深度学习:批归一化和层归一化Batch NormalizationLayer Normalization
Posted -柚子皮-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习:批归一化和层归一化Batch NormalizationLayer Normalization相关的知识,希望对你有一定的参考价值。
深度神经网络模型训练难,其中一个重要的现象就是 Internal Covariate Shift. Batch Norm 自 2015 年由Google 提出之后, Layer Norm / Weight Norm / Cosine Norm 等也横空出世。BN,Batch Normalization,就是在深度神经网络训练过程中使得每一层神经网络的输入保持相近的分布。
BN的来源Motivation
1.1 独立同分布与白化
1.2 深度学习中的 Internal Covariate Shift
作者认为:网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,因此我们不得不降低学习率、小心地初始化。作者将分布发生变化称之为 internal covariate shift。
大家应该都知道,我们一般在训练网络的时会将输入减去均值,还有些人甚至会对输入做白化等操作,目的是为了加快训练。为什么减均值、白化可以加快训练呢,这里做一个简单地说明:首先,图像数据是高度相关的,假设其分布如下图a所示(简化为2维)。由于初始化的时候,我们的参数一般都是0均值的,因此开始的拟合y=Wx+b,基本过原点附近,如图b红色虚线。因此,网络需要经过多次学习才能逐步达到如紫色实线的拟合,即收敛的比较慢。如果我们对输入数据先作减均值操作,如图c,显然可以加快学习。更进一步的,我们对数据再进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图d。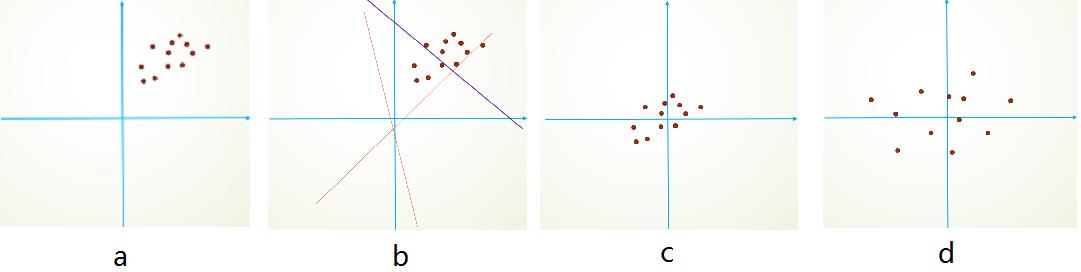
白化的方式有好几种,常用的有PCA白化:即对数据进行PCA操作之后,在进行方差归一化。这样数据基本满足0均值、单位方差、弱相关性。作者首先考虑,对每一层数据都使用白化操作,但分析认为这是不可取的。因为白化需要计算协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,白化操作不一定可导。于是,作者采用下面的Normalization方法。
Normalization via Mini-Batch Statistics
数据归一化方法很简单,就是要让数据具有0均值和单位方差,如下式: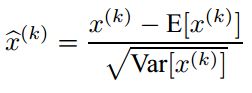
但是如果简单的这么干,会降低层的表达能力。比如下图,在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。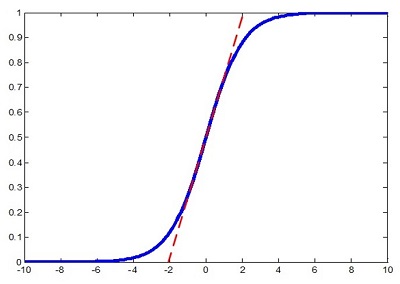
为此,作者又为BN增加了2个参数,用来保持模型的表达能力: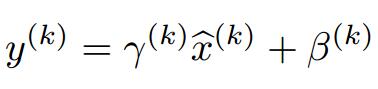
上述公式中用到了均值E和方差Var,需要注意的是理想情况下E和Var应该是针对整个数据集的,但显然这是不现实的。因此,作者做了简化,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
整个BN的算法如下:
求导的过程也非常简单,有兴趣地可以自己再推导一遍或者直接参见原文。
总结一下:
Normalization 的通用公式
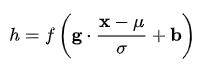

BN与常用的数据归一化最大的区别就是加了后面这两个参数,这两个参数主要作用是在加速收敛和表征破坏之间做的trade off。以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域, 只包含线性变换,破坏了之前学习到的特征分布。为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数w和b ,即规范化后的隐层表示将输入数据限制到了一个全局统一的确定范围,为了保证模型的表达能力不因为规范化而下降,引入了b是再平移参数,w是再缩放参数。[LayerNorm结构有参数吗,参数的作用?]
