小白视角大数据基础实践HDFS的简单基本操作
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白视角大数据基础实践HDFS的简单基本操作相关的知识,希望对你有一定的参考价值。
HDFS的简单基本操作
1. 实验环境
⚫操作系统:Linux(Ubuntu18.04);
⚫ Hadoop版本:3.1.3;
⚫ JDK版本:1.8;
⚫ Java IDE:IDEA;
⚫ Hadoop伪分布式配置。
2. HDFS
2.1 简介
HDFS(Hadoop Distributed File System)分布式文件系统,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础。
优点:
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
局限性:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
2.2 体系结构
HDFS采用分块存储策略,以块作为存储单位,一个文件被分成多个块,默认一个块64MB。
作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上,数据块1被分别存放到数据节点A和C上,数据块2被存放在数据节点A和B上。
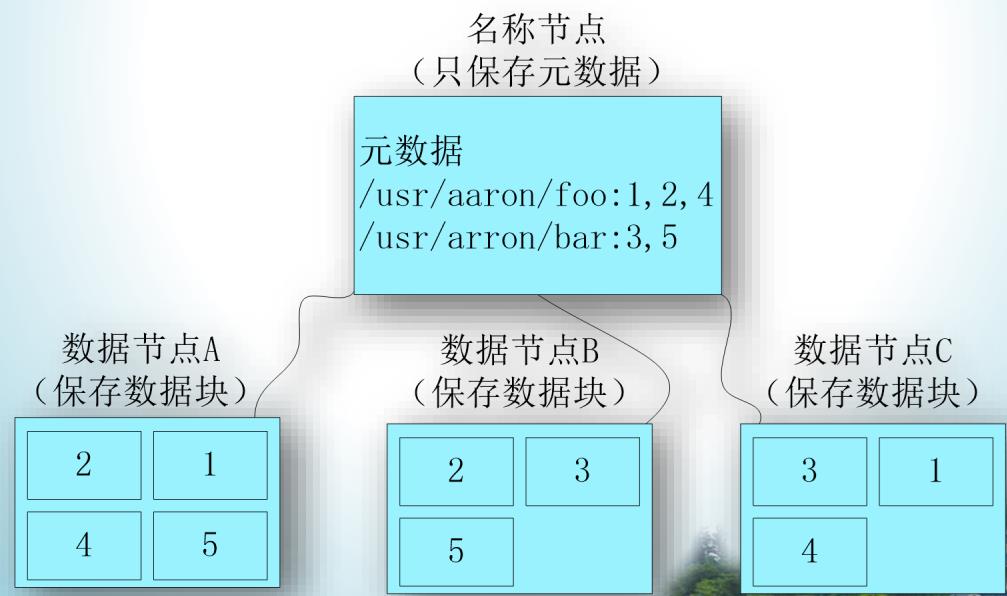
HDFS采用抽象的块概念可以带来以下几个好处:
● 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量。
● 简化系统设计:首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据。
