梯度优化方法:BGD,SGD,mini_batch, Momentum,AdaGrad,RMSProp,Adam
Posted hellobigorange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了梯度优化方法:BGD,SGD,mini_batch, Momentum,AdaGrad,RMSProp,Adam相关的知识,希望对你有一定的参考价值。
文章目录

目标函数

最优化:得到使目标函数 J ( θ ) J(\\theta) J(θ)最小的 θ \\theta θ的值。
三种梯度下降优化框架
1、BGD、SGD、mini_batch
-
优化方法(特征维数高)
1)初始化 θ \\theta θ
2)最优化方法求解使 J ( θ ) J(\\theta) J(θ)最小的 θ \\theta θi. 批量梯度下降法(BGD)
每一次参数更新,使用所有样本
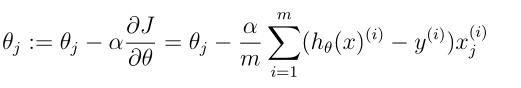
ii. 随机梯度下降法(SGD)
每一次参数更新,使用一个样本,可能会跳出局部最小值,效率高

iii. 1 二者综合(mini_batch)
每一次参数更新,使用样本中的一小部分

2、优缺点对比:

i. 批量梯度下降法(BGD)可以确保每次向正确的方向前进,但时间慢;
ii. 随机梯度下降法(SGD)随机梯度下降每次更新不一定会沿正确方向(不稳定),但更新快,且有可能会跳过局部最优;
iii. 1 二者综合(mini_batch)更新相对较稳定,速度相对较快。
3、问题与挑战:
- 学习率的选择, α \\alpha α过大,容易在极值点附近震荡; α \\alpha α过小,收敛速度缓慢。
- 自动调整学习率,如退火(每次迭代衰减一个较小的阈值),也是需要固定设置阈值,无法实现自适应学习。
- 所有参数( θ 1 , . . . , θ n \\theta_1,...,\\theta_n θ1,...,θn)的更新,都是采用同一个学习率,但是根据特征的稀疏度和不同的特征,应当选取不同的学习率。
- 对于非凸目标函数,容易陷入局部最优点。
优化梯度下降法
1、动量梯度下降法(Momentum)
梯度不仅与当前梯度有关还与之前的梯度有关,这样参数更新的方向会朝向更加有利于收敛的方向(有利于减小震荡),收敛速度更快。

上图红线为增加了动量的,黑线为SGD。
参数更新公式如下:



动量参数 α < 1 \\alpha<1 α<1,一般 ≤ 0.9 \\leq0.9 ≤0.9
加上动量项就像从山顶滚下一个球,求往下滚的时候累积了前面的动量(动量不断增加),因此速度变得越来越快,直到到达终点。同理,在更新模型参数时,对于那些当前的梯度方向与上一次梯度方向相同的参数,那么进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的参数,那么进行削减,即这些方向上减慢了。因此可以获得更快的收敛速度与减少振荡。
2、Nesterov Accelarated Gradient(NAG)
是在Momentum的基础上改进得到的一个算法,不同之处在于m每次更新时加上梯度的不同,Momentum是加上当前位置 θ \\theta θ的梯度,而NAG是加上当前位置之后一点点 θ + β m \\theta+\\beta m θ+βm处的梯度。这样做会**使动量m指向更加正确的(局部)最优点的方向,加快收敛到极值点。NAG的参数更新公式如下:

下图为Momentum和NAG的对比图:

Momentum根据 γ m \\gamma m γm和 η ∇ 1 \\eta\\nabla_1 η∇1计算m,而NAG根据 γ m \\gamma m γm和 η ∇ 2 \\eta\\nabla_2 η∇2计算m,**NAG在接近极值的时候,如果超出了极值点,会把更新的方向往回拉,而不是继续往前,有利于减小震荡,加速收敛

3、Adagrad

4、RMSprop

*RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。*

*在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。*
5、Adaptive momentum estimation(Adam)
| 优点 | 缺点 | 适用 | |
|---|---|---|---|
| BGD | 梯度总向正确方向前进 | 更新慢、实时性差、学习率难调整 | 小数据集 |
| SGD | 更新快、可能可以跳出局部极小 | 震荡严重、学习率难调整 | |
| mini-batch | 收敛更稳定、速度更快 | 学习率难调整;所有特征用同一种学习率,但如果是稀疏特征更希望以大一点的学习率;局部极小值处容易震荡 | |
| momentum | 增加收敛稳定性,减小震荡,收敛速度更快 | 所有特征用同一种学习率,但如果是稀疏特征更希望以大一点的学习率; | |
| rmsprop | 自动学习率调整 | 特征稀疏 | |
| adam | 自动学习率调整 | 特征稀疏 |
以上是关于梯度优化方法:BGD,SGD,mini_batch, Momentum,AdaGrad,RMSProp,Adam的主要内容,如果未能解决你的问题,请参考以下文章