小白视角大数据基础实践 MapReduce编程基础操作
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白视角大数据基础实践 MapReduce编程基础操作相关的知识,希望对你有一定的参考价值。
目录
1. MapReduce 简介
1.1 起源
在函数式语言里,map表示对一个列表(List)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。
它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。
- 在MapReduce里,map处理的是原始数据,每条数据之间互相没有关系;
- 到了reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性,至少它们都在一个key下面,于是就符合函数式语言里map和reduce的基本思想了。
- “map”和“reduce”的概念和它们的主要思想,都是从函数式编程语言借用来的,还有从矢量编程语言里借来的特性。极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
1.2 模型简介
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker(yarn上ResourceManager),Slave上运行TaskTracker(yarn上Nodemanager)- Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
1.3 MRv1体系结构
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
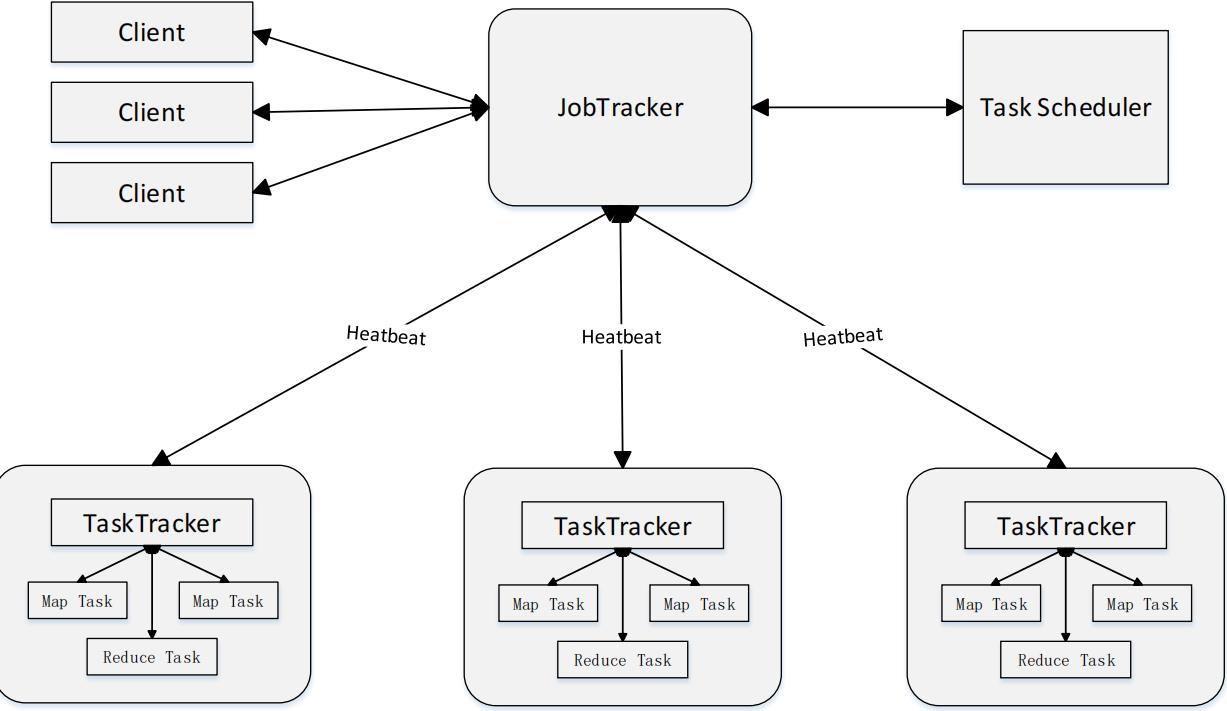
结点说明:
- Client
用户编写的MapReduce程序通过Client提交到JobTracker端,用户可通过Client提供的一些接口查看作业运行状态。 - JobTracker
JobTracker负责资源监控和作业调度;JobTracker监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。 - TaskTracker