● 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性。
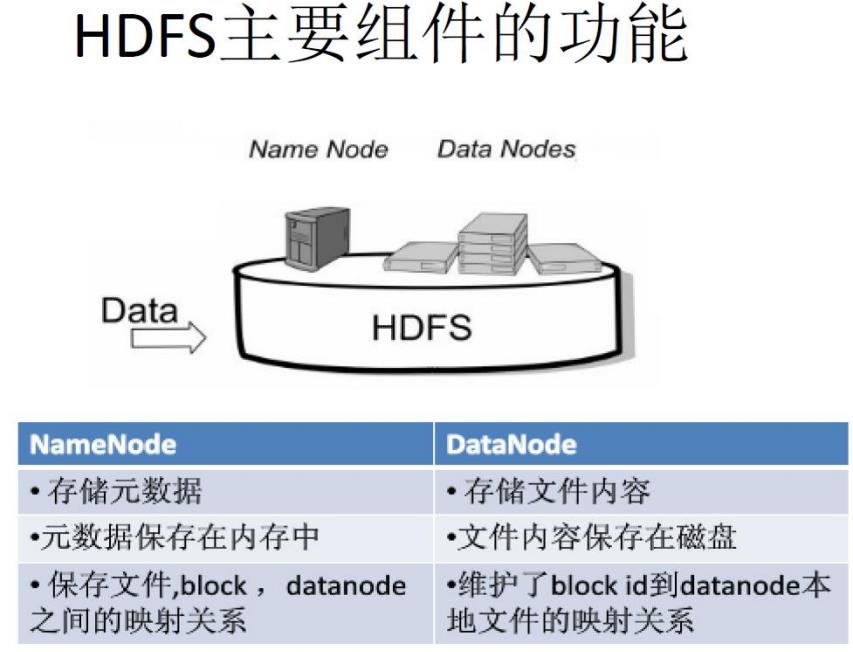
HDFS采用了主从(Master/Slave)结构模型,在物理结构上是由计算机集群中的多个节点构成的这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。当后续开启了start-dfs.sh的时候可以jps一下就知道了。
2.2.1 NameNode
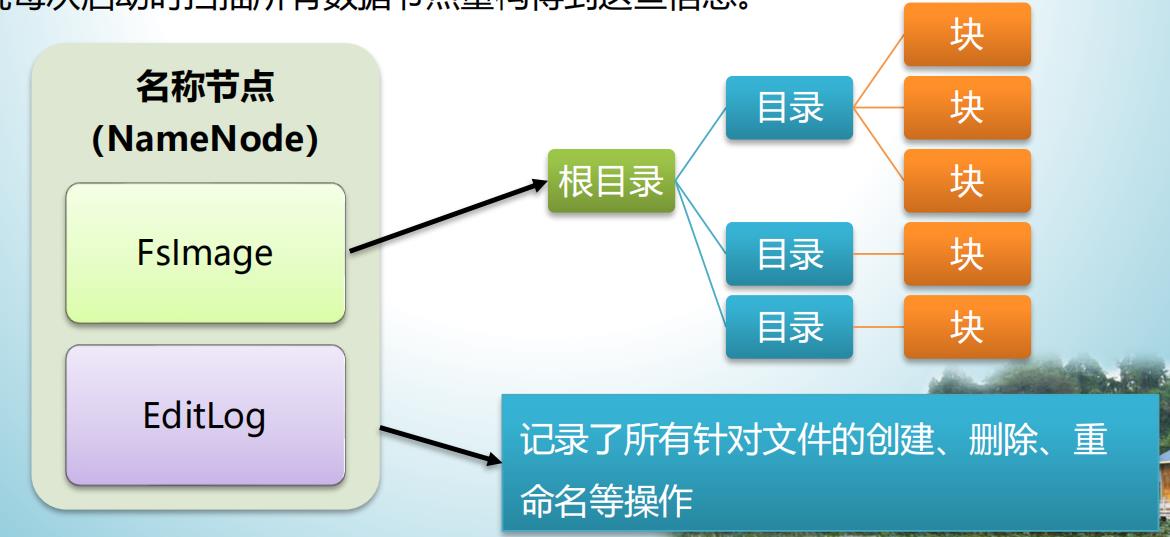
- 在HDFS中,名称节点
(NameNode)负责管理分布式文件系统的命名空间(Namespace),命名空间包含目录、文件和块,保存了两个核心的数据结构,即FsImage和EditLog。 FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据。- 操作日志文件
EditLog中记录了所有针对文件的创建、删除、重命名等操作。 - 名称节点记录了每个文件中各个块所在的数据节点的位置信息,但并不持久化存储这些信息,而是在系统每次启动时扫描所有数据节点重构得到这些信息。
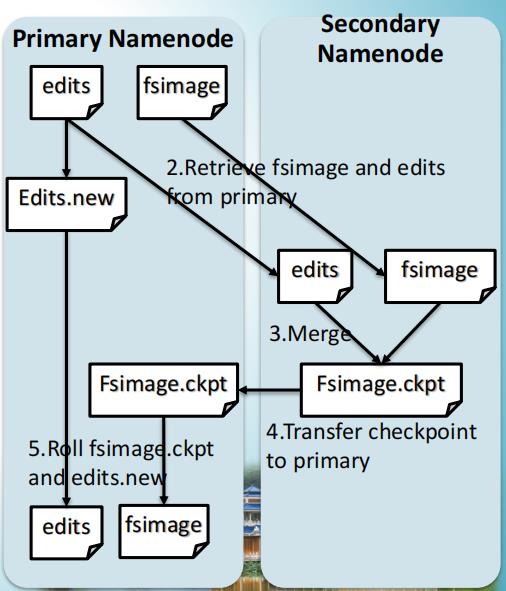
2.2.2 SecondaryNameNode
SecondaryNameNode定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;SecondaryNameNode将下载的FsImage载到内存,一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;- 执行完(3)操作之后,通过post方式将新的
