深度学习之 BN(Batch Normalization)批归一化
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之 BN(Batch Normalization)批归一化相关的知识,希望对你有一定的参考价值。
从字面意思看来Batch Normalization(简称BN)就是对每一批数据进行归一化,确实如此,对于训练中某一个batch的数据x1,x2,…,xn,注意这个数据是可以输入也可以是网络中间的某一层输出。在BN出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理,因为我们现在所用的优化方法大多都是min-batch SGD,所以我们的归一化操作就成为Batch Normalization。
在我目前的水平看来,深度学习的本质上就是刻画问题的内部复杂结构特征,进行任意的非线性变换,简单来说可以看成是学习数据的分布(个人看法,勿喷)。机器学习领域有个很重要的假设:IID独立同分布假设【数据的独立同分布(Independent Identically Distributed)】————假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。如果训练数据与测试数据的分布不同,那么网络的泛化能力就会大大降低。另一方面,如果每批训练数据的分布各不相同,网络就要在每次迭代时都去学习适应不同的分布,那么网络的训练速度就会大大降低,这就是为什么我们需要对输入数据做一个归一化处理。
那BN的作用到底是什么呢?根据刚才提到的机器学习领域的IID独立同分布假设,我们可以发现BN的作用就是在深度神经网络训练过程中使得每一层神经网络的输入均保持相同分布。
归一化可以将我们的数据转换为均值为0,方差为1的服从标准正态分布。
比如可采用Z-score标准化方法:

证明过程:

