梯度下降的可视化解释(Adam,AdaGrad,Momentum,RMSProp)
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了梯度下降的可视化解释(Adam,AdaGrad,Momentum,RMSProp)相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :知乎McGL,https://zhuanlan.zhihu.com/p/147275344
一图胜千言,什么?还是动画,那就更棒啦!
A Visual Explanation of Gradient Descent Methods (Momentum, AdaGrad, RMSProp, Adam) by Lili Jiang
https://towardsdatascience.com/a-visual-explanation-of-gradient-descent-methods-momentum-adagrad-rmsprop-adam-f898b102325c
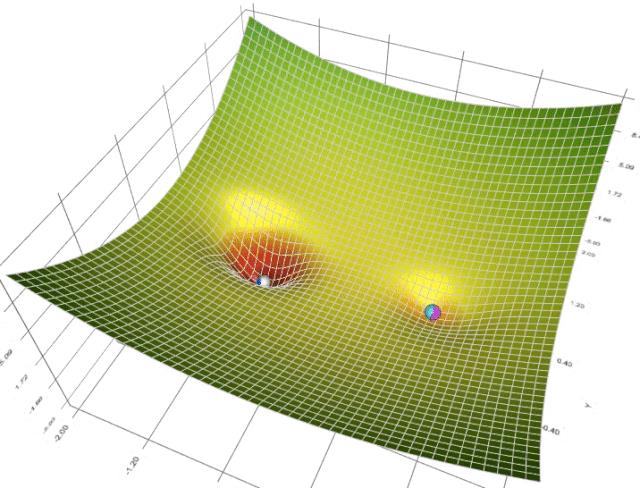
在一个表面上动画演示5个梯度下降法: 梯度下降(青色) ,momentum(洋红色) ,AdaGrad (白色) ,RMSProp (绿色) ,Adam (蓝色)。左坑是全局极小值,右坑是局部极小值
在这篇文章中,我用了大量的资源来解释各种梯度下降法(gradient descents),想直观地介绍一下这些方法是如何工作的。通过我写的一个梯度下降可视化工具(https://github.com/lilipads/gradient_descent_viz)的帮助,希望可以向你展示一些独特的见解,或者至少是很多GIF :-)
我假设大家已经对梯度下降在机器学习中的使用原因和方式有基本的了解。这里的重点是比较这些方法。如果你已经熟悉了所有的方法,可以拉到底部观看一些有趣的“赛马”。
原版梯度下降(Vanilla Gradient Descent)
让我们快速复习一下。在机器学习的场景下,梯度下降学习的目标通常是最小化机器学习问题的损失函数。一个好的算法能够快速可靠地找到最小值(也就是说,它不会陷入局部极小值、鞍点或高原区域,而是寻找全局最小值)。
基本的梯度下降算法遵循的思想是,梯度的相反方向指向较低的区域。所以它在梯度的相反方向迭代。对于每个参数 theta,它做如下操作:
delta = - learning_rate * gradient
theta += delta
Theta 是一些需要优化的参数(例如,神经网络中神经元与神经元之间连接的权重,线性回归特征的系数,等等)。在机器学习优化设置中可能有成千上万个这样的 thetas 。Delta 是算法中每次迭代后 theta 的变化量; 希望随着每次这样的变化,theta 逐渐接近最优值。

由于人类的感知仅限于三维,在我所有的可视化中,假设我们只有两个参数(或者 thetas)需要优化,它们由图中的 x 和 y 维表示。曲面是损失函数。我们要找到在曲面最低点的(x,y)组合。这个问题对我们来说是显而易见的,因为我们可以看到整个曲面。但是这个球(下降算法)不能,它一次只能走一步,探索周围的环境,就像在黑暗中只用手电筒走路一样。
