云会让DBA失业吗?分布式数据库学习路径CAP理论?OLAP/OLTP & MPP/SMP
Posted 架构头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云会让DBA失业吗?分布式数据库学习路径CAP理论?OLAP/OLTP & MPP/SMP相关的知识,希望对你有一定的参考价值。
编辑 | 木环
本文源自InfoQ大咖说直播节目第37期《分布式数据库的那些事儿》,节目邀请到了阿里巴巴中间件团队高级技术专家励强和 PingCAP CTO 黄东旭两位嘉宾,下文为两位嘉宾与网友之间部分互动问答的整理。更多问答可以查看文末的节目录像回放。
励强:5 年之内,我觉得 DBA 对于基础 DB 运维和开发支持还是会大量存在,一个原因是云产品、新技术的成熟和触达业务需要有相当长的时间,另外一个原因是业务规模和广度还在不断扩大,需求缺口还在不断扩大。而未来 10 年内,DBA 职责和能力模型会发生一些改变,具备专业 DB 知识,同时具备开发系统工具以提升运维、诊断和业务开发效率的能力,工作内容、职责上会更加丰富和深入。数据库问题会一直存在,除非达到相当先进的智能化,否则 DBA 这个职业会一直存在。
黄东旭:我个人看法比较偏激一些。在我看来 DBA 可能会越来越转向 SRE 和 DevOps 这样的角色。未来,在一个巨大规模的数据库集群上面,人能做的事情其实是越来越少的,比如去运维一个几千规模的数据库集群,每天都有可能发生宕机、磁盘损坏、网络的抖动各种各样的问题,而人所能拯救过来的问题其实越来越少。我认为未来数据库需要能自己运维自己、自己去修复自己,人在里面的角色基本上就是添加机器、下线坏机器这样的一个角色。DBA 会分成两条路线,第一条是去做性能调优,针对业务场景写出更好的 SQL;第二条就是能够走向 SRE 的道路,去做 Cloud 的运维或者开发一些面向云的工具。
黄东旭:其实分布式数据库只是分布式系统的一个分支,而且这个分支比较新。初学的话可以先从分布式系统比如存储入手,其实我个人学习的入门路径是,我把当年 Google 的 Map Reduce、Big Table 的几篇论文都看了,看完了之后再看很多系统就明白了大同小异,还有Amazon Dynamo 的一个入门级别论文,包括像 Paxos 和 Raft 的论文等分布式一致性的理论。其实我个人建议,盯着 Google 每年发的论文就好了,其实比较好看懂,而且是经过了大规模生产环境验证的论文。反而是看书和看 Blog 的速度比较慢,我个人是比较喜欢看论文。
励强:我的观点不太一样。如果是普通学习者,个人建议先理解传统数据库的设计理念,比如解析器、优化器、执行器、存储模型(行存、列存、page、block 等)、索引模型、计算模型等知识的了解,然后再切入到分布式数据库领域,可以看一些论文,比如 MetaStore、Percolator、Spanner、F1、Dynamo 等等,最后我觉得可以深入到一些优秀开源项目的源代码中,体会关键特性的实现要素,目前单机数据库以及优秀分布式数据库开源项目非常多,最后的最后,如果有机会,还是能够一起共事面对实际场景,解决客户问题,可以投递简历到阿里中间件 DRDS 产品这边:)
