分布式数据库理论基础 & PostgreSQL 分布式架构 | 周末送资料
Posted twt企业IT社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式数据库理论基础 & PostgreSQL 分布式架构 | 周末送资料相关的知识,希望对你有一定的参考价值。
【作者】魏波,中国PostgreSQL分会培训认证总监。十多年的数据库运维从业经验,掌握DB2/PostgreSQL,关注开源技术,目前主要负责完善培训认证体系、运营推广,PG社区技术内容组织等工作。
一、 什么是分布式数据库
分布式系统数据库系统原理(第三版)中的描述:“我们把分布式数据库定义为一群分布在计算机网络上、逻辑上相互关联的数据库。分布式数据库管理系统(分布式DBMS)则是支持管理分布式数据库的软件系统,它使得分布对于用户变得透明。有时,分布式数据库系统(Distributed Database System,DDBS)用于表示分布式数据库和分布式DBMS这两者。”
在以上表述中,“一群分布在网络上、逻辑上相互关联”是其要义。在物理上一群逻辑上相互关联的数据库可以分布式在一个或多个物理节点上。当然,主要还是应用在多个物理节点。这一方面是X86服务器性价比的提升有关,另一方面是因为互联网的发展带来了高并发和海量数据处理的需求,原来的单物理服务器节点不足以满足这个需求。
分布式不只是体现在数据库领域,也与分布式存储、分布式中间件、分布式网络有着很多关联。最终目的都是为了更好的服务于业务需求的变更。从哲学意义上理解是一种生产力的提升。
二、 分布式数据库理论基础
1. CAP理论
首先,分布式数据库的技术理论是基于单节点关系数据库的基本特性的继承,主要涉及事务的ACID特性、事务日志的容灾恢复性、数据冗余的高可用性几个要点。
其次,分布式数据的设计要遵循CAP定理,即:一个分布式系统不可能同时满足 一致性( Consistency ) 、可用性 ( Availability ) 、分区容 忍 性 ( Partition tolerance ) 这三个基本需求,最 多只能同时满足其中的两项, 分区容错性 是不能放弃的,因此架构师通常是在可用性和一致性之间权衡。这里的权衡不是简单的完全抛弃,而是考虑业务情况作出的牺牲,或者用互联网的一个术语“降级”来描述。
针对CAP理论,查阅了国外的相关文档表述,CAP理论来源于2002年麻省理工学院的Seth Gilbert和Nancy Lynch发表的关于Brewer猜想的正式证明。

CAP 三个特性描述如下 :
一致性:确保分布式群集中的每个节点都返回相同的 、 最近 更新的数据 。一致性是指每个客户端具有相同的数据视图。有多种类型的一致性模型 , CAP中的一致性是指线性化或顺序一致性,是强一致性。
可用性:每个非失败节点在合理的时间内返回所有读取和写入请求的响应。为了可用,网络分区两侧的每个节点必须能够在合理的时间内做出响应。
分区容忍性:尽管存在网络分区,系统仍可继续运行并 保证 一致性。网络分区已成事实。保证分区容忍度的分布式系统可以在分区修复后从分区进行适当的恢复。
原文主要观点有在强调CAP理论不能简单的理解为三选二。
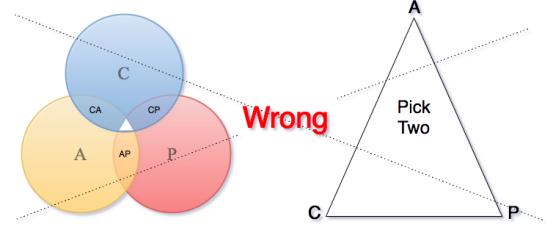
在分布式数据库管理系统中,分区容忍性是必须的。网络分区和丢弃的消息已成事实,必须进行适当的处理。因此,系统设计人员必须在一致性和可用性之间进行权衡 。简单地说,网络分区迫使设计人员选择完美的一致性或完美的可用性。在给定情况下, 优秀 的分布式系统会根据业务对一致性和可用性需求的重要等级提供最佳的答案,但通常一致性需求等级会更高,也是最有挑战的 。
2. BASE理论
基于CAP定理的权衡,演进出了 BASE理论 ,BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
BA:Basically Available 基本可用,分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
S:Soft State 软状态,允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
E:Consistency 最终一致性,系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
BASE 理论本质上是对 CAP 理论的延伸,是对 CAP 中 AP 方案的一个补充。
这里补充说明一下什么是强一致性:
Strict Consistency ( 强一致性 ) 也称为Atomic Consistency ( 原子一致性) 或 Linearizable Consistency(线性一致性) ,必须满足以下 两个要求:
1、任何一次读都能读到某个数据的最近一次写的数据。
2、系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。简言之,在任意时刻,所有节点中的数据是一样的。