- m = K.mean(X, axis=-1, keepdims=True)#计算均值
- std = K.std(X, axis=-1, keepdims=True)#计算标准差
- X_normed = (X - m) / (std + self.epsilon)#归一化
- out = self.gamma * X_normed + self.beta#重构变换
BN训练和测试时的差异
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此用的是全量训练数据的均值和方差,可以通过移动平均法求得。
BN训练时为什么不用全量训练集的均值和方差呢?
因为用全量训练集的均值和方差容易过拟合,对于BN,其实就是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上能够增加模型的鲁棒性,也会在一定程度上减少过拟合。也正是因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,否则,一个batch的数据无法较好得代表训练集的分布,会影响模型训练的效果。
具体在tf的解释看下面tf函数说明。
BN的dropout共同使用时的要注意的问题
[深度学习:正则化]
Batch Normalized的作用
1)改善流经网络的梯度
2)允许更大的学习率,大幅提高训练速度:你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
3)减少对初始化的强烈依赖
4)改善正则化策略:作为正则化的一种形式,轻微减少了对dropout的需求你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
5)再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
6)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)。
Batch-normalized对于优化的作用
How Does Batch Normalization Help Optimization?

[https://arxiv.org/pdf/1805.11604.pdf]
BN解决梯度消失的原因:
考虑一些具体的激活函数。我们看到,无论是tanh还是sigmoid
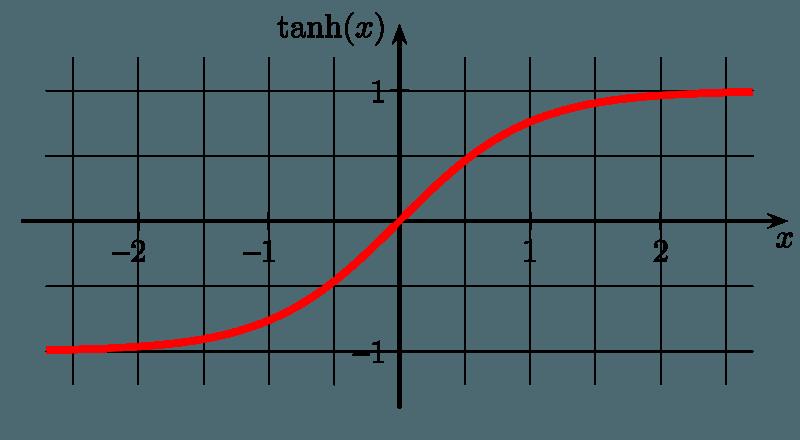
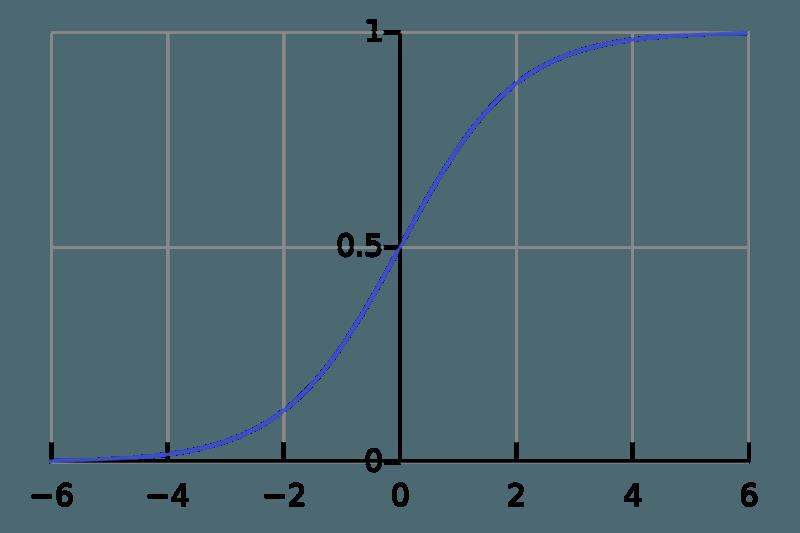
函数图像的两端,相对于x的变化,y的变化都很小(这其实很正常,毕竟tanh就是拉伸过的sigmoid),也就是说,容易出现梯度衰减的问题。那么,如果在tanh或sigmoid之前,进行一些normalization处理,就可以缓解梯度衰减的问题。所以最初的BN论文选择把BN层放在非线性激活之前。
但是ReLU的画风和它们完全不一样啊。
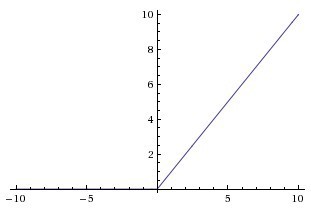
实际上,最初的BN论文虽然也在使用ReLU的Inception上进行了试验,但首先研究的是sigmoid激活。因此,试验ReLU的,我猜想作者可能就顺便延续了之前把BN放前面的配置,而没有单独针对ReLU进行处理。
[Batch-normalized 应该放在非线性激活层的前面还是后面?]
所以Batch-normalized 应该放在非线性激活层的前面还是后面?