FsImage文件发送到NameNode节点上。 NameNode将从SecondaryNameNode接收到的FsImage替换旧的FsImage文件,同时将edit.new替 换EditLog文件,通过这个过程EditLog就变小了。
2.2.3 DataNode
- 数据节点是分布式文件系统
HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。 - 每个数据节点中的数据会被保存在各自节点的本地
Linux文件系统中。
2.2.4 通讯协议
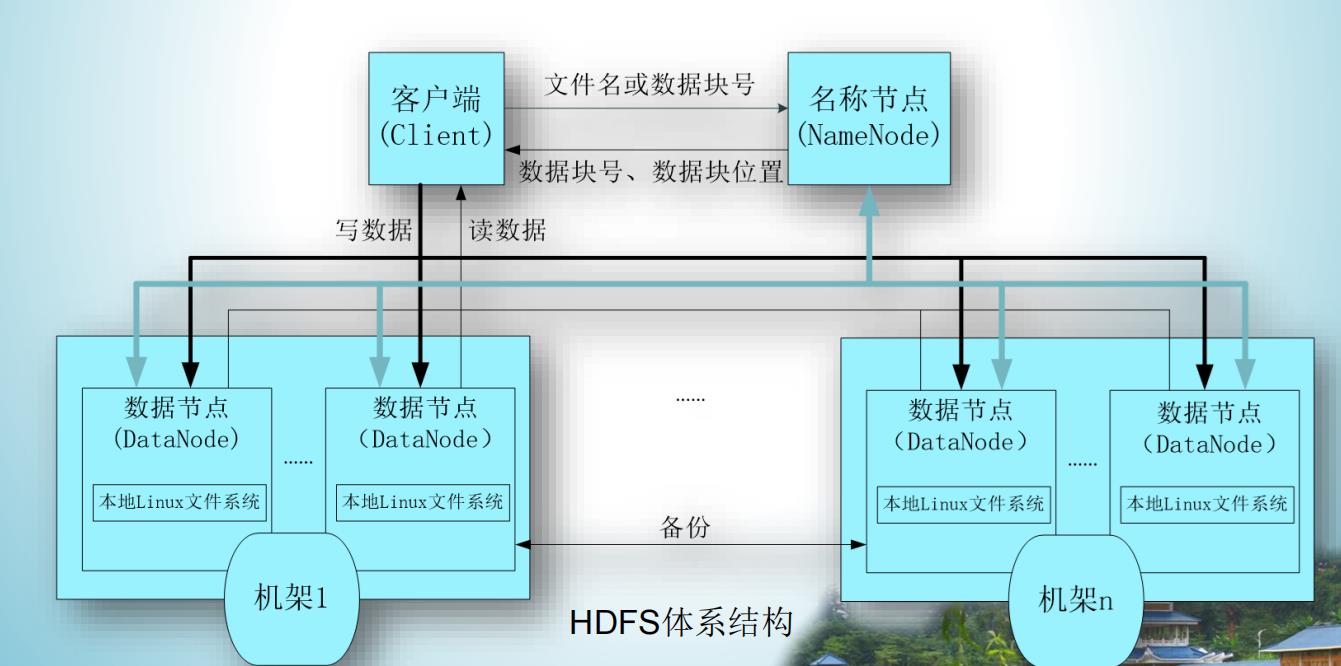
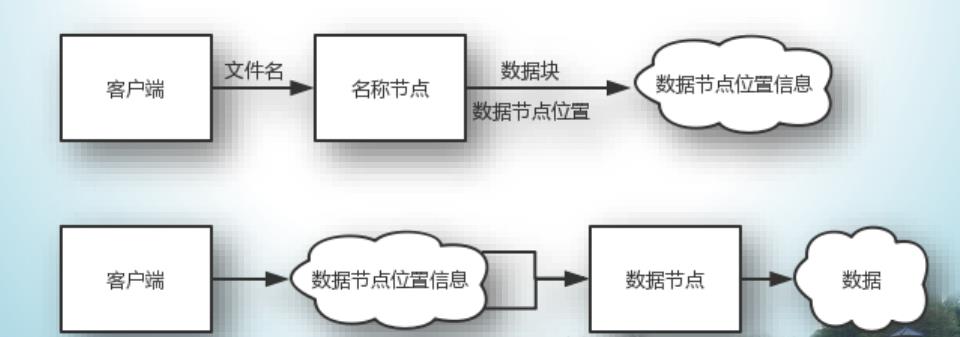
⚫ HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。
⚫ 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。
⚫ 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用ClientProtocol与名称节点进行交互。
⚫ 名称节点和数据节点之间则使用DatanodeProtocol进行交互。
⚫ 一个远程过程调用(RPC)模型被抽象出来封装ClientProtocol和Datanodeprotocol协议。
⚫ 客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
在客户端可以使用shell或是JavaApi进行HDFS的简单操作。
2.2.5 局限性
⚫ 命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
