图邻接矩阵训练数据的标准化及批归一化的原则
Posted MarToony|名角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图邻接矩阵训练数据的标准化及批归一化的原则相关的知识,希望对你有一定的参考价值。
主要内容:
1 图邻接矩阵的标准化原则(面向行,即起始节点)及代码实现;
2 训练数据的标准化的原则(面向各个独立的特征)和代码实现;
3 BatchNormal批归一化的原则(面向各个通道C)。
一、图邻接矩阵的标准化原则和代码实现
- 标准化是将数据规范到均值为0,方差为1的分布规律中。归一化是将数据规范到[0,1]区间之中,比较严格,标准化允许负数且理论上允许正无穷和负无穷的值的存在。
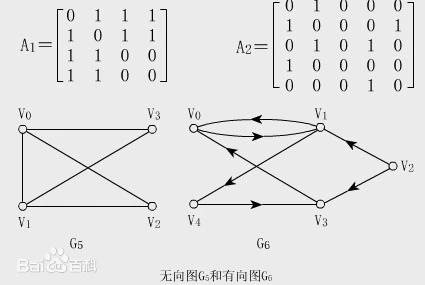
- 图的邻接矩阵
A
A
A是
(
n
,
n
)
(n,n)
(n,n)形状 ,且矩阵的标准化是通过
A
A
A与其度矩阵的点乘得到。具体的来说,邻接矩阵的第一维度表示图中的起始节点,第二维度表示终止节点,见图1示。其次,邻接矩阵的度矩阵中的
N
N
N个值,依次对应各个起始点的度,即其连接的顶点的数目。因此标准化其实是面向每一行(每一个起始节点),而非
n
∗
n
n*n
n∗n的数值加和的倒数。这一点通过python code 来具象化表示,见本节的第三点。
- 图邻接矩阵的标准化的代码:
# 图卷积的预处理 def normalize_digraph(A): Dl = np.sum(A, 0) #计算邻接矩阵的度 num_node = A.shape[0] Dn = np.zeros((num_node, num_node)) for i in range(num_node): if Dl[i] > 0: Dn[i, i] = Dl[i]**(-1) #由每个点的度组成的对角矩阵 AD = np.dot(A, Dn) return AD
二、训练数据的标准化的原则和代码实现
-
sklearn.preprocessing.StandardScaler 的API中有相关的解释:
Centering and scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. Mean and standard deviation are then stored to be used on later data using transform.
意思是:通过计算训练样本的相关统计信息,对每个特征独立地进行对中心化和缩放scale,即单独地计算各个特征自己的均值和方差,并保存起来,以供以后transform使用。
所以训练数据标准化的原则也就有了:面向各个特征计算均值和方差值以计算。 -
多特征的训练数据的标准化代码:
- 借鉴sklearn中StandardScaler的source源码的transform的代码:
标准差API的无偏计算的说明(ddof):https://blog.csdn.net/Gooooa/article/details/78923469。x: (m,n) m个样本,n个特征; self.mean_ = x.mean(axis=0).copy() self.scale_ = x.std(axis=0, ddof = 1).copy() # numpy.std() 求标准差的时候默认是除以 n 的,即是有偏的,np.std无偏样本标准差方式为加入参数 ddof = 1;numpy默认是有偏的;而pandas默认是无偏的,即处以n-1的。 # if self.with_mean: # 是否进行中心化 X -= self.mean_ # self.mean_ 是由n个特征的 均值 构成的一维向量; if self.with_std:# 是否进行缩放 X /= self.scale_ # self.scale_ 是由n个特征的 方差值 构成的一维向量; - 均值和标准差编写了归一化和反归一化函数:
def feature_normalize(data): mu = np.mean(data,axis=0) # 均值 std = np.std(data,axis=0) # 标准差 return (data - mu)/std def feature_unnormalize(data, arr): mu = np.mean(data,axis=0) std = np.std(data,axis=0) return arr * std + mu
- 借鉴sklearn中StandardScaler的source源码的transform的代码:
三、BatchNormal批归一化的原则
- 批归一化,是通过减少内部空间的协变量偏移来加深深度网络训练。公式与普通的标准化的公式类似,只是增加了一些可学习的参数来得到估计的较适合的标准化后的值。
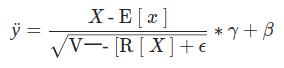
- 无论是一维批归一化
BatchNorm1d还是二维批归一化BatchNorm2d,其都是面向X数据集的第二维度,通常成为特征通道数目。
pytorch的官网中有一句描述:Because the Batch Normalization is done over the C dimension, computing statistics on (N, H, W) slices, it’s common terminology to call this Spatial Batch Normalization..
意思是,由于二维批归一化是在C维上,通过计算每个C_i的(N,H,W)切片的统计信息完成的,所以通常地将此术语称之为:空域批归一化Spatial Batch Normalization;相应地,一维批归一化称为:时域批归一化Temporal Batch Normalization。 - 一维批归一化的代码实现:
Applies Batch Normalization over a 2D or 3D input
I n p u t : ( N , C ) o r ( N , C , L ) Input: (N, C)or (N, C, L) Input:(N,C)or(N,C,L)
O u t p u t : ( N , C ) o r ( N , C , L ) ( s a m e s h a p e a s i n p u t ) Output: (N, C) or (N, C, L) (same shape as input) Output:(N,C)or(N,C,L)(sameshapeasinput)>>> # With Learnable Parameters >>> m = nn.BatchNorm1d(100) >>> # Without Learnable Parameters >>> m = nn.BatchNorm1d(100, affine=False) >>> input = torch.randn(20, 100) >>> output = m(input) - 二维批归一化的代码实现:
Applies Batch Normalization over a 3D or 4D input
I n p u t : ( N , C , H , W ) Input: (N, C, H, W) Input:(N,C,H,W)
O u t p u t : ( N , C , H , W ) ( s a m e s h a p e a s i n p u t ) Output: (N, C, H, W) (same shape as input) Output:(N,C,H,W)(sameshapeasinput)>>> # With Learnable Parameters >>> m = nn.BatchNorm2d(100) >>> # Without Learnable Parameters >>> m = nn.BatchNorm2d(100, affine=False) >>> input = torch.randn(20, 100, 35, 45) >>> output = m(input)
以上是关于图邻接矩阵训练数据的标准化及批归一化的原则的主要内容,如果未能解决你的问题,请参考以下文章
深度学习之 BN(Batch Normalization)批归一化