BASE 理论的最终一致性属于弱一致性。
接下来介绍另一个分布式数据库重要的概念:分布式事务。浏览了几篇介绍分布式事务的文章,发现会有不同的描述,但大致含义是相同的。分布式事务首先是事务, 需要满足事务的ACID的特性。主要考虑业务访问处理的数据分散在网络间的多节点上,对于分布式数据库系统而言, 在保证数据一致性的要求下,进行事务的分发、协同多节点完成业务请求。
多节点能否正常、顺利的协同作业完成事务是关键,它直接决定了访问数据的一致性和对请求响应的及时性。从而就需要科学有效的一致性算法来支撑。
3. 一致性算法
目前主要的 一致性算法 包括 :2PC 、 3PC 、 Paxos 、 Raft 。
2PC :Two-Phase Commit ( 二阶段提交 ) 也被认为是一种一致性协议,用来保证分布式系统数据的一致性。绝大部分的关系型数据库都是采用二阶段提交协议来完成分布式事务处理。
主要包括以下两个阶段:
第一阶段:提交事务请求(投票阶段)
第二阶段:执行事务提交(执行阶段)
优点:原理简单、实现方便
缺点:同步阻塞、单点问题、数据不一致、太过保守
3PC :Three- Phase Commi ( 三阶段提交 )包括 CanCommit、PreCommit、doCommit 三个阶段。
为了避免在通知所有参与者提交事务时,其中一个参与者 crash 不一致时,就出现了三阶段提交的方式。
三阶段提交在两阶段提交的基础上增加了一个 preCommit 的过程,当所有参与者收到 preCommit 后,并不执行动作,直到收到 commit 或超过一定时间后才完成操作。
优点:降低参与者阻塞范围,并能够在出现单点故障后继续达成一致 缺点:引入 preCommit 阶段,在这个阶段如果出现网络分区,协调者无法与参与者正常通信,参与者依然会进行事务提交,造成数据不一致。
2PC / 3PC 协议用于保证属于多个数据分片上操作的原子性。
这些数据分片可能分布在不同的服务器上,2PC / 3PC 协议保证多台服务器上的操作要么全部成功,要么全部失败。
Paxos 、 Raft 、 Zab 算法用于保证同一个数据分片的多个副本之间的数据一致性 。以下是三种算法的概要描述 。
Paxos 算法主要解决数据分片的单点问题 , 目的是让整个集群的结点对某个值的变更达成一致。Paxos (强一致性) 属于多数派算法 。任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意,所以 Paxos 算法需要集群中的结点是单数 。
Raft 算法是简化版的Paxos, Raft 划分成三个子问题:一是Leader Election;二是 Log Replication;三是Safety。Raft 定义了三种角色 Leader、Follower、Candidate,最开始大家都是Follower,当Follower监听不到Leader,就可以自己成为Candidate,发起投票 ,选出新的leader 。
其有两个基本过程:
① Leader选举:每个 C andidate随机经过一定时间都会提出选举方案,最近阶段中 得 票最多者被选为 L eader。
② 同步log:L eader会找到系统中log(各种事件的发生记录)最新的记录,并强制所有的follow来刷新到这个记录。
Raft一致性算法是通过选出一个leader来简化日志副本的管理,例如,日志项(log entry)只允许从leader流向follower。ZAB基本与 raft 相同。
三、PostgreSQL 分布式架构一览
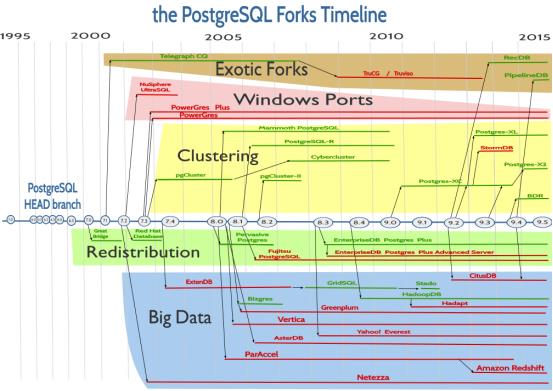
PostgreSQL发展时间线及分支图
1. 基于内核分布式方案 Postgres-XL
(1) 什么是Postgres-XL
Postgres-XL是一款开源的PG集群软件,XL代表eXtensible Lattice,即可扩展的PG“格子”之意,以下简称PGXL。
官方称其既适合写操作压力较大的OLTP应用,又适合读操作为主的大数据应用。它的前身是Postgres-XC(简称PGXC),PGXC是在PG的基础上加入了集群功能,主要适用于OLTP应用。PGXL是在PGXC的基础上的升级产品,加入了一些适用于OLAP应用的特性,如 Massively Parallel Processing (MPP) 特性。
通俗的说PGXL的代码是包含PG代码,使用PGXL安装PG集群并不需要单独安装PG。这样带来的一个问题是无法随意选择任意版本的PG,好在PGXL跟进PG较及时,目前最新版本Postgres-XL 10R1,基于PG 10。
社区发展史:
2004~2008 年, NTT Data 构建了模型 Rita-DB
2009 年, NTT Data 与 EnterpriseDB 合作进行社区化开发
2012 年, Postgres-XC 1.0 正式发布
2012 年, StormDB 在 XC 基础上增加 MPP 功能 .