⚫ 性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
⚫ 隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。
⚫ 集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
3. 利用Shell命令HDFS进行交互
3.1 概要
- hadoop fs 适用于任何不同的文件系统,比如本地文件系统和 HDFS 文件系统:所有的的 FS shell 命令使用 URI 路径作为参数。URI 格式是 scheme://authority/path。对 HDFS文件系统,scheme 是 hdfs,对本地文件系统,scheme 是 file。
- hadoop dfs 只能适用于 HDFS 文件系统
- hdfs dfs 跟 hadoop dfs 的命令作用一样,也只能适用于 HDFS 文件系统
3.2 目录操作
创建HDFS的目录
hdfs dfs -mkdir /目录

注意要一层一层创建目录,好像不能一蹴而就。
列出HDFS的所有目录
hdfs dfs -ls

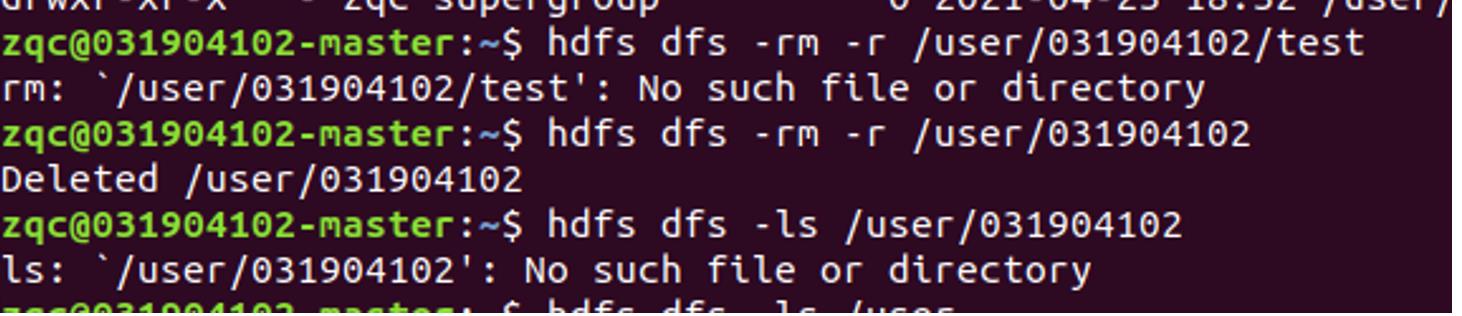
删除HDFS的目录
hdfs dfs -rm -r /目录
3.3 文件操作
文件上传
hdfs dfs -put 源路径 目的路径
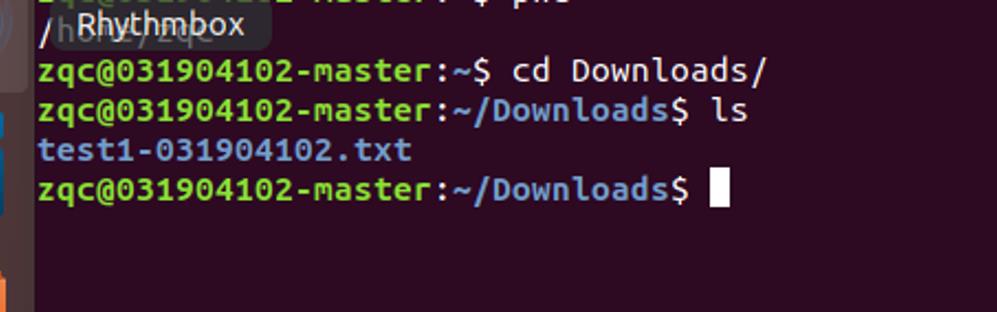
在主机里创建文件

然后上传到HDFS中

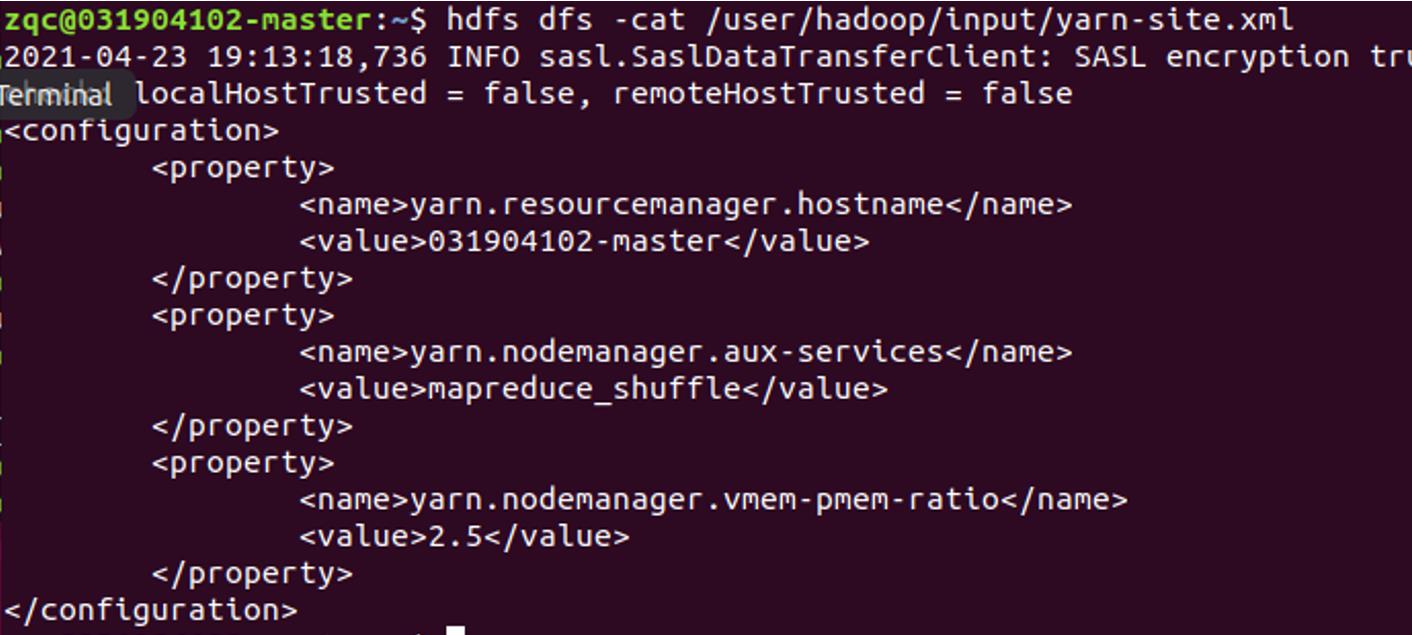
文件内容查看
hdfs dfs -cat 文件路径
文件下载
hdfs dfs -get 源文件地址 下载到的路径

查看是否下载成功
