SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam
Posted cherrychenlee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam相关的知识,希望对你有一定的参考价值。
梯度下降优化基本公式:\\({\\theta\\leftarrow\\theta-\\eta\\cdot\\nabla_\\theta{J(\\theta)}}\\)
三种梯度下降优化框架
这三种梯度下降优化框架的区别在于每次更新模型参数时使用不同的样本数。
Batch Gradient Descent
批/全量梯度下降每次更新模型参数时使用全部的训练样本。
\\({\\theta\\leftarrow\\theta-\\eta\\cdot\\frac{1}{N}\\sum_{i=1}^{N}\\nabla_\\theta{J({\\theta};x_i,y_i)}}\\) N为训练样本数
优点:每次更新都会朝着正确的方向进行,最终能够保证收敛于极值点,因此更新比较稳定。
缺点:每次的学习时间过长,训练集很大时会消耗大量内存,且不能进行在线模型参数的更新。
Stochastic Gradient Descent
随机梯度下降每次更新参数时从训练样本中随机选择一个样本。
\\({\\theta\\leftarrow\\theta-\\eta\\cdot\\nabla_\\theta{J({\\theta};x_i,y_i)}}\\)
优点:每次的学习很快速,且可以进行在线更新。
缺点:每次的更新可能并不会完全朝着正确的方向进行,高频率的参数更新导致了高方差,因此带来了优化扰动。
关于优化波动,带来的好处是在有很多local minima的区域,优化波动可能会使得优化的方向从当前的local minima跳到另一个更好的local minima,甚至是global minima,最终收敛于一个较好的minima。由于波动,迭代次数增多,收敛速度下降,不过最终会和批梯度下降一样具有收敛性。
Mini-batch Gradient Descent
小批量梯度下降每次更新模型参数时从训练样本中随机选择M(M<N,常取32~256)个样本。
\\({\\theta\\leftarrow\\theta-\\eta\\cdot\\frac{1}{M}\\sum_{i取M个不同值}\\nabla_\\theta{J({\\theta};x_i,y_i)}}\\)
优点:结合了批梯度下降的稳定性和随机梯度下降的随机性。相对于随机梯度下降,小批量梯度下降降低了收敛波动性,即降低了参数更新的方差,使得参数更新更加稳定;相对于批梯度下降,小批量梯度下降提高了每次的更新速度,不用担心内存瓶颈,可利用矩阵运算进行高效计算,在GPU的帮助下,小批量梯度下降和随机梯度下降更新一次参数的时间差不多,并且批梯度下降容易卡在较浅的local minima处或不那么麻烦的saddle point处,这时候给它随机梯度下降的随机性就能够逃脱出来。
一般,SGD指小批量梯度下降。
SGD存在的问题:
1、对于非凸函数,常卡在次优的local minima处以及较为麻烦的如周围都是plateau的saddle point处。
2、选择一个合理的\\({\\eta}\\)很困难。太小,收敛太慢;太大,loss变大或在local minima附近振荡。
3、手动调整\\({\\eta}\\)时,无论是哪种调整方式,都需要事先进行固定设置,无法自适应学习的训练数据的特点。
