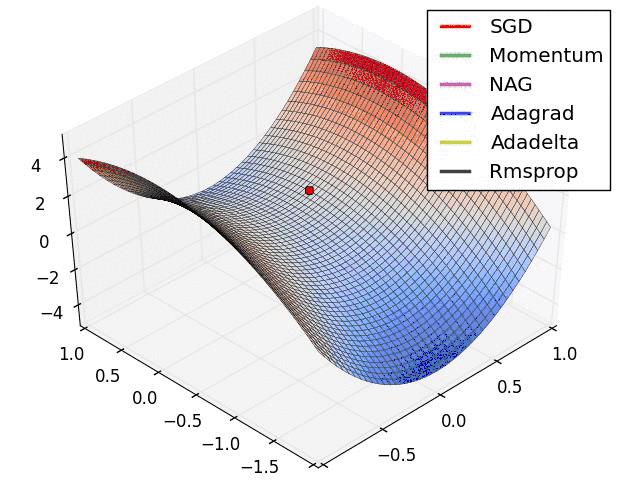
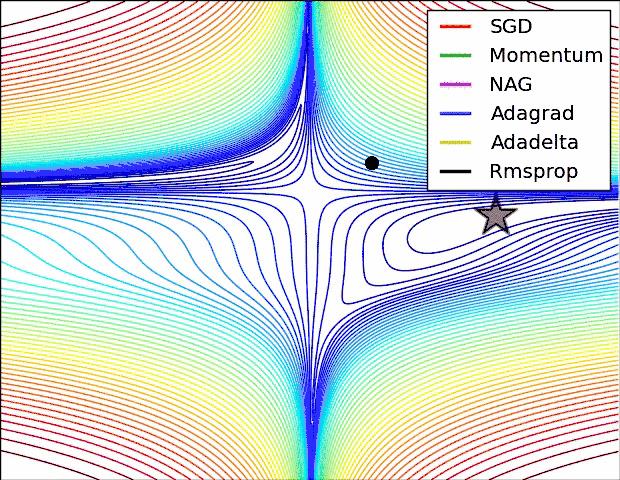
这两张图生动形象地展示了各种优化算法的实际效果,上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
如何选择优化算法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
以上是关于Pytorch Note21 优化算法对比的主要内容,如果未能解决你的问题,请参考以下文章