论文泛读83NLP还不够-聊天机器人中用户输入的上下文化
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读83NLP还不够-聊天机器人中用户输入的上下文化相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《NLP is Not enough – Contextualization of User Input in Chatbots》
一、摘要
人工智能聊天机器人近年来在技术改进方面取得了长足进步,并且已经在许多行业中投入使用。基于深层网络的高级自然语言处理技术可以有效地处理用户的请求以执行其功能。随着聊天机器人越来越受欢迎,由于负担过重的系统降低了经济和人力成本,其在医疗保健中的应用成为一个有吸引力的提议。但是,医疗保健机器人需要安全且医学上准确的信息捕获,由于用户文本和语音的变化,深层网络尚无法实现。符号结构方面的知识更适合准确推理,但不能直接处理自然语言处理。因此,在本文中,我们研究了知识和神经表示相结合对聊天机器人安全性,准确性和理解性的影响。
二、结论
观察如何在大规模对话数据上训练大型transformer模型来创建聊天机器人,传统智慧建议我们在咨询对话上训练语言模型来产生心理健康聊天机器人。然而,我们的实验表明,缺乏特定领域的知识会导致对用户在会话反应中的真正询问缺乏理解。当被问及特定领域的问题时,聊天机器人会用通常与问题相关的对话数据来回答,但缺乏直接的答案。在聊天机器人的功能中包含领域知识提高了它在用户输入中识别精神健康信息并将其与领域相关知识联系起来的能力。当用户输入更加自然,而不是与领域相关的查询时,会话数据通常能够成功地对用户输入做出准确而直接的响应。我们的结论是,在聊天机器人中使用带有训练数据的自然语言处理模式识别是不够的;结合领域知识并将其用于用户输入的语境化,提高了聊天机器人生成信息准确和对话能力强的对话的能力。在我们的实验中,用作领域知识的文章作为简单文本(语言模型的唯一输入)被输入到语言模型中,使得每篇文章的结构变得无关紧要(例如,梅奥诊所关于焦虑的文章以“原因”为标题,后面是焦虑的原因列表)。因此,未来的工作围绕着获取结构化领域知识库并将其与深度学习模型相集成。
三、model
通过知识图来进行更新,并会在继续的学习中不断更新知识图。
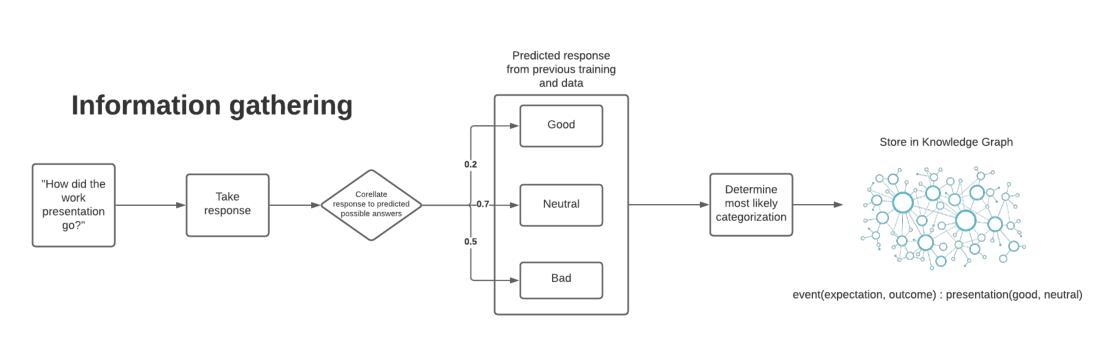
好吧…看了半天发现并没有啥,感觉就是一个特定领域的机器问答,结合了一些伦理知识,在特定的语料库进行学习,用于特定的场景回答。文中还提出了一些可能会误判的情况,比如“你的工作进展的如何?”,“本来可能更糟”。提出的解决是建立知识图谱,如上图所示。
以上是关于论文泛读83NLP还不够-聊天机器人中用户输入的上下文化的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读165量化 NLP 中的可解释性和分析性能-可解释性权衡的算法