You have the choice of applying batch normalization either before or after the non-linearity, depending on your definition of the “activation distribution of interest” that you wish to normalize. It will probably end up being a hyperparameter that you’ll just have to tinker with.BN放在非线性函数前还是后取决于你想要normalize的对象,更像一个超参数。
[Batch-normalized 应该放在非线性激活层的前面还是后面?]
Batch Normalization —— 纵向规范化
Batch Normalization 针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元 x_i 的均值和方差,因而称为 Batch Normalization。
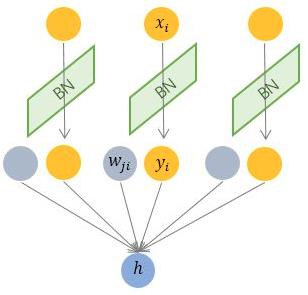
相对上面的 Normalization 通用公式:
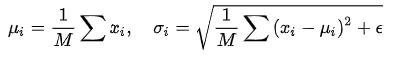
BN 比较适用的场景是:每个 mini-batch 比较大,数据分布比较接近。在进行训练之前,要做好充分的 shuffle,否则效果会差很多。
另外,由于 BN 需要在运行过程中统计每个 mini-batch 的一阶统计量和二阶统计量,因此不适用于 动态的网络结构 和 RNN 网络。不过,也有研究者专门提出了适用于 RNN 的 BN 使用方法,这里先不展开了。
Layer Normalization —— 横向规范化
层规范化就是针对 BN 的上述不足而提出的。与 BN 不同,LN 是一种横向的规范化,如图所示。它综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。
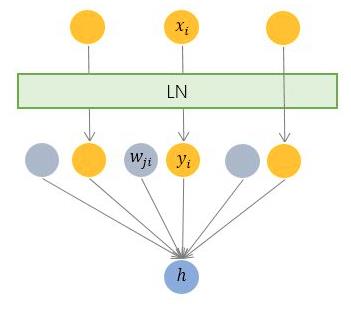
相对上面的 Normalization 通用公式:
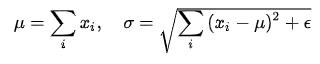
LN 针对单个训练样本进行,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题,可以用于 小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域。此外,LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
但是,BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间,而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
BN和LN的区别
BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。
LayerNorm则是通过对Hidden size这个维度归一化来让某层的分布稳定。
在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。
但是有些场景是不能使用BN的,例如batchsize较小或者在RNN中,这时候可以选择使用LN,LN得到的模型更稳定且起到正则化的作用。LN能应用到小批量和RNN中是因为LN的归一化统计量的计算是和batchsize没有关系的。
Bert、Transformer中为何使用的是LN而很少使用BN
参阅了很多资料,比较能接受2个解释。
第一个解释
我们先把这个问题转化一下,因为Bert和Transformer基本都是应用到了NLP任务上。所以可以这样问:
为何CV数据任务上很少用LN,用BN的比较多,而NLP上应用LN是比较多的?