TaskTracker会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot和Reduce slot两种,分别供Map Task和Reduce Task使用。 - Task
Task分为Map Task和Reduce Task两种,均由TaskTracker启动。
结构缺点:
- 存在单点故障
- JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
- 容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
- 资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
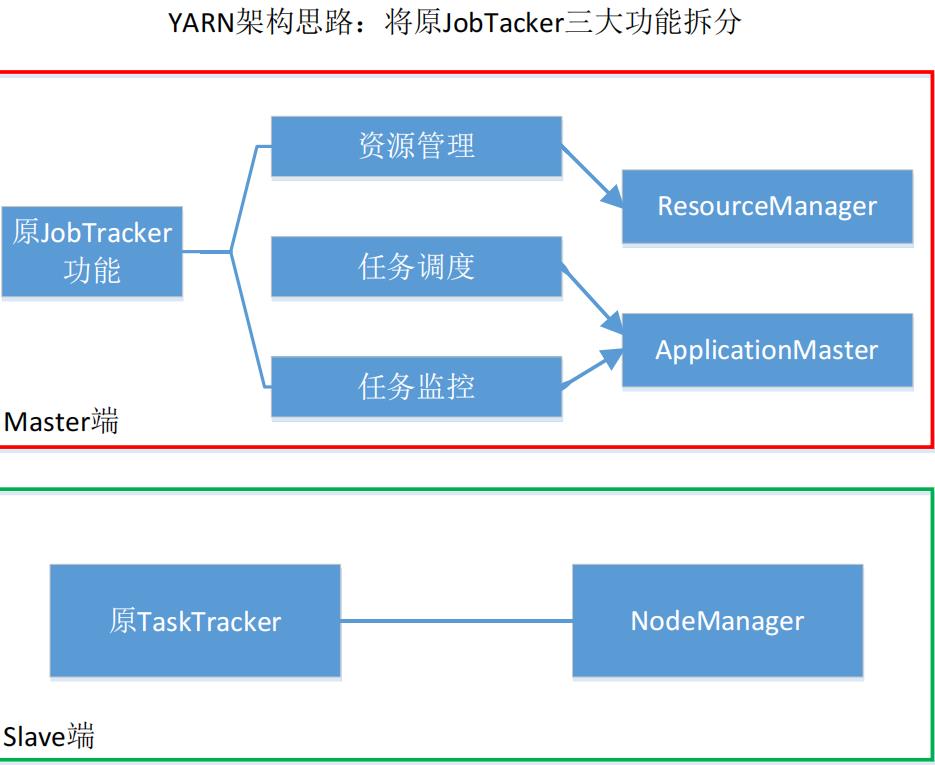
1.4 YARN
1.4.1 YARN体系结构
架构思想
体系结构
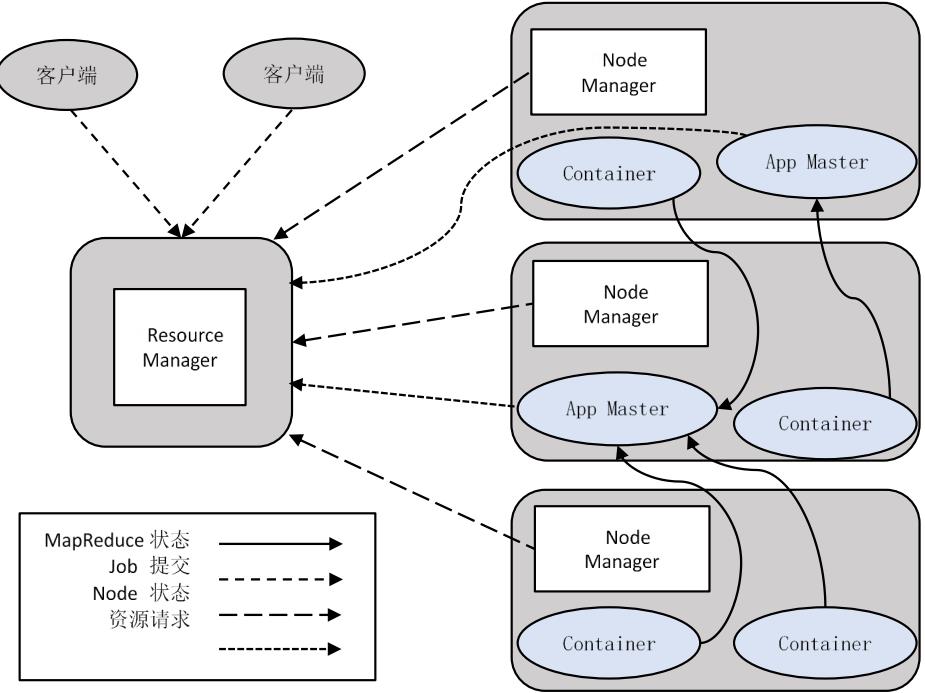
ResourceManager
• 处理客户端请求
• 启动/监控ApplicationMaster
• 监控NodeManager
• 资源分配与调度
NodeManager
• 单个节点上的资源管理
• 处理来自ResourceManger的命令
• 处理来自ApplicationMaster的命令
ApplicationMaster
• 为应用程序申请资源,并分配给内部任务
• 任务调度、监控与容错
1.4.2 YARN工作流程
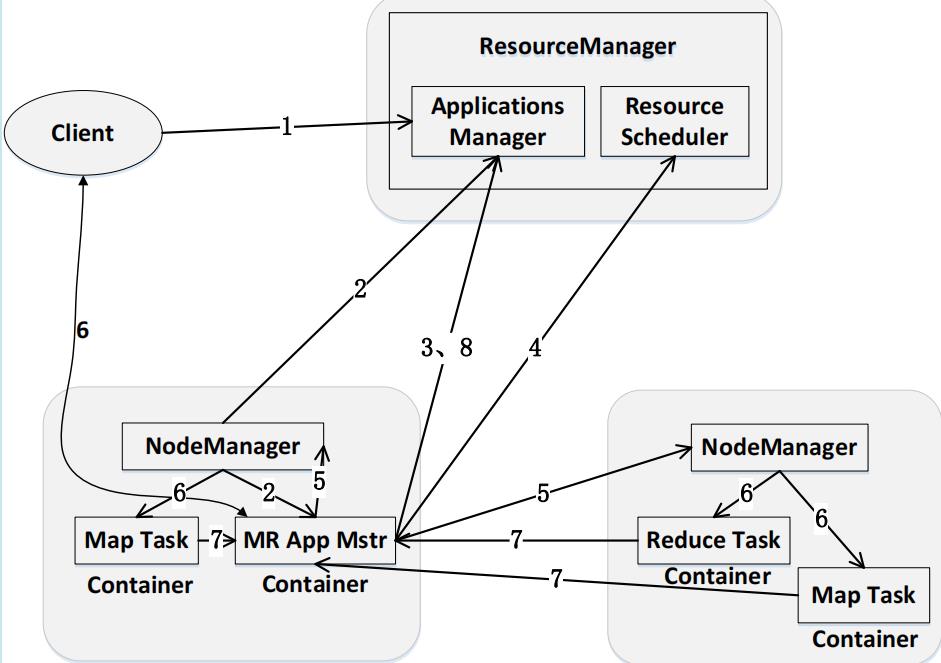
步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
步骤2:YARN中的ResourceManager负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个ApplicationMaster
步骤3:ApplicationMaster被创建后会首先向ResourceManager注册
步骤4:ApplicationMaster采用轮询的方式向ResourceManager申请资源
步骤5:ResourceManager以“容器”的形式向提出申请的ApplicationMaster分配资源
步骤6:在容器中启动任务(运行环境、脚本)