4、模型所有参数每次更新时都是使用相同的\\(\\eta\\)。如果数据特征是稀疏的或者每个特征有着不同的取值统计特征与空间,便不能在每次更新中对每个特征使用相同的\\(\\eta\\)。如对那些很少出现的特征应该使用较大的\\({\\eta}\\)。
梯度下降优化策略
以下,将\\({\\frac{1}{m}\\sum_{i取m个不同值}\\nabla_\\theta{J({\\theta};x_i,y_i)}}\\)记作\\({\\nabla_\\theta{J(\\theta)}}\\)。
Momentum
\\({m\\leftarrow\\gamma\\cdot{m}+\\eta\\cdot\\nabla_\\theta{J(\\theta)}}\\) m为动量项
\\({\\theta\\leftarrow\\theta-m}\\)
其中,动量项超参数\\({\\gamma}\\)越大,之前梯度方向对当前方向的影响也越大。
优点:更新模型参数时,对那些当前梯度方向与之前方向一致的参数梯度进行加强,使得在当前方向上更快了;对那些当前梯度方向与之前方向不一致的参数梯度进行减弱,使得在当前方向上更慢了。因此在更新中可以获得更快的收敛速度与减少振荡。下降中后期,在local minima处来回振荡时,当前梯度趋于0,动量项的存在使得更新幅度增大,有助于跳出较浅的local minima。
Nesterov Accelerated Gradient
NAG计算“超前梯度”更新动量项。
\\({m\\leftarrow\\gamma\\cdot{m}+\\eta\\cdot\\nabla_\\theta{J(\\theta-\\gamma\\cdot{m})}}\\)
\\({\\theta\\leftarrow\\theta-m}\\)
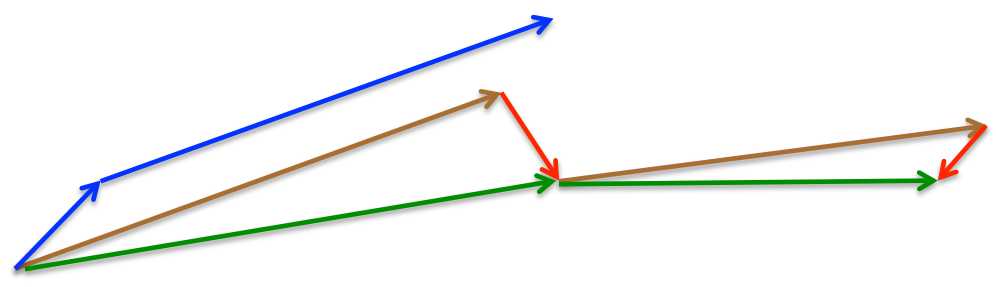
既然参数要沿着\\({\\gamma\\cdot{m}}\\)方向更新(蓝线),不妨计算下未来位置\\({\\theta-\\gamma\\cdot{m}}\\)处的梯度(红线),再将动量项与其合并作为最终的更新项(绿线)。
优点:阻止过快更新来提高响应性。
Adagrad
\\({s\\leftarrow{s}+\\nabla_\\theta{J(\\theta)}\\odot\\nabla_\\theta{J(\\theta)}}\\) s为过去到当前时刻的参数梯度平方和
\\({\\theta\\leftarrow\\theta-\\frac{\\eta}{\\sqrt{s+\\epsilon}}\\odot\\nabla_\\theta{J(\\theta)}}\\) \\(\\epsilon\\)为平滑参数,常为1e-8
\\({\\frac{1}{\\sqrt{s+\\epsilon}}}\\)作为regularizer项,训练前期,梯度较小,regularizer项较大,放大梯度;训练后期,梯度较大,regularizer项较小,约束梯度。
优点:能够对每个参数自适应不同的学习速率。对于稀疏特征,能得到较大的学习更新;对于非稀疏特征,能得到较小的学习更新。因此适合处理稀疏数据。
缺点:学习速率单调递减,最终会趋于0,学习停止过快。
Adadelta
\\({s\\leftarrow\\gamma\\cdot{s}+(1-\\gamma)\\cdot\\nabla_\\theta{J(\\theta)}\\odot\\nabla_\\theta{J(\\theta)}}\\) s为过去到当前时刻的参数梯度值的加权平方和
\\({\\Delta\\theta=\\frac{\\sqrt{r}}{\\sqrt{s+\\epsilon}}\\odot\\nabla_\\theta{J(\\theta)}}\\)