2013 年, XC 1.1 发布 ;TransLattice 收购 StormDB
2014 年, XC 1.2 发布 ;StormDB 开源为 Postgres-XL.
2015 年,两个社区合并为 Postgres-X2
2016 年 2 月, Postgres-XL 9.5 R1
2017年7月 , Postgres-XL 9.5 R1.6
2018年10月 , Postgres-XL 10R1
2019 年 2 月 , 宣布推出Postgres-XL 10R1 .1

PostgreSQL与PGXC对比图(浙江移动谭峰分享)
(2) 技术架构
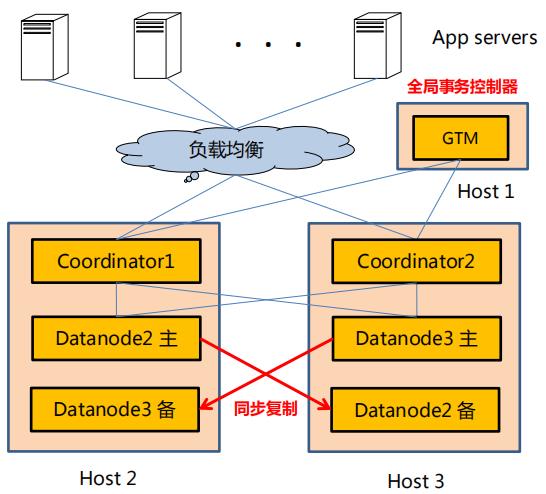
架构图1
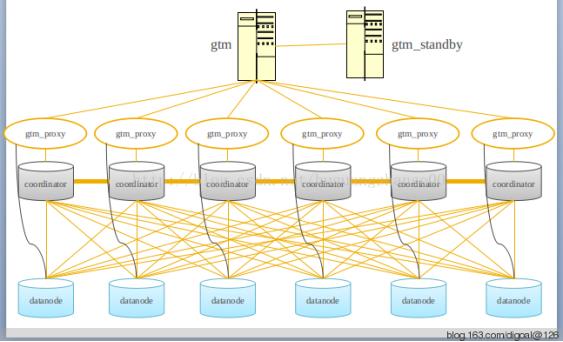
架构图2
从上图可以看出Coordinator和datanode节点可以配置为多个,并且可以位于不同的主机上。只有Coordinator节点直接对应用服务,Coordinator节点将数据分配存储在多个数据节点datanode上。
Postgres-XC主要组件有gtm(Global Transaction Manager) , gtm_standby , gtm_proxy, Coordinator 和Datanode。
全局事务节点 ( GTM ), 是Postgres-XC的核心组件,用于全局事务控制以及tuple的可见性控制。gtm 为分配GXID和管理PGXC MVCC的模块 , 在一个CLUSTER中只能有一台主的gtm。gtm_standby 为gtm的备机 。
主要作用:
– 生成全局唯一的事务ID
– 全局的事务的状态
– 序列等全局信息
gtm_proxy为降低gtm压力而诞生的, 用于对coordinator节点提交的任务进行分组等操作. 机器中可以存在多个gtm_proxy。
协调节点 (Coordinator) 是数据节点 (Datanode) 与应用之间的接口, 负责接收用户请求、生成并执行分布式查询、 把 SQL 语句发给相应的数据节点。
Coordinator 节点并不物理上存储表数据,表数据以分片或者复制的方式分布式存储,表数据存储在数据节点上。当应用发起SQL时,会先到达 Coordinator 节点,然后 Coordinator节点将 SQL分发到各个数据节点,汇总数据,这一系统过程是通过GXID 和Global Snapshot 再 来控制的。
数据节点(datanode)物理上存储表数据,表数据存储方式分为分片(distributed)和完全复制(replicated)两种。数据节点只存储本地的数据。
数据分布
• replicated table 复制表
– 表在多个节点复制
• distributed table 分布式表
– Hash
– Round robin
注释:Round robin 轮流放置是最简单的划分方法:即每条元组都会被依次放置在下一个节点上,如下图所示,以此进行循环。