步骤7:各个任务向ApplicationMaster汇报自己的状态和进度
步骤8:应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己
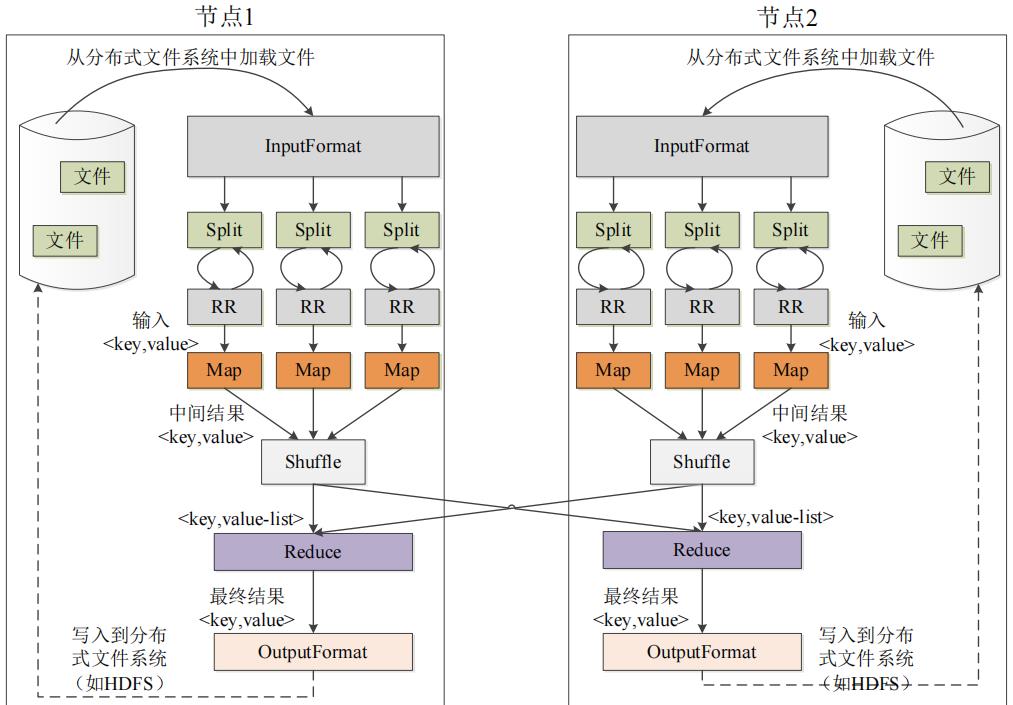
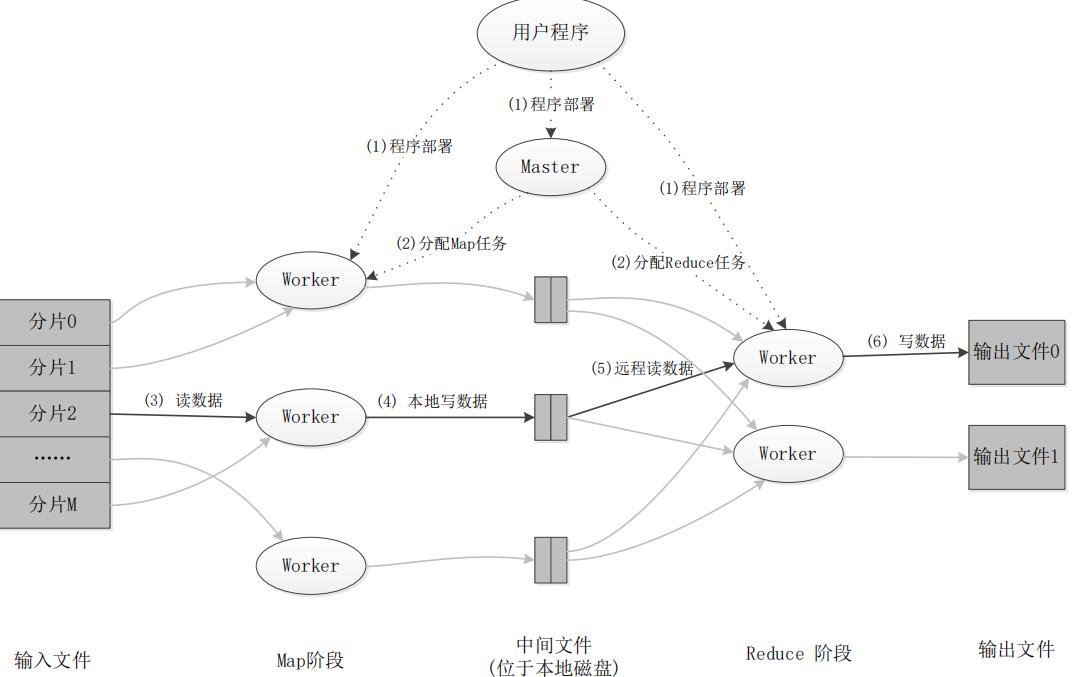
2. MapReduce 工作流程
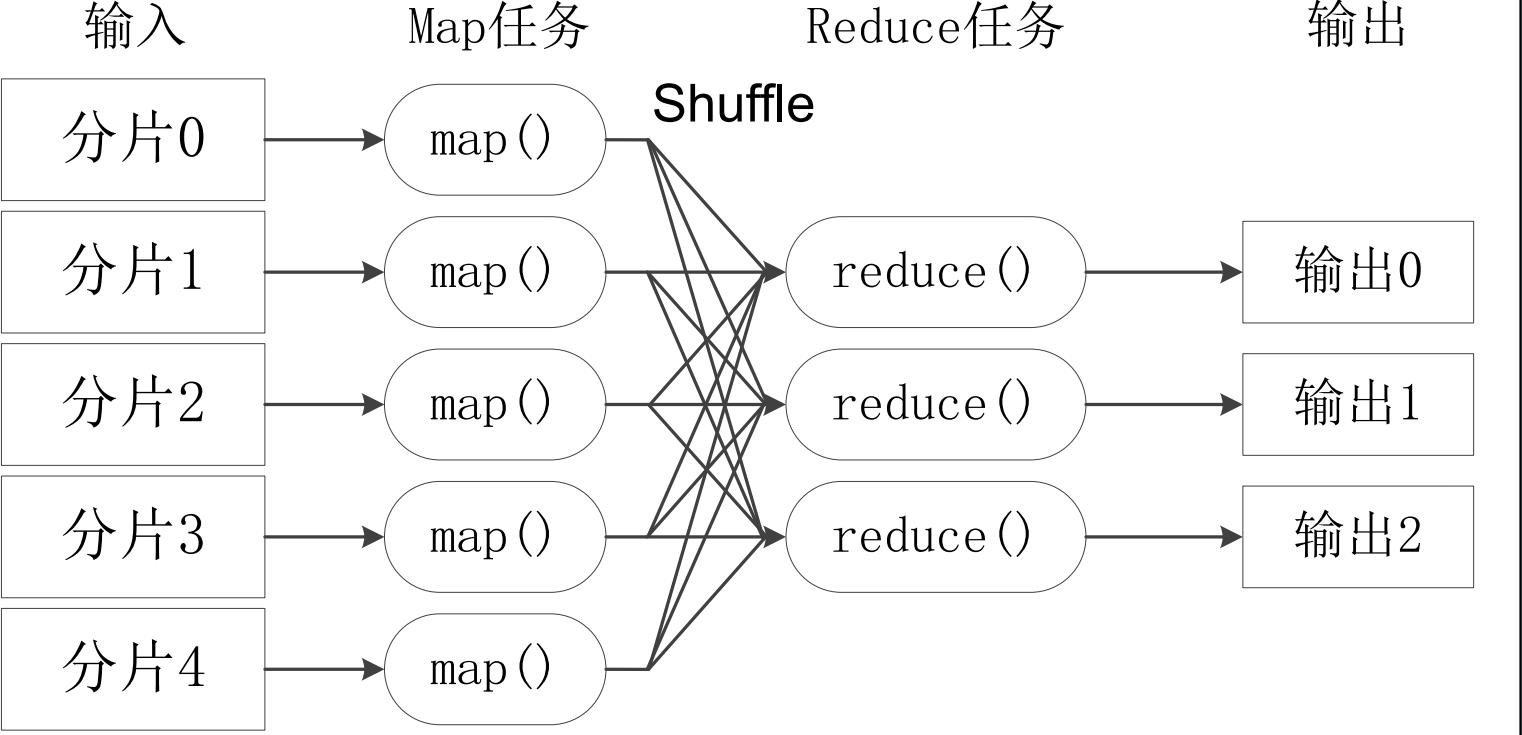
➢ 不同的Map任务之间不会进行通信
➢ 不同的Reduce任务之间也不会发生任何信息交换
➢ 用户不能显式地从一台机器向另一台机器发送消息
➢ 所有的数据交换都是通过MapReduce框架自身去实现的
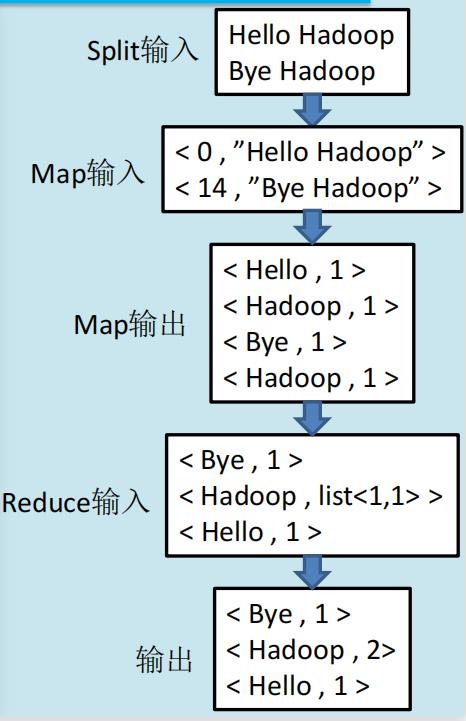
例子
3. Java Api要点
- Writable
Hadoop 自定义的序列化接口。当要在进程间传递对象或持久化对象的时候,就需要序列化对象成字节流,反之当要将接收到或从磁盘读取的字节流转换为对象,就要进行反序列化。Map 和 Reduce 的 key、value 数据格式均为 Writeable 类型,其中 key 还需实现WritableComparable 接口。Java 基本类型对应 writable 类型的封装如下:
| Java primitive | Writable implementation |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | ShortWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| enum | EnumWritable |
| Map | MapWritable |
(2)InputFormat
用于描述输入数据的格式。提供两个功能:
getSplits()数据分片,按照某个策略将输入数据切分成若干个split,以便确定Map任务个数以及对应的split;createRecordReader(),将某个split解析成一个个key-value对。
FileInputFormat是所有以文件作为数据源的InputFormat实现基类,小文件不会进行分片,记录读取调用子类TextInputFormat实现;