这样的方式会更加的循序渐进。从我个人的成长经历来看,一开始就看论文或者直接探索分布式数据库是非常吃力的,反倒是了解了单机数据库的实现方式和原理,也体会到这个领域目前所遇到的问题后,再切入分布式数据库领域,就感觉比较自然。
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:一致性(Consistence) (等同于所有节点访问同一份最新的数据副本)可用性(Availability)(对数据更新具备高可用性)容忍网络分区(Network partitioning)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
备注:取自维基百科
黄东旭:CAP 理论中的 C,我们首先抛开不论是不是副本实现。单纯地讲,写入数据之后再读出来,如果读到新的值不一样,就是不满足 C。多副本的情况下,并不是说每个副本的数据都完全一致才叫满足 C。而是说提供给用户的接口是满足强一致的情况下,我们就可以说是满足 C 的。比如写入一条数据有三个副本,有两个已经写入了,第三个是通过异步的方式;这时候leader 或者某一个访问存储的节点宕机了,这时候如果还要满足 C 的话,这个时候的业务请求一定要从更新的负载上去给你提供服务,而不是旧的那个区给你提供服务,所以如何保证在failover 的过程中,出现网络分区的情况下,还能让更新的数据返回。(像 Raft、Paxos 解决 C的问题。)
在落地 CAP 的时候,PingCAP 遵循的原则是强 C 和强 P,A 是永远不能达到完美的。在没有Raft 和 Paxos 这种高可用的模型的时候,原来是使用的主从模式,主挂了,让从起来当主,其实还是要有 DBA 来 check 有无数据丢失、数据有没有同步完、人工地去把它提上来等,但是这个故障恢复的时间就太长了。有了 Raft 和 Paxos 就可以在解决满足强一致的基础上,去自动地把可用性提到一个可用级别;但是这个 A 要变成 HA(High Availability)。
励强:有网友刚才发言说,放弃 A 很有特点。确实,一般而言大家都会放弃 C。
黄东旭:但是放弃 C 的话,业务就会很难写。
励强:是的,需要在业务上对数据中间状态做一定的保护,比如数据状态机等逻辑判定,对业务会有一定的侵入性。
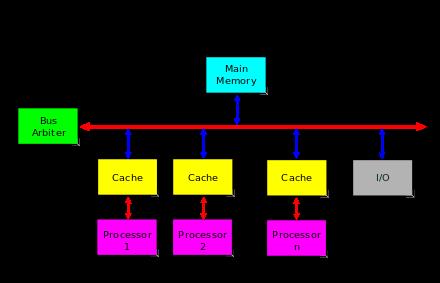
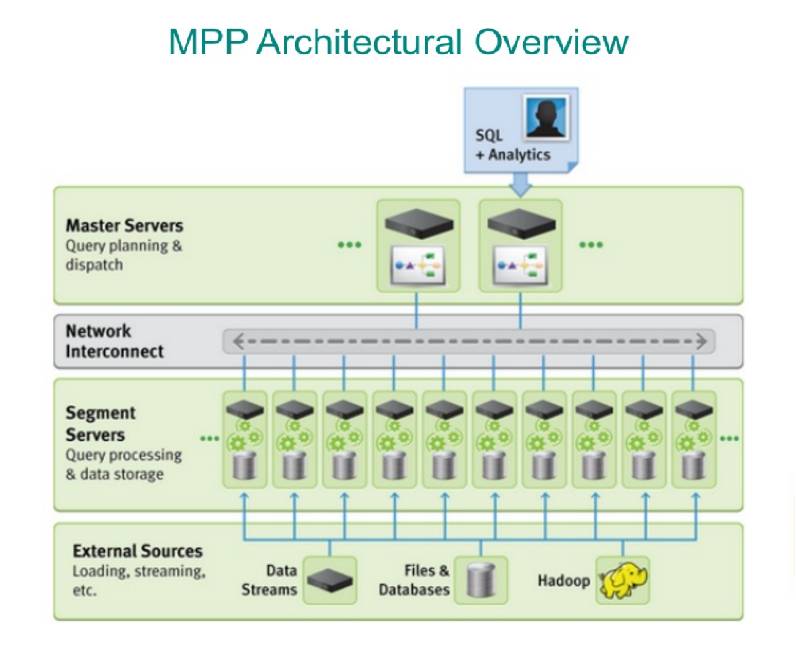
备注:上图取自Pivotal的演讲分享Massively Parallel Processing with Procedural Python (PyData London 2014)
黄东旭:大家在接触分布式 SQL 和 Hive 发现为什么 Hive 这么慢,因为 Hive 是把SQL 转换成 Hadoop 的 Map Reduce 计算,中间结果都是要落在 HDFS 上面的,这样的速度自然就比较慢了。包括后来的 Impala、Presto,跟 Hadoop 不太相关的 Greenplum 包括 Spark SQL;整个像一个流式计算的结构。中间结果并不会强行地写入到 HDFS 或者中间存储上,而是通过Re-shuffle 或是流式节点的直接传递到下一个计算的单位上,这样整体效率就会非常高;然后另一方面就是优化器的(不管是 MPP 也好还是 SMP),先说 SMP 吧,你怎么把一个分布式也好,一个 SQL 的执行计划能够生成更加并行、可以利用整个集群并发能力去做计算,这么的一个 SQL 优化器,其实这个和单机优化器的思路是非常不一样的。像 SMP 的 SQL 优化器会尽量把查询给 push down,包括谓词下推、聚合算子下推都可以做,但是最后聚合可能还是会受限于单个节点的物理内存等资源。