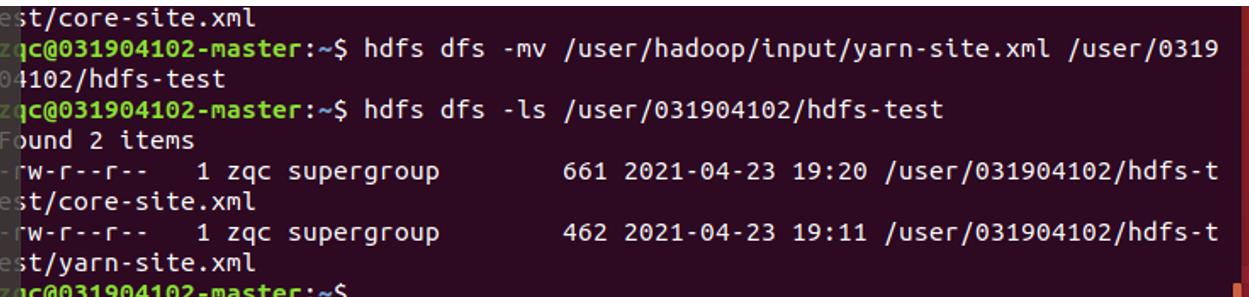
文件的移动
hdfs dfs -mv 文件路径 目的目录
文件的复制
hdfs dfs -cp 文件路径 目的目录


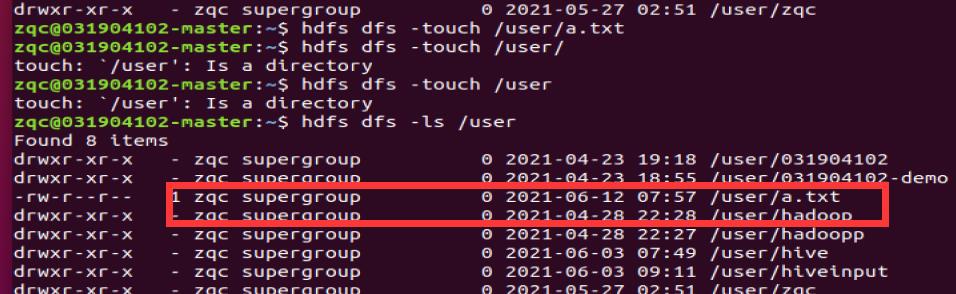
文件的创建
hdfs dfs -touch 文件路径
文件的追加
hdfs dfs -appendToFile 追加的内容文件路径 被追加的文件路径
在本地创建一个文件
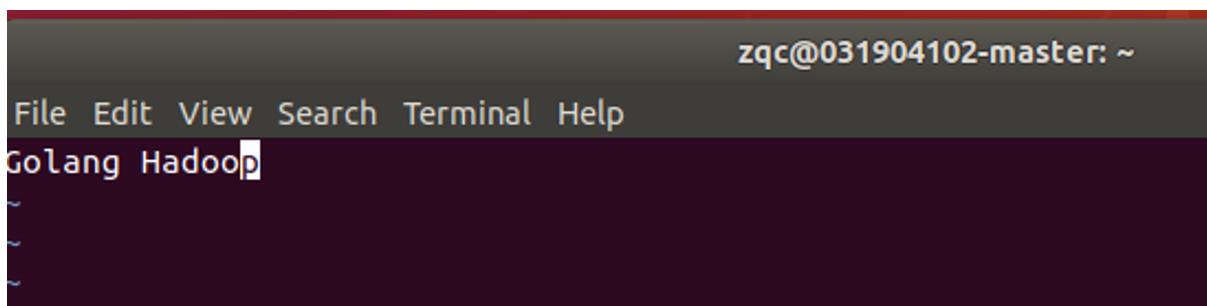
对其进行添加操作

文件查看
hdfs dfs -text 文件路径

文件删除
hdfs dfs -rm 文件路径

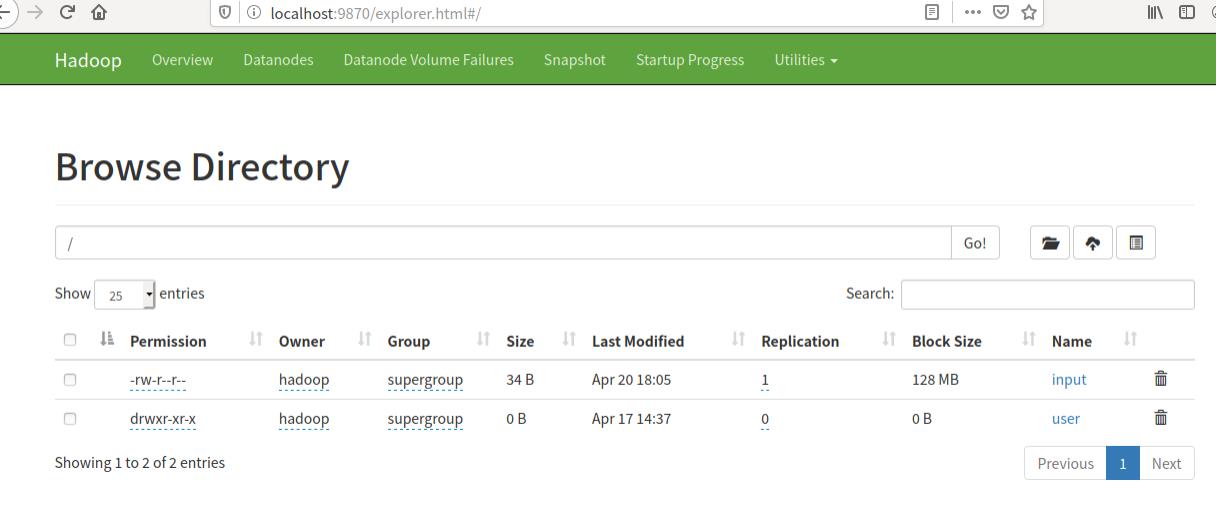
4. 利用web界面管理HDFS
访问url:http://localhost:9870
就可以看到管理页面的!应该是可以的!我没试过。
附上老师的截图
5. 使用JavaApi进行管理HDFS
5.1 导包并测试
Idea导入hadoop jar包
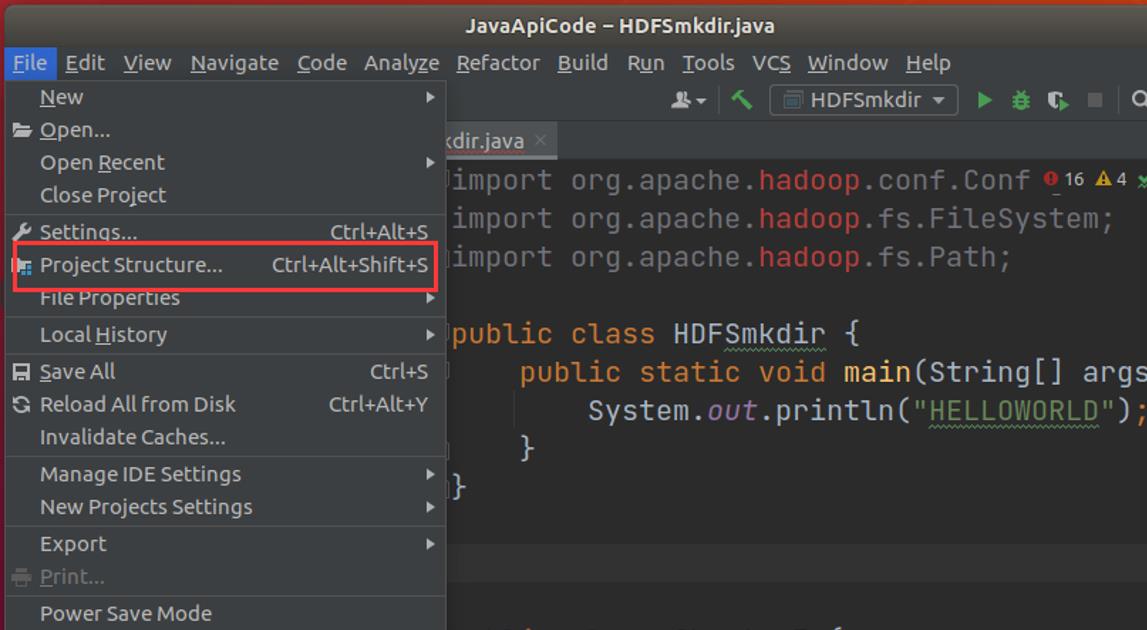
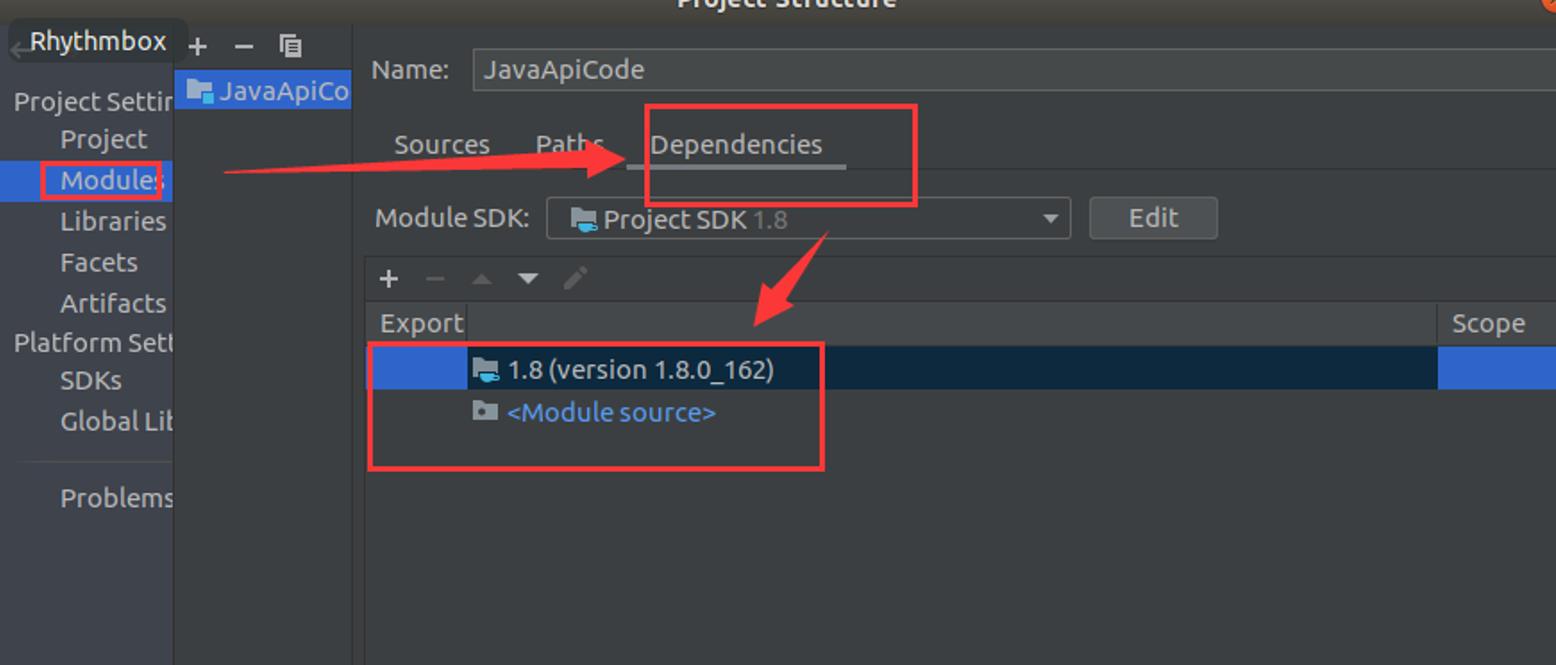
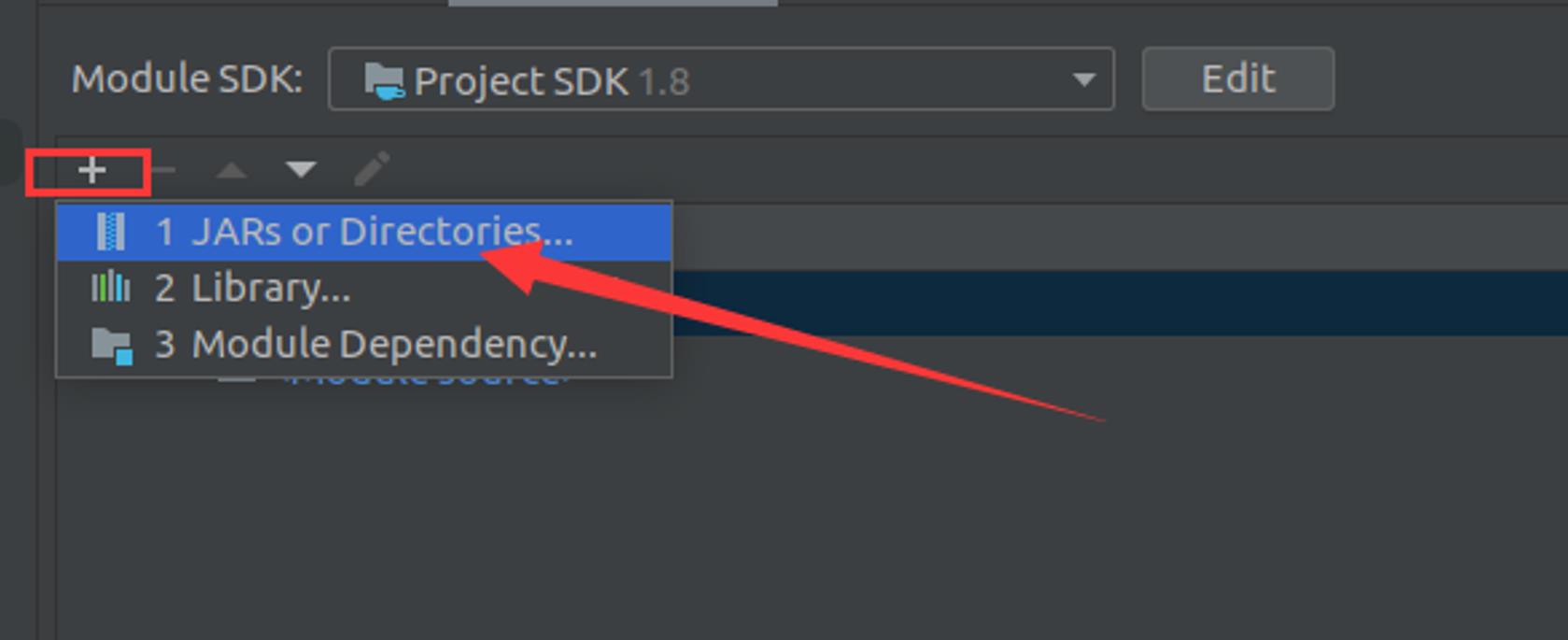
找到文件路径安装即可。
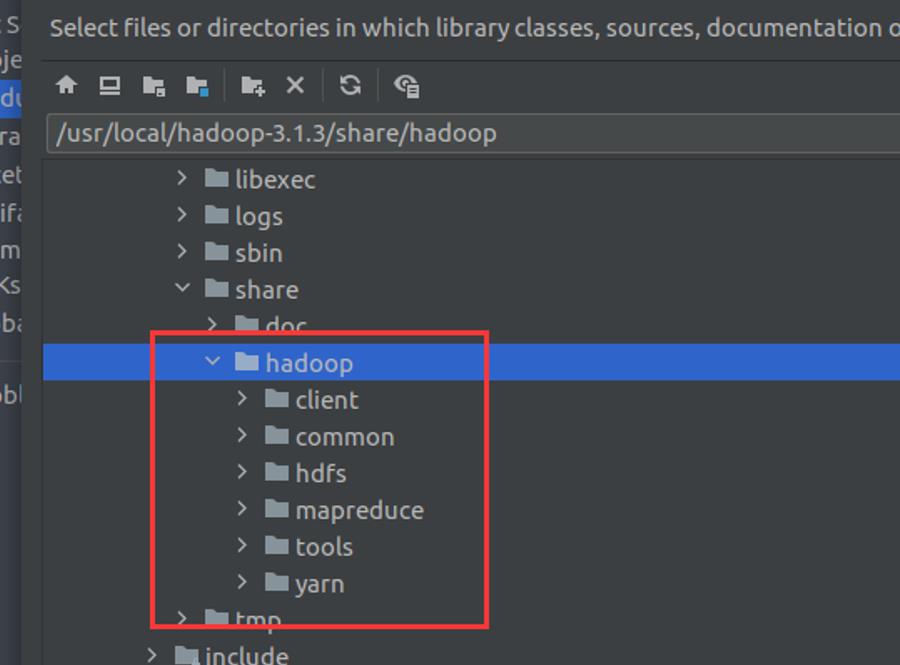
添加指定的jar文件
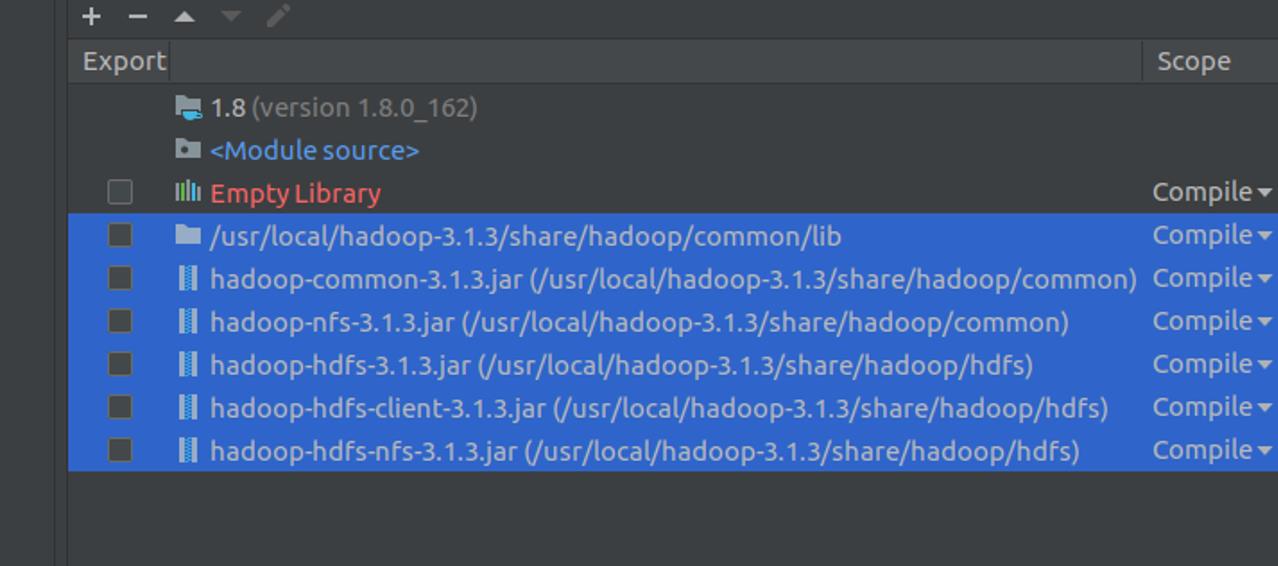
看到这里的jar包即可成功了。
测试代码
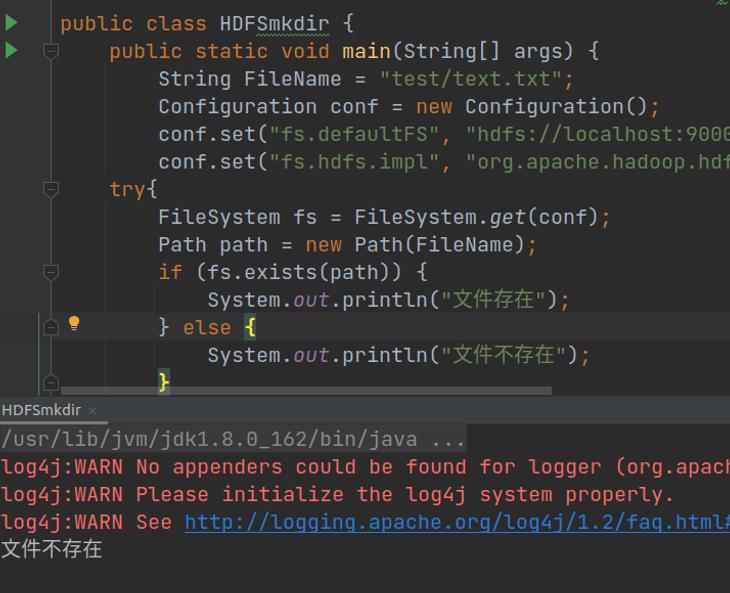
可以运行就行了!
