大数据小白系列——HDFS
Posted 程序员杂书馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据小白系列——HDFS相关的知识,希望对你有一定的参考价值。
【注1:结尾福利】
【注2:这里是大数据小白系列,这是本系列的第二篇,介绍HDFS中SecondaryNameNode、单点失败(SPOF)、以及高可用(HA)等概念。】
上一篇我们说到了大数据、分布式存储,以及HDFS中的一些基本概念,为了能更好的理解后续介绍的内容,这里先补充介绍一下NameNode到底是怎么存储元数据的。
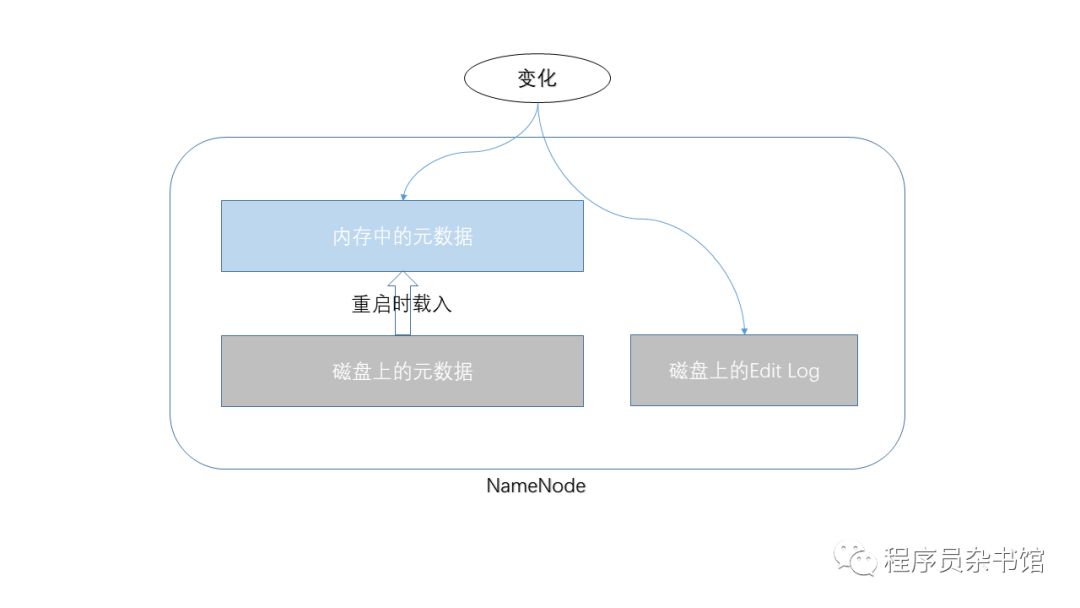
首先,在启动的时候,将磁盘中的元数据文件读取到内存,后续所有变化将被直接写入内存,同时被写入一个叫Edit Log的磁盘文件。(如果你熟悉关系型数据库,这个Edit Log有点像Oracle Redo Log,这是题外话)。
Q: 为什么不把这些变化直接写到磁盘上的元数据中,使磁盘上的元数据保持最新呢?Edit Log是不是多此一举?
A: 这个主要是基于性能考虑,由于对EditLog的写是“顺序写”(追加),对元数据的写是“随机写”,两者在磁盘上表现出来的性能有相当大的差异。有兴趣的同学可以搜索学习一下磁盘相关原理哦。
上面这个方案,带来了一些明显的副作用。
NameNode长期运行,不停地向EditLog追加内容,导致它变得巨大无比。
NameNode在重启时,需要使用EditLog更新元数据文件,当Edit Log太大时,这一步骤就会耗费很长的时间。
为了消除这些副作用,HDFS中引入了另外一个角色,SecondaryNameNode。
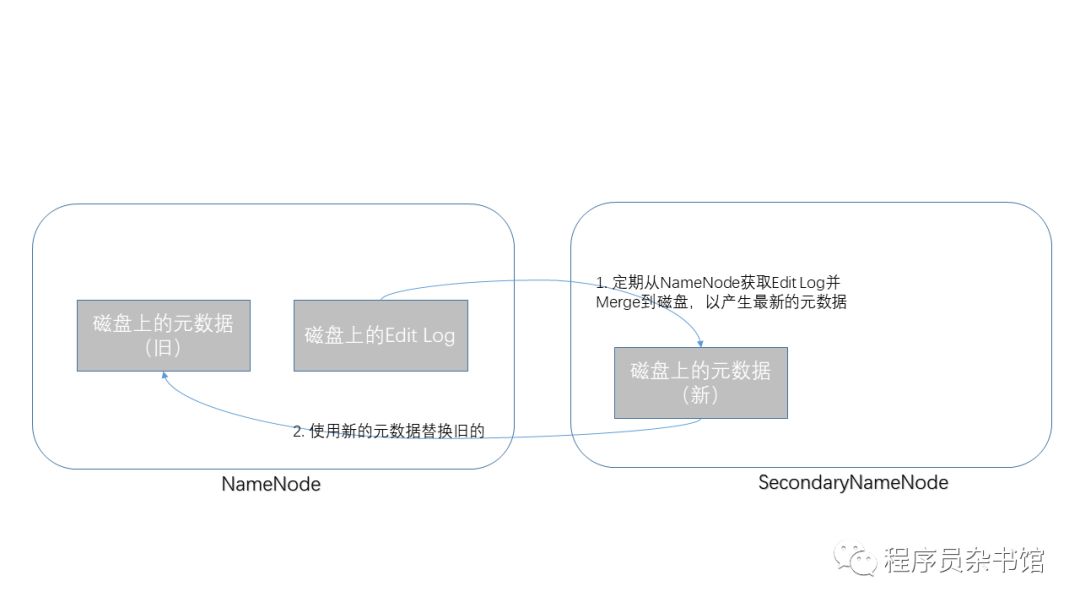