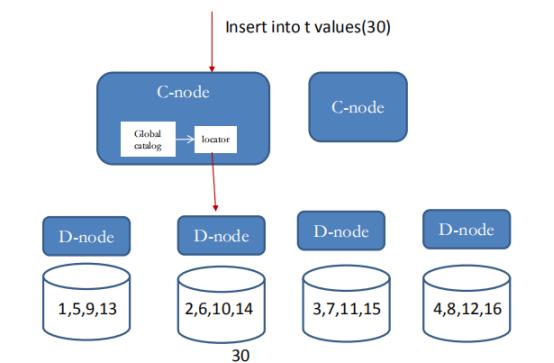
(3) 主要站点
https://www.postgres-xl.org/overview/
https://wiki.postgresql.org/wiki/Postgres-XC
2. 扩展分布式方案Citus
(1) 什么是Citus
Citus是一款基于PostgreSQL的开源分布式数据库 , 自动继承了PostgreSQL强大的SQL支持能力和应用生态(不仅是客户端协议的兼容还包括服务端扩展和管理工具的完全兼容)。Citus是PostgreSQL的扩展(not a fork),采用shared nothing架构,节点之间无共享数据,由协调器节点和Work节点构成一个数据库集群。专注于高性能HTAP分布式数据库 。
相比单机PostgreSQL,Citus可以使用更多的CPU核心,更多的内存数量,保存更多的数据。通过向集群添加节点,可以轻松的扩展数据库。
与其他类似的基于PostgreSQL的分布式方案,比如GreenPlum,PostgreSQL-XL相比,Citus最大的不同在于它是一个PostgreSQL扩展而不是一个独立的代码分支。Citus可以用很小的代价和更快的速度紧跟PostgreSQL的版本演进;同时又能最大程度的保证数据库的稳定性和兼容性。
Citus支持新版本PostgreSQL的特性,并保持与现有工具的兼容 。Citus使用分片和复制在多台机器上横向扩展PostgreSQL。它的查询引擎将在这些服务器上执行SQL进行并行化查询,以便在大型数据集上实现实时(不到一秒)的响应。
Citus目前主要分为以下几个版本:
Citus社区版
Citus商业版
Cloud [AWS,citus cloud]
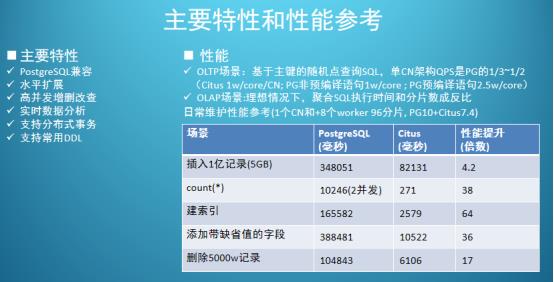
本截图引用2020年3月苏宁陈华军Citus的实践分享
(2) 技术架构
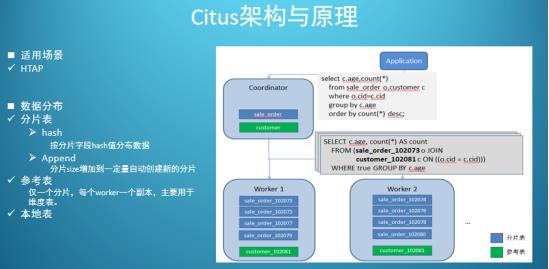
本截图引用2020年3月苏宁陈华军Citus的实践分享
Citus集群由一个中心的协调节点(CN)和若干个工作节点(Worker)构成。
CN只存储和数据分布相关的元数据,实际的表数据被分成M个分片,打散到N个Worker上。这样的表被叫做“分片表”,可以为“分片表”的每一个分片创建多个副本,实现高可用和负载均衡。
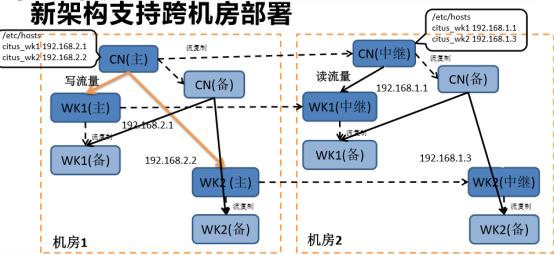
架构图1(引用2019年苏宁Citus实践分享)
Citus官方文档更建议使用PostgreSQL原生的流复制做HA,基于多副本的HA也许只适用于append only的分片。
应用将查询发送到协调器节点,协调器处理后发送至work节点。对于每个查询协调器将其路由到单个work节点,或者并行化执行,这取决于数据是否在单个节点上还是在多个节点上。Citus MX模式允许直接对work节点进行访问,进行更快的读取和写入速度。