5.2 题目
第一题
编写Java代码实现功能:判断指定文件在HDFS中是否存在,若不存在,则创建该文件,若存在,则打开文件进行内容追加;
在本地创建一个文件夹用于追加使用。
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSmkdir {
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) {
Path remotePath = new Path(remoteFilePath); //传入hdfs文件路径
try(
FileSystem fs = FileSystem.get(conf);
FileInputStream in = new FileInputStream(localFilePath);){
//new一个文件的输入流的对象,并加入需要add的文件路径
FSDataOutputStream out = fs.append(remotePath); // 将hdfs中的文件读入
byte[] data = new byte[1024];
/*
从输出流中读取一定数量的字节,并将其存储在缓冲区数组data中。返回:
读入缓冲区的总字节数;
如果因为已经到达流末尾而不再有数据可用,则返回 -1。
*/
int read = -1;
while((read = in.read(data)) > 0) {
out.write(data,0,read); // 添加hdfs文件之中
}
out.close(); // 关闭hdfs的文件
}catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new Mkdir(); //主函数new一个Mkdir对象
}
}
class Mkdir{
public Mkdir(){
String filename = "/user/hadoop/input/hdfs-site.xml"; //需要添加本地内容的文件
Configuration conf = new Configuration(); // new一个配置文件的对象
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable", "true");
/*
在进行pipeline写数据(上传数据的方式)时,
如果DN或者磁盘故障,客户端将尝试移除失败的DN,然后写到剩下的磁盘。
一个结果是,pipeline中的DN减少了。这个特性是添加新的DN到pipeline。
这是一个站点范围的选项。
*/
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");
/*
此属性仅在dfs.client.block.write.replace-datanode-on-failure.enable设置为true时有效。
ALWAYS: 总是添加新的DN
NEVER: 从不添加新的DN
DEFAULT: 设r是副本数,n是要写的DN数。在r>=3并且floor(r/2)>=n或者r>n(前提是文件是 hflushed/appended)时添加新的DN。
*/
conf.set("fs.defaultFS", "hdfs://localhost:9000");
/*
默认文件系统的名称。URI形式。uri's的scheme需要由(fs.SCHEME.impl)指定文件系统实现类。 uri's的authority部分用来指定host, port等。默认是本地文件系统。
HA方式,这里设置服务名,例如:hdfs://111111
HDFS的客户端访问HDFS需要此参数。
伪分布是这样的,如果是全分布的话,应该是你的映射名字不是localhost了。应该。
*/
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
try {