TextInputFormat是默认处理类,处理普通文本文件,以文件中每一行作为一条记录,行起始偏移量为key,每一行文本为 value;CombineFileInputFormat针对小文件设计,可以合并小文件;KeyValueTextInputFormat适合处理一行两列并以tab作为分隔符的数据;NLineInputFormat控制每个split中的行数。
(3)OutputFormat
主要用于描述输出数据的格式。Hadoop 自带多种 OutputFormat 的实现。
TextOutputFormat默认的输出格式,key 和 value 中间用 tab 分隔;SequenceFileOutputFormat,将 key 和 value 以 SequenceFile 格式输出;SequenceFileAsOutputFormat,将 key 和 value 以原始二进制格式输出;MapFileOutputFormat,将 key 和 value 写入 MapFile 中;MultipleOutputFormat,默认情况下 Reducer 会产生一个输出,用该格式可以实现一个Reducer 多个输出。
(4)Mapper/Reducer
封装了应用程序的处理逻辑,主要由 map、reduce 方法实现。
(5)Partitioner
根据 map 输出的 key 进行分区,通过 getPartition()方法返回分区值,默认使用哈希函
数。分区的数目与一个作业的reduce任务的数目是一样的。HashPartitioner是默认的Partioner。
4. 实验过程
1、计数统计类应用
仿照 WordCount 例子,编写“TelPubXxx”类实现对拨打公共服务号码的电话信息的统计。给出的一个文本输入文件如下,第一列为电话号码、第二列为公共服务号码,中间以空格隔开。
13718855152 11216810117315 110
39451849 112
13718855153 110
13718855154 112
18610117315 114
18610117315 114
MapReduce 程序执行后输出结果如下,电话号码之间用“|”连接:
110 13718855153|16810117315
112 13718855154|39451849|13718855152
114 18610117315|18610117315