我们用文本数据句话来说明BN和LN的操作区别。
我是中国人我爱中国
武汉抗疫非常成功0
大家好才是真的好0
人工智能很火000
上面的4条文本数据组成了一个batch的数据,那么BN的操作的时候
就会把4条文本相同位置的字来做归一化处理,例如:我、武、大、人(每个embedding第i个位置一起进行归一化),这里就破坏了一个字内在语义的联系。
而LN则是针对每一句话的每个token embedding做归一化处理。从这个角度看,LN就比较适合NLP任务,也就是bert和Transformer用的比较多。
第一个解释从反面证明BN不适合作归一化,他是对batch个词的某个embedding位置进行归一化,不合理。
第二个解释:batch normalization不具备的两个个功能
1、layer normalization 有助于得到一个球体空间中符合0均值1方差高斯分布的 embedding。NLP数据则是由embedding开始的,这个embedding并不是客观存在的,它是由我们设计的网络学习出来的。通过layer normalization得到的embedding是 以坐标原点为中心,1为标准差,越往外越稀疏的球体空间中,这个正是我们理想的数据分布。
2、layer normalization可以对transformer学习过程中由于多词条embedding累加可能带来的“尺度”问题施加约束,相当于对表达每个词一词多义的空间施加了约束,有效降低模型方差。简单来说,每个词有一片相对独立的小空间,通过在这个小空间中产生一个小的偏移来达到表示一词多义的效果。transformer每一层都做了这件事,也就是在不断调整每个词在空间中的位置,这个调整就可以由layer normalization 来实现,batch normalization是做不到的。[https://blog.csdn.net/HUSTHY/article/details/106665809]
NLP和CV的任务差别
图像数据是自然界客观存在的,像素的组织形式已经包含了“信息”。
图像领域用BN比较多的原因是因为每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被一起规范化。[Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别]
在CV中常常使用BN,它是在NHW维度进行了归一化,而Channel维度的信息原封不动,因为可以认为在CV应用场景中,数据在不同channel中的信息很重要,如果对其进行归一化将会损失不同channel的差异信息。
而NLP中不同batch样本的信息关联性不大,而且由于不同的句子长度不同,强行归一化会损失不同样本间的差异信息,所以就没在batch维度进行归一化,而是选择LN,只考虑的句子内部维度的归一化。 可以认为NLP应用场景中一个样本内部维度间是有关联的,所以在信息归一化时,对样本内部差异信息进行一些损失,反而能降低方差。或者说因为BN对一个Batch中对应位置的分量进行归一化,这就存在一定的问题,因为一个Batch中对应位置的分量不一定有意义,它可能是padding的结果。实际上LSTM训练的时候我们会把一个batch中的序列按照长度降序,长度短的计算完了就不带它继续计算了,相当于batch size缩小了,batch size越小,BN的意义也就越小了。在Transformer中也是一样的,比如我们用绝对位置编码的BERT,把序列长度都padding或者裁剪到512,那么不存在变长问题,也不存在LSTM中batch缩小的问题,那么为什么不用BN而是用LN呢?我的理解是因为虽然序列长度一致了,但是好多embedding是没有意义的,有意义的embedding不应该和它们的分布一致,如果BN会导致有意义的embedding损失信息,所以embedding你就自己和自己归一化吧。
[transformer 为什么使用 layer normalization,而不是其他的归一化方法?]
trans和bert中LN用法[深度学习:transformer模型]
TensorFlow批和层归一化实现
from: -柚子皮-
ref: [详解深度学习中的Normalization,BN/LN/WN]**
以上是关于深度学习:批归一化和层归一化Batch NormalizationLayer Normalization的主要内容,如果未能解决你的问题,请参考以下文章