它定期(比如每小时)从NameNode上抓取Edit Log,使用它更新元数据文件,并把最新的元数据文件写回到NameNode。
说完了SecondaryNameNode的职责之后,大家应该明白,它并不是一个“备用NameNode”,其实这是典型的命名不当,它应该被命名成“Checkpoint NameNode”才比较恰当。
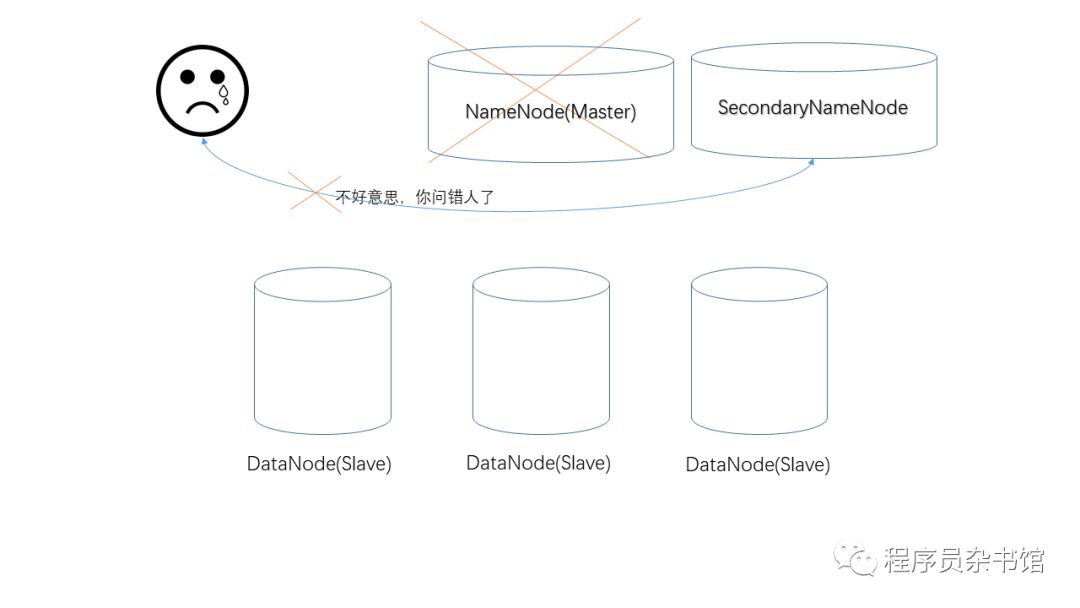
接下来我们来说说HDFS中的单点失败问题(SPOF, Single Point Of Failure),即,当NameNode掉线之后,整个HDFS集群就变得不可用了。
为解决这个问题,实现系统的高可用性(HA, High Availability),Hadoop 2.0中真正引入了一个“备用NameNode”。
对元数据的修改首先发生在NameNode,并被写入某个“共享位置”,备用NameNode将从该位置获取Edit Log。
DataNode节点们同时向两台NameNode汇报状态。
由于这两点,两台NameNode上的元数据将一直保持同步。这将保证当NameNode掉线后,用户可以立即切换到备用NameNode,系统将保持可用。
另外,由于备用NameNode比较空闲(不用处理用户请求),系统又给它安排了另外一份工作——定期使用Edit Log更新元数据文件,也就是说它接手了SecondaryNameNode的工作。
所以,在HA环境中,我们就不再需要SecondaryNameNode了。
今天就到这里,下一篇准备介绍JournalNode、NameNode选举等概念,Cheers!
以上是关于大数据小白系列——HDFS的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(四十六)<HDFS各模块的原理>