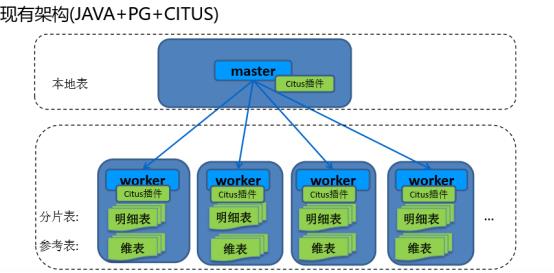
架构图2(引用2019年苏宁Citus实践分享)
Citus有三种类型表
分片表(最常用)
参考表
本地表
分片表主要解决的是大表的水平扩容问题,对数据量不是特别大又经常需要和分片表Join的维表可以采用一种特殊的分片策略,只分1个片且每个Worker上部署1个副本,这样的表叫做“参考表”。
除了分片表和参考表,还剩下一种没有经过分片的PostgreSQL原生的表,被称为“本地表”。“本地表”适用于一些特殊的场景,比如高并发的小表查询。

本截图引用2020年3月苏宁陈华军Citus的实践分享
客户端应用访问数据时只和CN节点交互。CN收到SQL请求后,生成分布式执行计划,并将各个子任务下发到相 应的Worker节点,之后收集Worker的结果,经过处理后返回最终结果给客户端。

本截图引用2020年3月苏宁陈华军Citus的实践分享
(3) 主要站点
http://citusdb.cn/
https://docs.citusdata.com/en/v8.2/
四、 总结
应对大数据量、高并发混合业务数据访问,数据管理需要分布式数据库架构的有效支撑,以下总结了几个主要关键词:
1. 业务融合——TP/AP业务自动识别,职能调度运算节点;实时流处理;关系与非关系数据访问、转换;
2. 节点协同——多个计算节点协同作业;数据多副本;同城、异地多活;
3. 冷热分离——定期定时统计,自动标记冷热数据,根据存储速度存储不同冷热程度的数据;
4. 架构解耦——微服务、计算存储分离;
5. 弹性伸缩——在线伸缩;自动平衡数据;
6. 智能运维——自动调优;自动升降级;运行可视化,自动告警。
参考资料:
分布式数据库概念:
·《分布式系统数据库系统原理》(第三版)
CAP理论 :
·《Understanding the CAP Theorem》/ Akhil Mehra
·《CAP和BASE理论》/ ~信~仰~
Base理论:
·《终于有人把“分布式事务”说清楚了!》/ 陈明羽
·《强一致性、顺序一致性、弱一致性和共识》/ chao2016
一致性算法:
·《分布式理论系列(二)一致性算法:2PC 到 3PC 到 Paxos 到 Raft 到 Zab》/ binarylei
·《Paxos和Raft快速理解》/ 建怀
PGXL
·《初识Postgres-XL》/ joyeu
Citus
· 博客“小桥河西 ”
·《PostgreSQL中的分库分表解决方案》/ 唐成
(链接请点击阅读原文)
原题:分布式数据库原理及 PostgreSQL 分布式解读 如有任何问题,可点击文末阅读原文,到社区原文下评论交流
觉得本文有用,请转发或点击“在看”,让更多同行看到
资料/文章推荐:
下载 twt 社区客户端 APP

或到应用商店搜索“twt”
以上是关于分布式数据库理论基础 & PostgreSQL 分布式架构 | 周末送资料的主要内容,如果未能解决你的问题,请参考以下文章
分布式数据库理论基础 & PostgreSQL 分布式架构 | 周末送资料