下面我们以sigmoid激活函数来说明为何我们需要进行批归一化
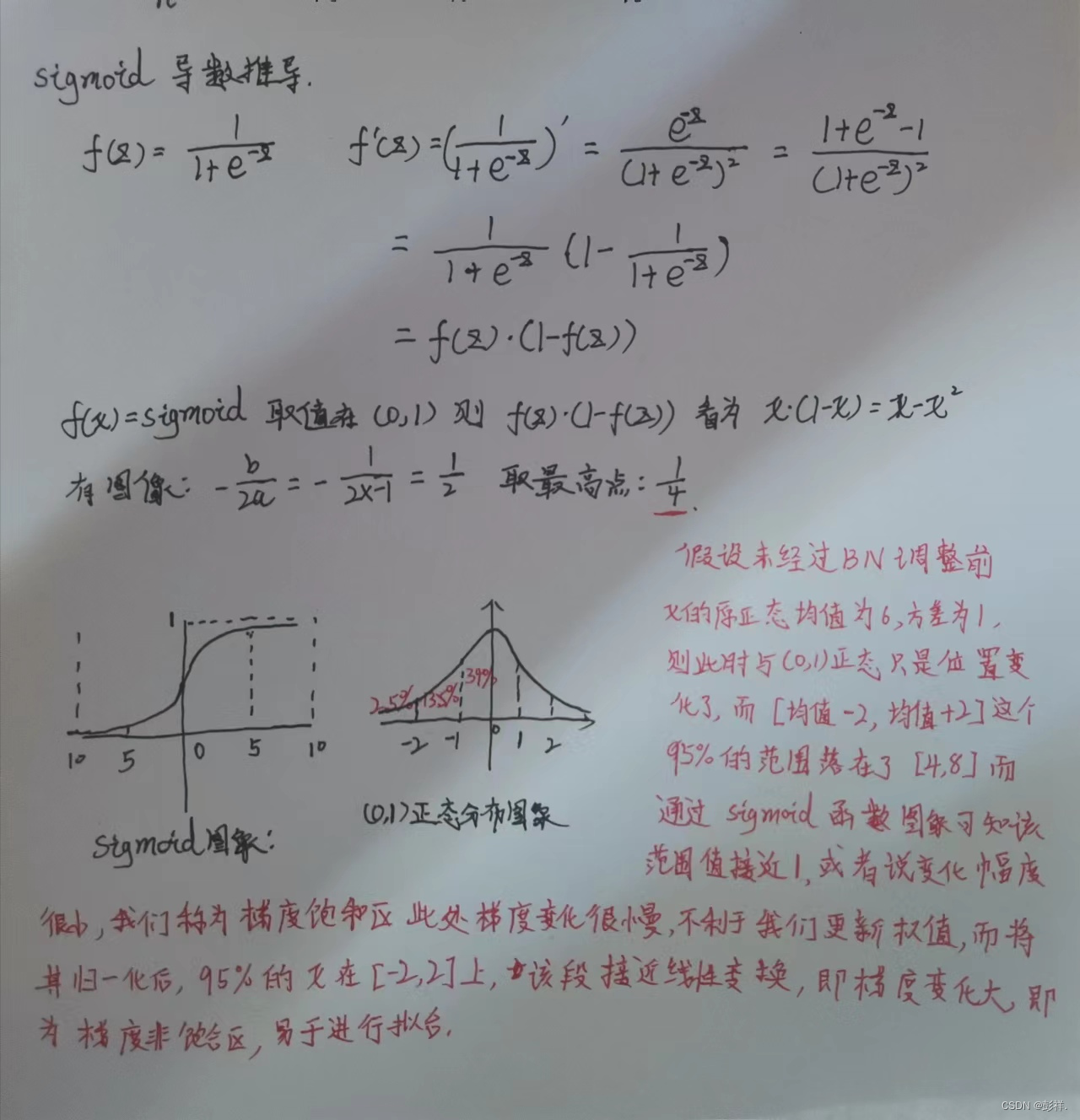
从上面提到的过程中学到了什么呢?BN的作用其实简单来说就是把隐层神经元激活输入从各种奇怪的非【均值为0方差为1的正态分布】拉回到【均值为0方差为1的正态分布】。
但是又出现了一个问题,如果都通过NBN实现归一化的话,不就是把非线性函数替换成线性函数了?这意味着什么呢?这就要说到我们深度学习的学习过程是怎么实现的了,即通过多层非线性实现一个泛化的过程。如果是多层的线性函数其实这个深层就没有任何的意义,因为多层线性网络和一层线性网络是等价的。这意味着网络的表达能力下降了,也就是意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足【均值为0方差为1的正态分布】的x又进行了scale+shift操作。每个神经元增加了两个参数scale和shift,这两个参数通过训练学习到的,关键就是在线性和非线性之间找到一个比较好的平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。最不济的情况,这两个参数可以等效成最开始的状态,也就是训练数据集本来的特征,这只是需要简单的计算就可以实现。
这个时候你可能会觉得真是好简单,不就是在网络中间对数据做一个归一化处理?然而其实并不是那么简单的。如果是仅仅使用上面的归一化公式,对网络某一层A的输出数据做归一化,然后送入网络下一层B,这样是会影响到本层网络A所学习到的特征的,这样会导致网络表达能力下降。比如:网络中间某一层A学习到特征数据本身就分布在S型激活函数的两侧,你强制把它给归一化处理了、标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于搞坏了这一层网络所学习到的特征分布。为了防止这一点,论文提出了一个解决方法,在每个神经元上增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:

BatchNormalization网络层的前向传导过程公式就是:

BN算法在训练时的操作就如我们上面所说,首先提取每次迭代时的每个mini−batch的平均值和方差进行归一化,再通过两个可学习的变量恢复要学习的特征。
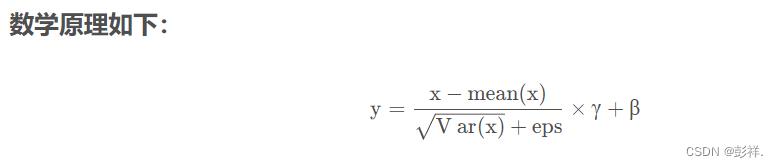

以上是关于深度学习之 BN(Batch Normalization)批归一化的主要内容,如果未能解决你的问题,请参考以下文章