MPP 相当于把单点聚合的问题让这个集群去承担,所以本质上它的 SQL 优化器层上的思想和手段是可以复用的。只不过和分布式计算框架,在 SMP 之上去做一层流式计算框架能搞定的事情,但是其实现在就我的观察来说,至少 80% 我们在 TiDB 应用于 OLAP 遇到的场景,SMP 的这个模式基本就够用了。然后 MPP 的需求,我们会做的是能让 Spark SQL 的查询计划直接去 TiKV(TiDB 的存储层)上去直接 load 数据,直接把 Spark SQL 的算子直接在 TiKV 这一层去实现,一份存储多个 SQL 的引擎,相当于那边充当一个很高效 MPP 的 Engine。所以常规的 OLAP 查询可以通过 SMP, 80-90% 都可以满足。
励强:相当于把 MPP 的工作外包给 Spark:)
MPP 相当于一个计算框架或者计算模型,在 OLAP 领域广泛使用的计算技术已经慢慢在分布式数据库领域(OLTP)有了一些应用,但是在 OLAP 领域计算资源的调度是具有决定性作用,而这个对于分布式数据库(OLTP)来说,目前暂时没看到非常好的实现,这其中的难度在于 OLTP 对于数据计算的实时性是有比较高的要求。DRDS 产品设计之初就将MPP考虑在未来的发展轨道中,通过执行计划的构造分解和传输实现分布式数据检索计算的效果,而现在我们主要把精力集中在 SMP 上,单机并行度的提升存在下行和上行两个角度,下行指并行下发操作,上行指并行进行结果过滤、聚合和计算,其中上行还存在单请求多分片数据并行计算的优化。
目前,无论是 SMP 还是 MPP,用户的需求是大量存在的,在做好这些计算优化的同时,我们也可以转变思路在存储模型、索引模型上有更多的探索,或者也可以通过匹配特殊硬件的方式弯道超车,比如使用 FPGA, Fiber Channel 等硬件,也许原先的目标很容易就达到了。
视频嘉宾分享的部分回顾版文字为
QCon是由InfoQ主办的全球顶级技术盛会,每年在伦敦、北京、东京、纽约、圣保罗、上海、旧金山召开。
QCon北京2017将于4月16日~18日在北京·国家会议中心举行,精心设计了支撑海量业务的互联网架构、大规模网关系统、微服务实践、快速进化的容器生态、智能化运维、互联网广告系统实践、大数据实时计算与流处理和金融科技转型与未来等30来个专题,涵盖架构、大数据、云计算、移动、前端、人工智能等热点领域,将邀请来自Google、Facebook、阿里巴巴、腾讯、百度、美团点评、爱奇艺等典型互联网公司的技术专家,分享技术领域最新成果。敬请期待。

以上是关于云会让DBA失业吗?分布式数据库学习路径CAP理论?OLAP/OLTP & MPP/SMP的主要内容,如果未能解决你的问题,请参考以下文章
CAP理论提出者解读全球级分布式数据库:Spanner, TrueTime 和CAP理论