原版梯度下降法之所以叫原版,是因为它只按照梯度来执行。下面的方法对梯度进行一些额外的处理,使其更快、更好。
动量(Momentum)
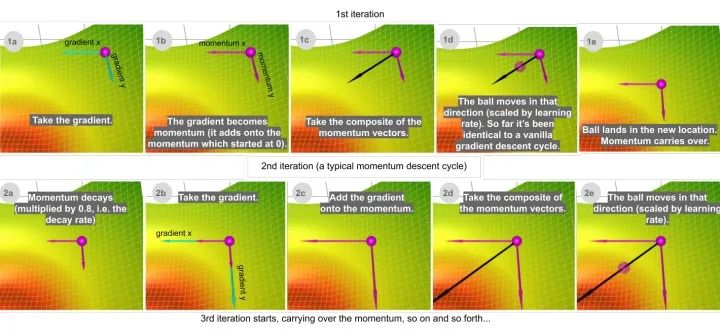
带有动量的梯度下降算法(简称动量)借鉴了物理学的思想。想象一下在无摩擦的碗里滚动一个球。没有在底部停止,而是积累的动量推动它前进,球继续前后滚动。
我们可以把动量的概念应用到我们的原版梯度下降算法中。在每个步骤中,除了常规的梯度之外,它还增加了前一步中的移动。在数学上,它通常表示为:
delta = - learning_rate * gradient + previous_delta * decay_rate (方程1)
theta += delta (方程2)
我发现如果我稍微修改一下这个方程,然后跟踪(衰减的)累积梯度之和,会更直观。当我们稍后引入 Adam 算法时,这也会使事情变得更简单。
sum_of_gradient = gradient + previous_sum_of_gradient * decay_rate (方程3)
delta = -learning_rate * sum_of_gradient (方程4)
theta += delta (方程5)
(我所做的是分解出学习率。为了看到数学等价性,可以用-learning_rate * sum_of_gradient代替方程1中的delta 以得到方程3.)
让我们考虑两个极端情况来更好地理解这个衰减率(decay rate)参数。如果衰减率为0,那么它与原版梯度下降完全相同。如果衰减率是1,那么它就会像我们开始提到的无摩擦碗的类比一样,前后不断地摇摆; 你不会想要这样的结果。通常衰减率选择在0.8-0.9左右,它就像一个有一点摩擦的表面,所以它最终会减慢并停止。
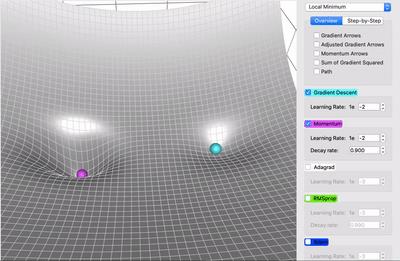
那么,在哪些方面动量比原版梯度下降更好呢?在上面的比较中,你可以看到两个优点:
动量移动得更快(因为它积累的所有动量)
动量有机会逃脱局部极小值(因为动量可能推动它脱离局部极小值)。同样,我们将在后面看到,它也将更好地通过高原区
AdaGrad
Adaptive Gradient 算法,简称 AdaGrad,不是像动量一样跟踪梯度之和,而是跟踪梯度平方之和,并使用这种方法在不同的方向上调整梯度。这些方程通常用张量表示。我将避免使用张量来简化这里的语言。对于每个维度:
sum_of_gradient_squared = previous_sum_of_gradient_squared + gradient²
delta = -learning_rate * gradient / sqrt(sum_of_gradient_squared)
theta += delta
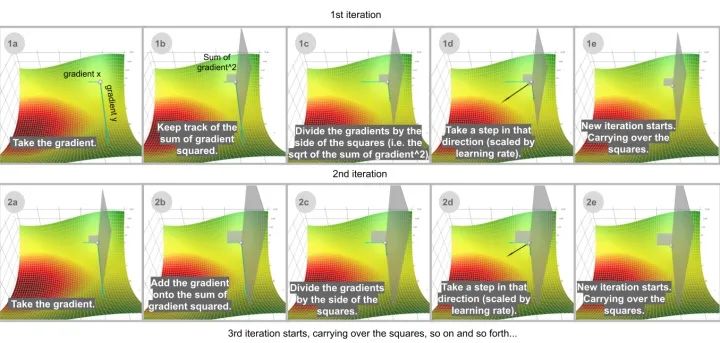
在机器学习优化中,一些特征是非常稀疏的。稀疏特征的平均梯度通常很小,所以这些特征的训练速度要慢得多。解决这个问题的一种方法是为每个特征设置不同的学习率,但这很快就会变得混乱。
Adagrad 解决这个问题的思路是: 你已经更新的特征越多,你将来更新的就越少,这样就有机会让其它特征(例如稀疏特征)赶上来。用可视化的术语来说,更新这个特征的程度即在这个维度中移动了多少,这个概念由梯度平方的累积和表达。注意在上面的一步一步的网格插图中,如果没有重新缩放调整(1b) ,球大部分会垂直向下移动; 如果有调整(1d) ,它会沿对角线方向移动。