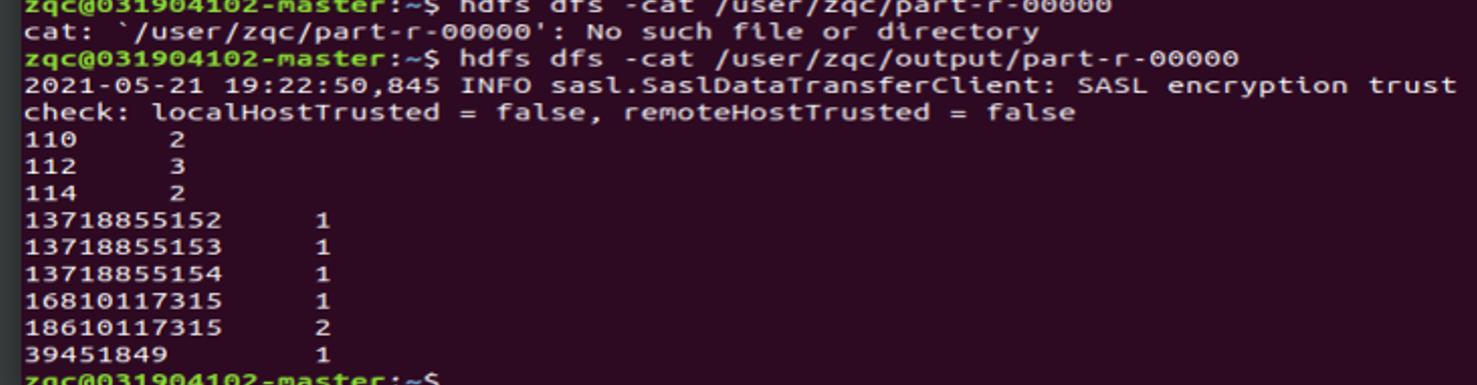
运行成功

import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TelPubZqc {
public static class TelMap extends Mapper<Object, Text, Text, Text> {
private Text pub = new Text();
private Text tel = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//Map (Key Value)
String[] s=value.toString().split(" ");
tel.set(s[0]);
pub.set(s[1]);
context.write(pub,tel);
}
}
public static class TelReducer extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder s= new StringBuilder();
for (Text val : values) {
if(s.toString().equals("")){
s.append(val.toString());
}
else s.append("|").append(val.toString());
}
result.set(String.valueOf(s));
context.write(key, result);// 输出结果
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加载hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input/input.txt","output/outputTel"};
if (otherArgs.length < 2) {
System.err.println("Usage: PubTel <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");// 设置环境参数
job.setJarByClass(TelPubZqc.class);// 设置程序主类