\\({\\theta\\leftarrow\\theta-\\Delta\\theta}\\)
\\({r\\leftarrow\\gamma\\cdot{r}+(1-\\gamma)\\cdot\\Delta\\theta\\odot\\Delta\\theta}\\) r为过去到前一时刻的参数更新值的加权平方和
优点:缓解了Adagrad中学习速率衰减过快的问题。不依赖于全局\\(\\eta\\)。
RMSprop
是Adadelta的特例,无r有s。
\\({s\\leftarrow\\gamma\\cdot{s}+(1-\\gamma)\\cdot\\nabla_\\theta{J(\\theta)}\\odot\\nabla_\\theta{J(\\theta)}}\\)
\\({\\theta\\leftarrow\\theta-\\frac{\\eta}{\\sqrt{s+\\epsilon}}\\odot\\nabla_\\theta{J(\\theta)}}\\)
Adam
\\({m\\leftarrow\\beta_1\\cdot{m}+(1-\\beta_1)\\cdot\\nabla_{\\theta}J(\\theta)}\\) 梯度的加权平均,一阶矩变量,有偏
\\({s\\leftarrow\\beta_2\\cdot{s}+(1-\\beta_2)\\cdot\\nabla_\\theta{J(\\theta)}\\odot\\nabla_\\theta{J(\\theta)}}\\) 梯度平方的加权平均,二阶矩变量,有偏,梯度的加权有偏方差
m和s均初始化为\\({\\vec{0}}\\),Adam作者发现它们会倾向于为\\({\\vec{0}}\\),特别是在\\(\\beta_1\\)和\\(\\beta_2\\)趋于1时。
为了改进这个问题,对m和s进行偏差修正,近似于期望的无偏估计。
\\({m\\leftarrow\\frac{m}{1-\\beta_1}}\\)
\\({s\\leftarrow\\frac{s}{1-\\beta_2}}\\)
\\({\\theta\\leftarrow\\theta-\\frac{\\eta}{\\sqrt{s+\\epsilon}}\\odot{m}}\\)
经过偏置校正后,每一次迭代的学习率都有个确定的范围,使得参数比较平稳。
如何选择梯度下降策略
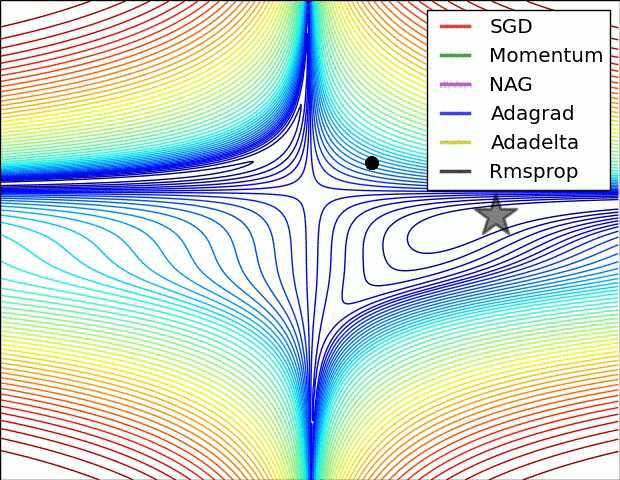
Adagrad、Adadelta、RMSprop在loss surface上能够立刻转移到正确的移动方向上达到快速的收敛,而Momentum、NAG会导致偏离,相较于Momentum,NAG能够在偏移之后更加迅速地修正其路线。
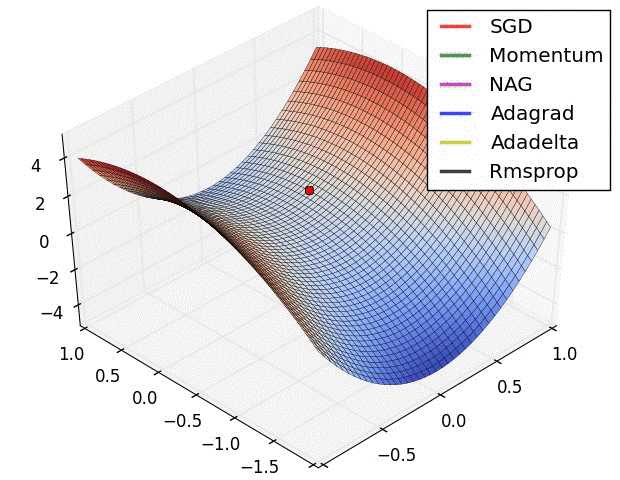
在saddle point处,SGD、Momentum、NAG一直在鞍点梯度为0的方向上振荡,Adagrad、Adadelta、RMSprop能够很快地向梯度不为0的方向上转移。
如果数据特征是稀疏的,最好使用自适应的梯度优化策略。
实验中,SGD常能够收敛到更好的minima,但是相对于其他的GD,可能花费的时间更长,并且依赖于初始值以及学习速率退火策略,并且容易陷入local minima以及鞍点。
以上是关于SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam的主要内容,如果未能解决你的问题,请参考以下文章