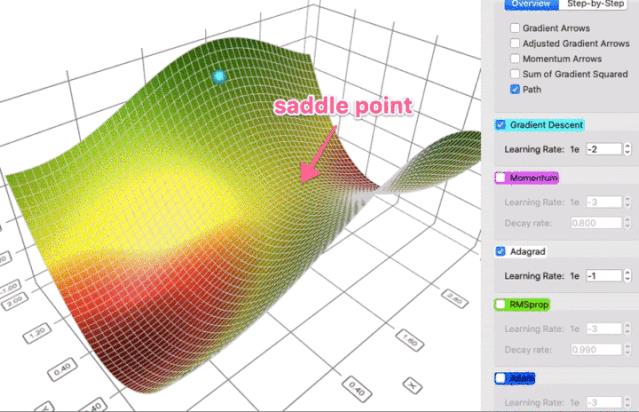
这个属性让 AdaGrad (以及其它类似的基于梯度平方的方法,如 RMSProp 和 Adam)更好地避开鞍点。Adagrad 将采取直线路径,而梯度下降(或相关的动量)采取的方法是“让我先滑下陡峭的斜坡,然后才可能担心较慢的方向”。有时候,原版梯度下降可能非常满足的仅仅停留在鞍点,那里两个方向的梯度都是0。
RMSProp
然而,AdaGrad 的问题在于它非常慢。这是因为梯度的平方和只会增加而不会减小。Rmsprop (Root Mean Square Propagation)通过添加衰减因子来修复这个问题。
sum_of_gradient_squared = previous_sum_of_gradient_squared * decay_rate+ gradient² * (1- decay_rate)
delta = -learning_rate * gradient / sqrt(sum_of_gradient_squared)
theta += delta
更精确地说,梯度的平方和实际上是梯度平方的衰减和。衰减率表明的是只是最近的梯度平方有意义,而很久以前的梯度基本上会被遗忘。顺便说一句,“衰减率”这个术语有点用词不当。与我们在动量中看到的衰减率不同,除了衰减之外,这里的衰减率还有一个缩放效应: 它以一个因子(1 - 衰减率)向下缩放整个项。换句话说,如果衰减率设置为0.99,除了衰减之外,梯度的平方和将是 sqrt (1-0.99) = 0.1,因此对于相同的学习率,这一步大10倍。
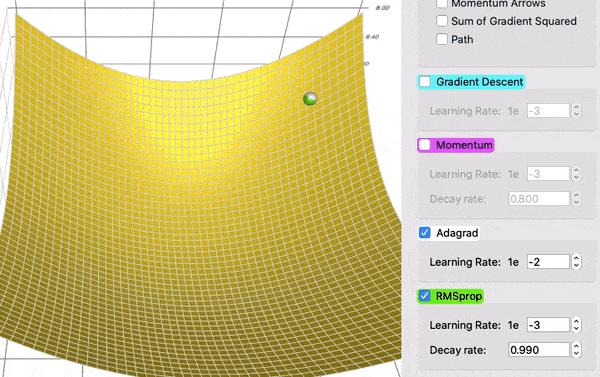
为了看到衰减的效果,在这个对比中,AdaGrad (白色)最初与 RMSProp (绿色)差不多,正如调整学习率和衰减率的预期。但是 AdaGrad 的梯度平方和累计得非常快,以至于它们很快变得非常巨大(从动画中方块的大小可以看出)。买路费负担沉重,最终 AdaGrad 几乎停止了。另一方面,由于衰变率的原因,RMSProp 一直将方块保持在一个可控的大小。这使得 RMSProp 比 AdaGrad 更快。
Adam
最后但并非最不重要的是,Adam (Adaptive Moment Estimation)同时兼顾了动量和 RMSProp 的优点。Adam在实践中效果很好,因此在最近几年,它是深度学习问题的常用选择。
让我们来看看它是如何工作的:
sum_of_gradient = previous_sum_of_gradient * beta1 + gradient * (1 - beta1) [Momentum]
sum_of_gradient_squared = previous_sum_of_gradient_squared * beta2 + gradient² * (1- beta2) [RMSProp]
delta = -learning_rate * sum_of_gradient / sqrt(sum_of_gradient_squared)
theta += delta