job.setMapperClass(TelMap.class);// 设置用户实现的Mapper类
job.setCombinerClass(TelReducer.class);
job.setReducerClass(TelReducer.class);// 设置用户实现的Reducer类
job.setOutputKeyClass(Text.class);// 设置输出key类型
job.setOutputValueClass(Text.class); // 设置输出value类型
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));// 添加输入文件路径
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));// 设置输出文件路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 提交作业并等待结束
}
}
2、两表联结 Join 应用
仿照单表关联例子,编写“RelationXxx”类实现多表关联。中文文本文件转成 UTF-8 编码格式,否则会乱码。
输入 score.txt:
| studentid | classid | score |
|---|---|---|
| s003001 | fd3003 | 84 |
| s003001 | fd3004 | 90 |
| s003002 | fd2001 | 71 |
| s002001 | fd1001 | 66 |
| s001001 | fd1001 | 98 |
| s001001 | fd1002 | 60 |
输入 major.txt:
| classid | classname | deptname |
|---|---|---|
| fd1001 | 数据挖掘 | 数学系 |
| fd2001 | 电子工程 | 电子系 |
| fd2002 | 电子技术 | 电子系 |
| fd3001 | 大数据 | 计算机系 |
| fd3002 | 网络工程 | 计算机系 |
| fd3003 | Java 应用 | 计算机系 |
| fd3004 | web 前端 | 计算机系 |
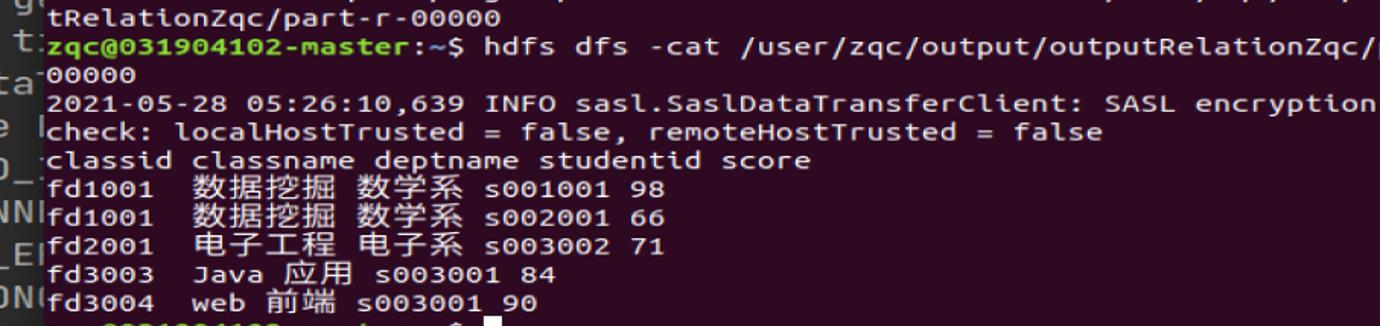
输出结果:
| classid | classname | deptname | studentid | score |