FileSystem fs = FileSystem.get(conf);
Path path = new Path(filename);
if(fs.exists(path)) {
System.out.println("File \\""+ filename +"\\" Exist!");
// 文件存在,追加内容
try {
String localFilePath = "/home/zqc/add.txt";
//需要追加的文件内容的路径
HDFSmkdir.appendToFile(conf, localFilePath, filename);
System.out.println("File Written Successfully!");
}catch(Exception e) {
e.printStackTrace();
}
}
else {
System.out.println("File \\""+ filename +"\\" Not Exist!");
fs.createNewFile(path); // 文件不存在,创建文件
System.out.println("File Created Successfully!");
}
}catch(IOException e)
{
e.printStackTrace();
}
}
}
编译器终端显示没有错误。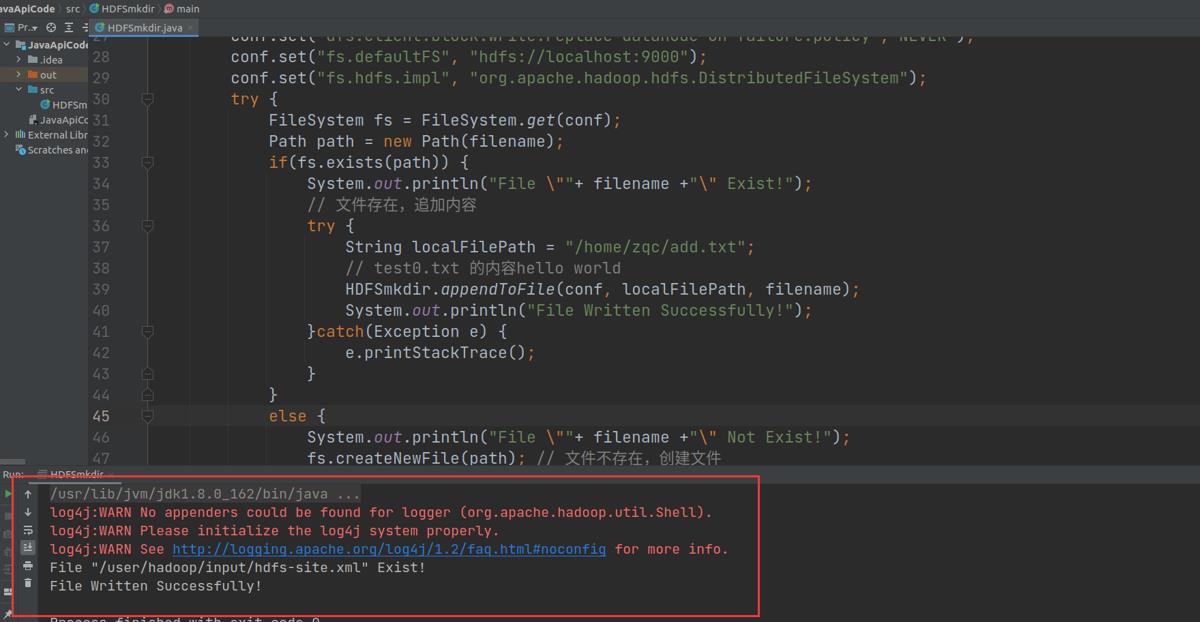
然后在shell中cat是否添加
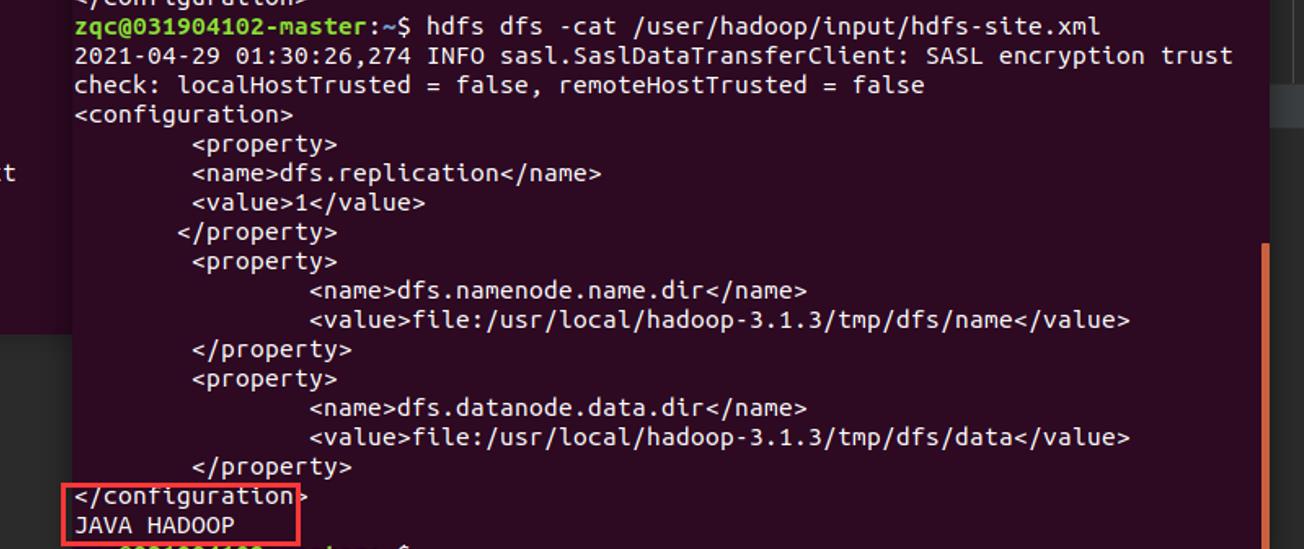
成功!追加成功!
第二题
编写Java代码实现功能:通过用户实时输入内容或本地文本内容完成HDFS文件写入操作,用户输入“exit”结束写入;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Scanner;
public class HDFSFileWritten {
public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) {
Path remotePath = new Path(remoteFilePath);
try (FileSystem fs = FileSystem.get(conf);
FileInputStream in = new FileInputStream(localFilePath);) {
FSDataOutputStream out = fs.append(remotePath);
byte[] data = new byte[1024];
int read = -1;
while ((read = in.read(data)) > 0) {
out.write(data, 0, read);
}
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new HDFSWrite();
}
}
class HDFSWrite {
public HDFSWrite() {
System.out.println("Please Choose The Way To Write");
System.out.println("1.Written On Real Time");
System.out.println("2.Written By Local File");
Scanner str = new Scanner(System.in);
String s = str.nextLine();
String filename = "/user/hadoop/input/hdfs-site.xml";
Path writtenpath = new Path(filename);
Configuration conf = new Configuration();
//配置信息都和上面的一样的!
