Keras深度学习实战——批归一化详解
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战——批归一化详解相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(5)——批归一化详解
0. 前言
批归一化是神经网络中关键性技术之一,使用批归一化可以大幅加快网络的收敛,同时提高网络的泛化能力,也就说,批归一化可以用于缓解模型的过拟合问题。
1. 批归一化基本概念
在《神经网络模型性能优化技术》中,我们了解到,如果不缩放输入数据,则权重优化的速度很慢。这是由于当面临以下情况时,隐藏层的值可能会很过大:
- 输入数据值较大
- 权重值较大
- 权重和输入的乘积结果较大
以上任何一种情况都可能导致隐藏层具有较大输出值,隐藏层可以视为输出层的输入层。因此,当隐藏层值也很大时,同样会导致网络优化缓慢,批归一化 (Batch Normalization, BN) 的提出就是为了解决这一问题。
我们简单回顾下批训练的概念,一般在网络的计算过程中会同时计算多个样本,这种训练方式叫做批训练,其中一个批中样本的数量叫做 Batch Size。我们已经了解到,当输入值很高时,我们可以通过使用缩放以减小输入值。此外,我们也了解了多种数据缩放的方法,其中包括减去输入的平均值并将其除以输入的标准差,而批归一化就是使用这种缩放的方法。通常,首先使用以下公式计算网络层批数据的均值和方差:
μ
B
=
1
m
∑
i
=
1
m
x
i
批
数
据
均
值
σ
B
2
=
1
m
∑
i
=
1
m
(
x
i
−
μ
B
)
2
批
数
据
方
差
\\begincases \\mu_B = \\frac 1 m \\sum_i=1^m x_i &\\text 批数据均值\\\\ \\sigma_B^2 = \\frac 1 m \\sum_i=1^m (x_i-\\mu_B)^2 &\\text 批数据方差\\\\ \\endcases
μB=m1∑i=1mxiσB2=m1∑i=1m(xi−μB)2批数据均值批数据方差
计算得到网络层批输入数据的均值和方差后,使用以下公式缩放网络层的输入值:
在训练过程中网络会学习 γ γ γ 和 β β β 以及网络的权重参数。在接下来中,我们将通过改进原始神经网络应用批规一化。
2. 在神经网络训练过程中使用批归一化
首先需要导入 BatchNormalization 方法,如下所示:
from keras.layers.normalization import BatchNormalization
实例化模型并构建神经网络模型,在隐藏层中执行批归一化:
from keras.layers.normalization import BatchNormalization
model = Sequential()
model.add(Dense(1000, input_dim=num_pixels, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(num_classes, activation='softmax'))
可以看到,使用批归一化和使用网络层的方法是一样的,可以将批归一化当作一个网络层添加 (add),需要注意的是,实际上它并非网络层。接下来,编译并训练模型:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=50,
batch_size=64,
verbose=1)
使用批归一化训练比没有批归一化时的训练速度要快得多,下图显示了使用批归一化的训练和测试损失以及准确性:
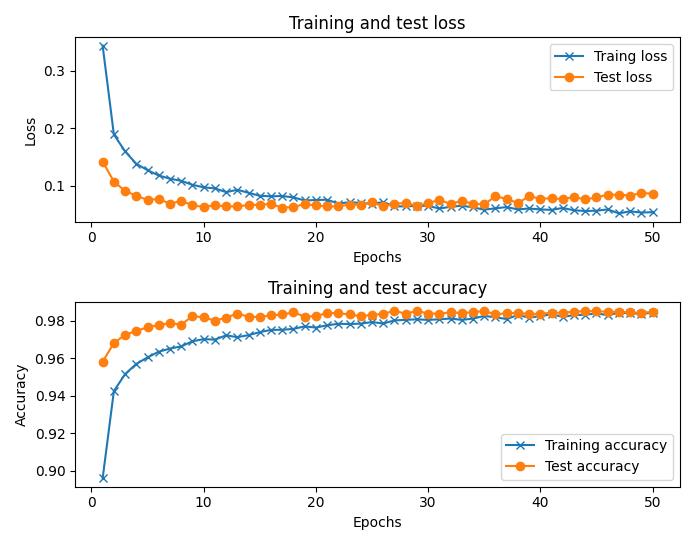
小结
本节我们首先回顾了导致网络训练缓慢的原因,然后介绍了如何在网络训练中,缩放网络层中的数据表示加快网络训练,即批归一化。然后通过实际的网络训练,在网络中使用了批归一化。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术详解
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
以上是关于Keras深度学习实战——批归一化详解的主要内容,如果未能解决你的问题,请参考以下文章