|---|---|---|---|---|
| fd1001 | 数据挖掘 | 数学系 | s001001 | 98 |
| fd1001 | 数据挖掘 | 数学系 | s002001 | 66 |
| fd2001 | 电子工程 | 电子系 | s003002 | 71 |
| fd3003 | Java 应用 | 计算机系 | s003001 | 84 |
| fd3004 | web 前端 | 计算机系 | s003001 | 90 |
将其中需要的东西传到hdfs中去。
没有报错。查看结果
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class RelationZqc {
public static int time = 0;
public static class RelationMap extends Mapper<Object, Text, Text, Text> {
private Text classID = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String filename=((FileSplit)context.getInputSplit()).getPath().getName();
String[] s = value.toString().split(" ");
if(filename.equals("score.txt")){
classID.set(s[1]);
String val="1," + s[0] + "," + s[2];
context.write(classID,new Text(val));
}
else if (filename.equals("major.txt")){
if(!s[0].equals("classid")){
classID.set(s[0]);
String val = "2," + s[1] + "," + s[2];
context.write(classID,new Text(val));
}
}
}
}
public static class RelationReduce extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String[][] studentTable=new String[10][2];
String[] data;
String classID = "nil";
if(time == 0){
context.write(new Text("classid"), new Text("classname deptname studentid score"));
time++;
}
int cnt = 0;
for (Text val : values) {
data = val.toString().split(",");
if(data[0].equals("1")){
studentTable[cnt][0] = data[1];
studentTable[cnt][1] = data[2];
cnt = cnt + 1;
}
else if(data.length == 3 && data[0].equals("2")){
classID = data[1] + " " + data[2];
}
}
for(int i = 0; i < cnt; i++){
if(classID.equals("nil")) continue;
String s=classID+" "+studentTable[i][0]+" "+studentTable[i][1];
result.set(s);
context.write(key, result);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加载hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"input/score.txt", "input/major.txt", "output/outputRelationZqc"};
// String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: Relation <in> <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "RelationZqc");// 设置环境参数
job.setJarByClass(RelationZqc.class);// 设置程序主类
job.setMapperClass(RelationMap.