conf.set("dfs.client.block.write.replace-datanode-on-failure.enable", "true");
conf.set("dfs.client.block.write.replace-datanode-on-failure.policy", "NEVER");
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
if (s.equals("1")) { //如果选择了1的话,就是自己输入
System.out.println("Please Input The Content You Want To Append:");
Scanner scanner = new Scanner(System.in);
String string;
try { //一个死循环
while (true) {
FileSystem fs = FileSystem.get(conf);
FSDataOutputStream fsdataoutput = fs.append(writtenpath);
string = scanner.nextLine();
if (string.equals("exit")) { //如果输入是exit就退出
System.out.println("APPEND SUCCESSFULLY");
break;
}
try { // 不然的话就是输入输入文件的内容
fsdataoutput.write(string.getBytes());
fsdataoutput.flush();
fsdataoutput.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
if (s.equals("2")) { //如果是2的话就直接添加
try {
String localFilePath = "/home/zqc/add.txt";
HDFSFileWritten.appendToFile(conf, localFilePath, filename);
System.out.println("APPEND SUCCESSFULLY");
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
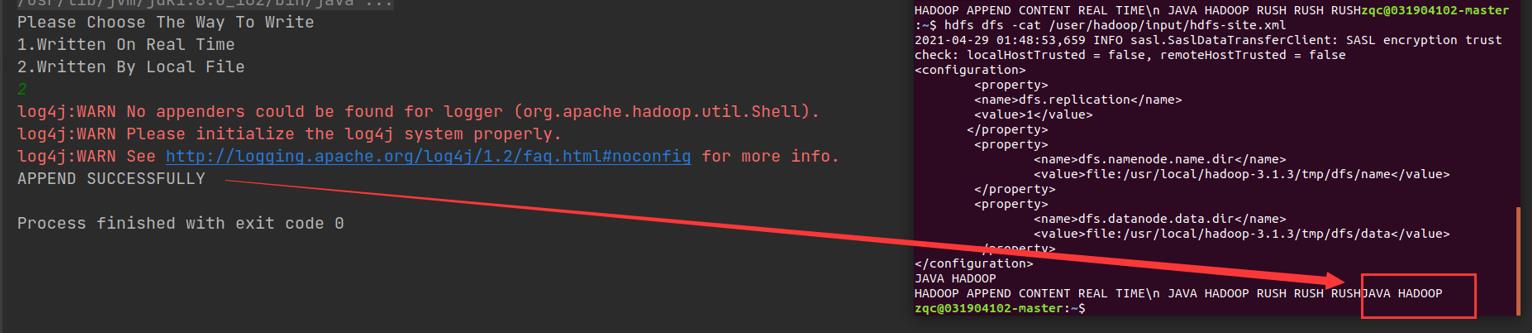
添加成功了。
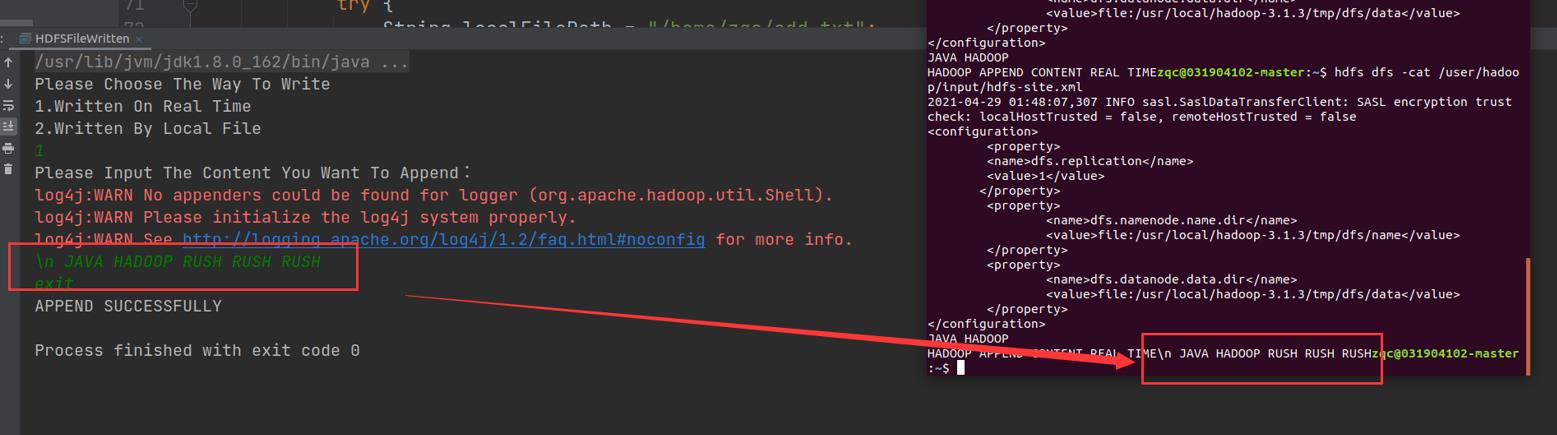
本地文件内容为JAVA HADOOP 添加成功。
第三题
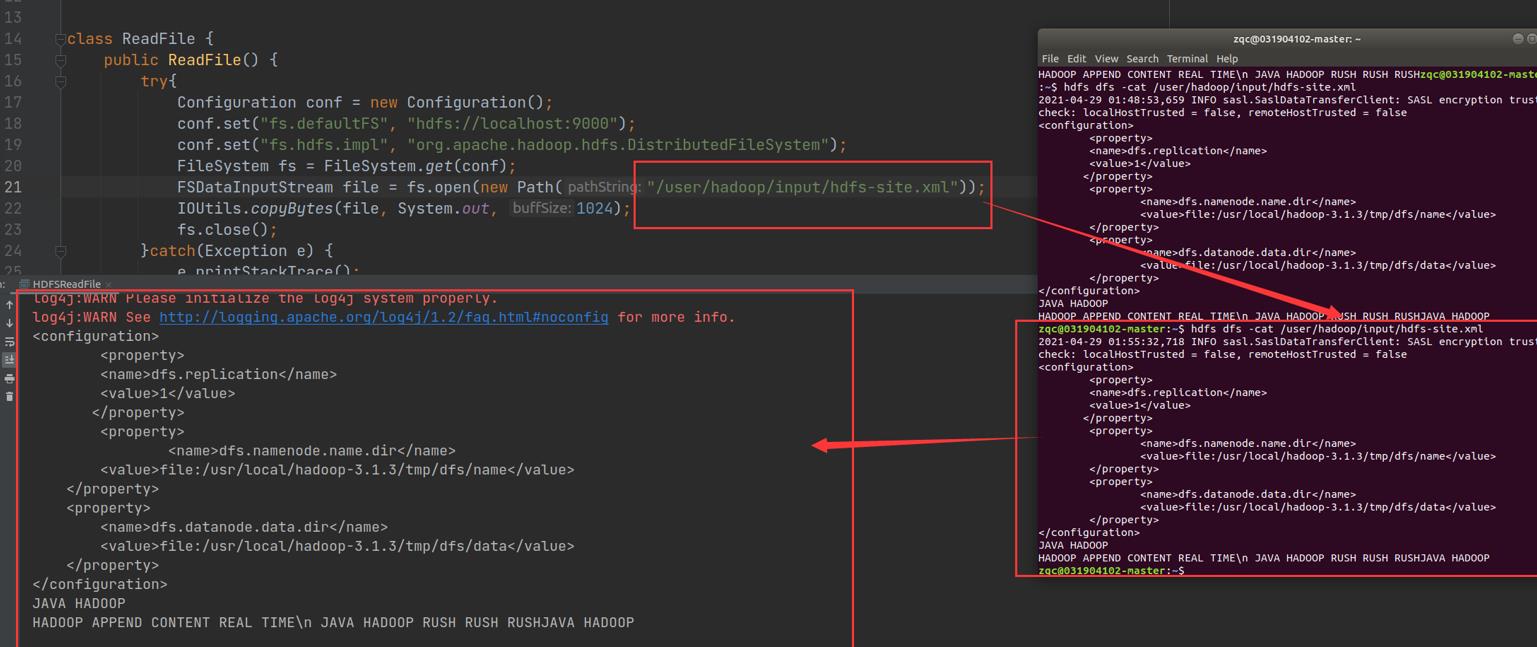
编写Java代码实现功能:读取HDFS上的文件的内容并输出到控制台
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSReadFile {
public static void main(String[] args) {
new ReadFile();
}
}
class ReadFile {
public ReadFile() {
try{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream file = fs.open(new Path("/user/hadoop/input/hdfs-site.xml"));
IOUtils.copyBytes(file, System.out, 1024);
fs.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
6. 在集群上运行
-
导出为jar包
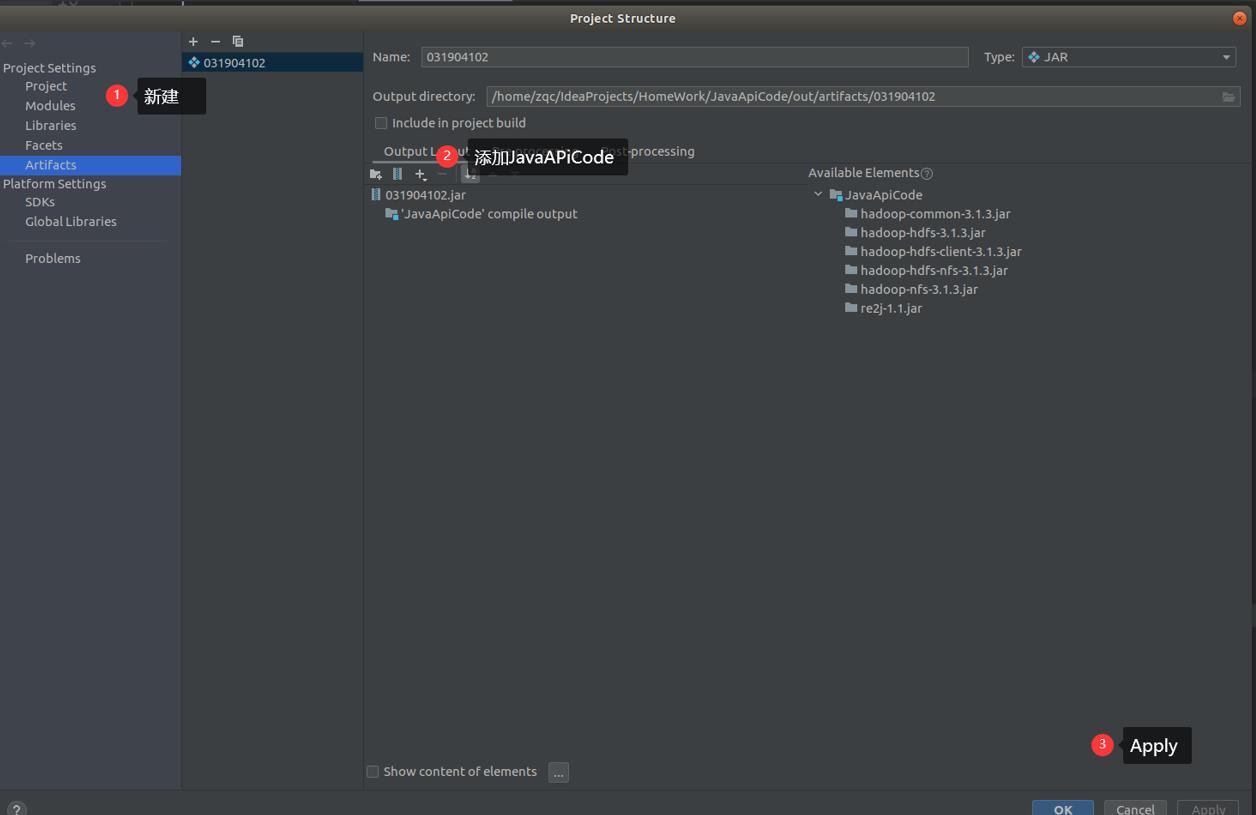
-
点击这里,然后build
 小白视角大数据基础实践 MapReduce编程基础操作
小白视角大数据基础实践 MapReduce编程基础操作