Beta1是一阶矩梯度之和(动量之和)的衰减率,通常设置为0.9。Beta2是二阶矩梯度平方和的衰减率,通常设置为0.999。
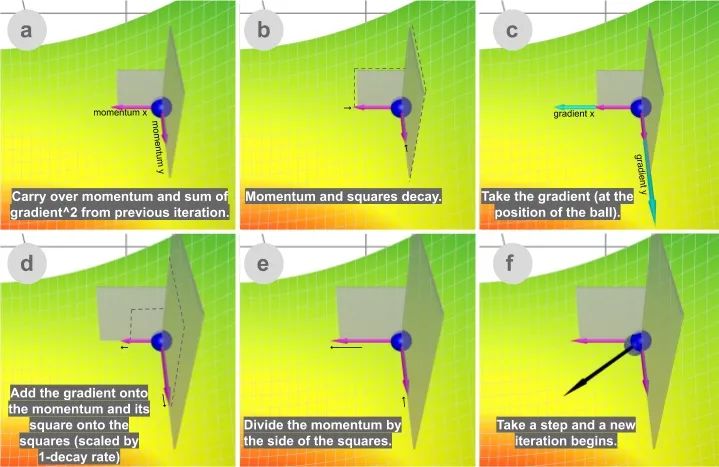
Adam 的速度来自于动量和RMSProp 适应不同方向的梯度的能力。这两者的结合使它变得更强大。
结束语
现在我们已经讨论了所有的方法,让我们观看几个比赛,包含所有我们上面提到的下降方法!(有一些不可避免的参数挑选。最好自己玩一下)
在这个地形中,有两座小山阻挡了通往全局极小值的道路。Adam是唯一一个能够找到通往全局极小值的算法。无论以哪种方式调整参数,至少从这个起始位置开始,没有任何其它方法可以到达那里。这意味着不管是动量还是自适应梯度都不能单独做到这一点。这实际上是两者的结合: 首先,动量使Adam越过了所有其它球停止的局部极小值点; 然后对梯度平方和的调整使其侧向移动,因为这是一个未被探索的方向,导致了它的最终胜利。
这是另一场比赛。在这个地形中,围绕着全局极小值有一个平坦的区域(高原)。通过一些参数调整,Momentum 和 Adam (多得其动量组件)可以到达中心,而其它方法不能。
总之,梯度下降法算法是一类通过梯度来寻找函数最小点的算法。原版梯度下降只遵循梯度(按学习速率进行调整)。改善梯度下降法的两个常用工具是梯度之和(一阶矩)和梯度平方之和(二阶矩)。动量利用一阶矩的衰减率来获得速度。Adagrad 使用没有衰减的二阶矩来处理稀疏特征。Rmsprop 使用二阶矩的衰减率来加速 AdaGrad。Adam同时使用一阶矩和二阶矩,通常是最好的选择。还有一些其它的梯度下降算法,比如 Nesterov 加速梯度算法,AdaDelta 算法等等,在本文中没有涉及。
最后,展示一下带着没有衰减的动量下降。它的路径构成了一个有趣的模式。没有什么实际的用处,但是在这里展示它只是为了好玩。
玩下这个在这篇文章中用来生成所有的可视化效果的可视化工具(https://github.com/lilipads/gradient_descent_viz),看看你会发现什么!
参考资料及相关链接:
[1] http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
[2] https://ruder.io/optimizing-gradient-descent
[3] https://bl.ocks.org/EmilienDupont/aaf429be5705b219aaaf8d691e27ca87
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于梯度下降的可视化解释(Adam,AdaGrad,Momentum,RMSProp)的主要内容,如果未能解决你的问题,请参考以下文章
梯度下降优化算(Momentum, AdaGrad, RMSprop, Adam)学习率退火
梯度优化方法:BGD,SGD,mini_batch, Momentum,AdaGrad,RMSProp,Adam
SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam
SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam