ICLR 2021 | Autoregressive Entity Retrieval
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ICLR 2021 | Autoregressive Entity Retrieval相关的知识,希望对你有一定的参考价值。
基本信息
标题:
Autoregressive Entity Retrieval
机构:
阿姆斯特丹大学、Facebook AI Research、巴黎高师、巴黎文理研究大学、法国国家信息与自动化研究所、英国伦敦大学学院
作者:
Nicola De Cao, Gautier Izacard, Sebastian Riedel, Fabio Petroni
论文代码:
https://github.com/facebookresearch/GENRE
论文地址:
https://arxiv.org/abs/2010.00904
https://openreview.net/forum?id=5k8F6UU39V
摘要
实体是表示和聚合知识的中心。比如,维基百科、百度百科等百科全书皆由实体构成。对于给定的query检索出对应实体的能力是知识密集型任务(如实体链接和开放域问答)的基础。实体检索的一种方法常见方法是将其转为multi-class分类任务,设计分类器对每个实体进行原子级打标签。通过 encode 实体元信息(如描述信息)产生对应的稠密实体表征。这类方法有如下缺点:
- 上下文和实体的关系主要通过向量点积获取,可能会丢失两者之间的细粒度交互
- 涉及大型实体集时需要大量内存存储实体的稠密表征
- 训练时必须对负样本中的hard样本进行适当的二次抽样
文章提出一种名为 GENRE (for Generative ENtity REtrieval)的系统,该系统通过生成实体名的方式实现实体检索。GENRE以从左到右,token-by-token 的自回归方式生成实体名称且生成的结果受上下文影响。GENRE能够缓解上述所提到的技术问题:
- (1) 自回归方式使得可以直接捕获上下文和实体名称之间的关系,并能对两者进行有效地交叉编码
- (2) 采用encoder-decoder架构使得参数规模随词汇表大小而非实体量多少而缩放,因此内存占用大大减少
- (3) 可以准确高效计算softmax损失,而无需对负样本进行子采样
在实体消歧、端到端实体链接和文档检索任务的20多个数据集上对 GENRE 进行了实验,结果表明GENRE的有效性。GENRE以很少的内存占用取得SOTA或非常有竞争力的结果。
简而言之,GENRE的核心是通过seq2seq方法生成有意义的实体名称从而实现实体链接,而且效果还很好!
介绍
所谓实体检索是对于一个给定的源文本(也可以是query)从实体集合(其中每个实体都是知识库中的一个条目)中返回与其最相关的实体。当前多数的实体检索系统一般是将实体与唯一的原子标签相关联,并将实体检索任务转为multi-class分类。通过bi-encoder对输入和标签进行编码,再计算两者稠密向量(一般是输入和实体的元信息,比如标题和描述)的点积得到匹配得分,最后从大型实体数据库中检索出目标结果。这类方法存在以下缺点:
- 除非使用昂贵的交叉编码器(cross-encoder)进行重排序,否则点积可能会丢失输入和实体元信息之间的细粒度交互信息
- 存储整个知识库的稠密向量需要很大的内存,特别是在真实的场景中(例如,将约6M的全部Wikipedia页面存储为1024维向量,需要占用约24GB的内存),并且随着新实体的增加,其内存消耗呈线性增长
- 在所有实体上精确计算softmax代价很高,因此当前系统的解决方案是在训练阶段对负样本进行子采样。然而适当地调优出一组hard级别负样本很有挑战性且非常耗时
- 现有系统可能会遇到冷启动问题,因为无法表征尚未收集到足够信息(比如以文本描述或一组与现有实体的关系的形式)的实体
把实体标识符当作分类器中的原子标签来处理,忽略了这样一个事实,即我们经常有明确的、高度结构化的和复合的实体名称。例如,维基百科用独特的标题与文章联系起来(文章这里使用实体名称来指代相应的维基百科文章标题),所以文章标题也可作为实体的唯一标识符。文章标题可能有主题名称或其主题的描述,以及潜在的独特信息可以用来消除歧义。具体示例如Figure 1所示。
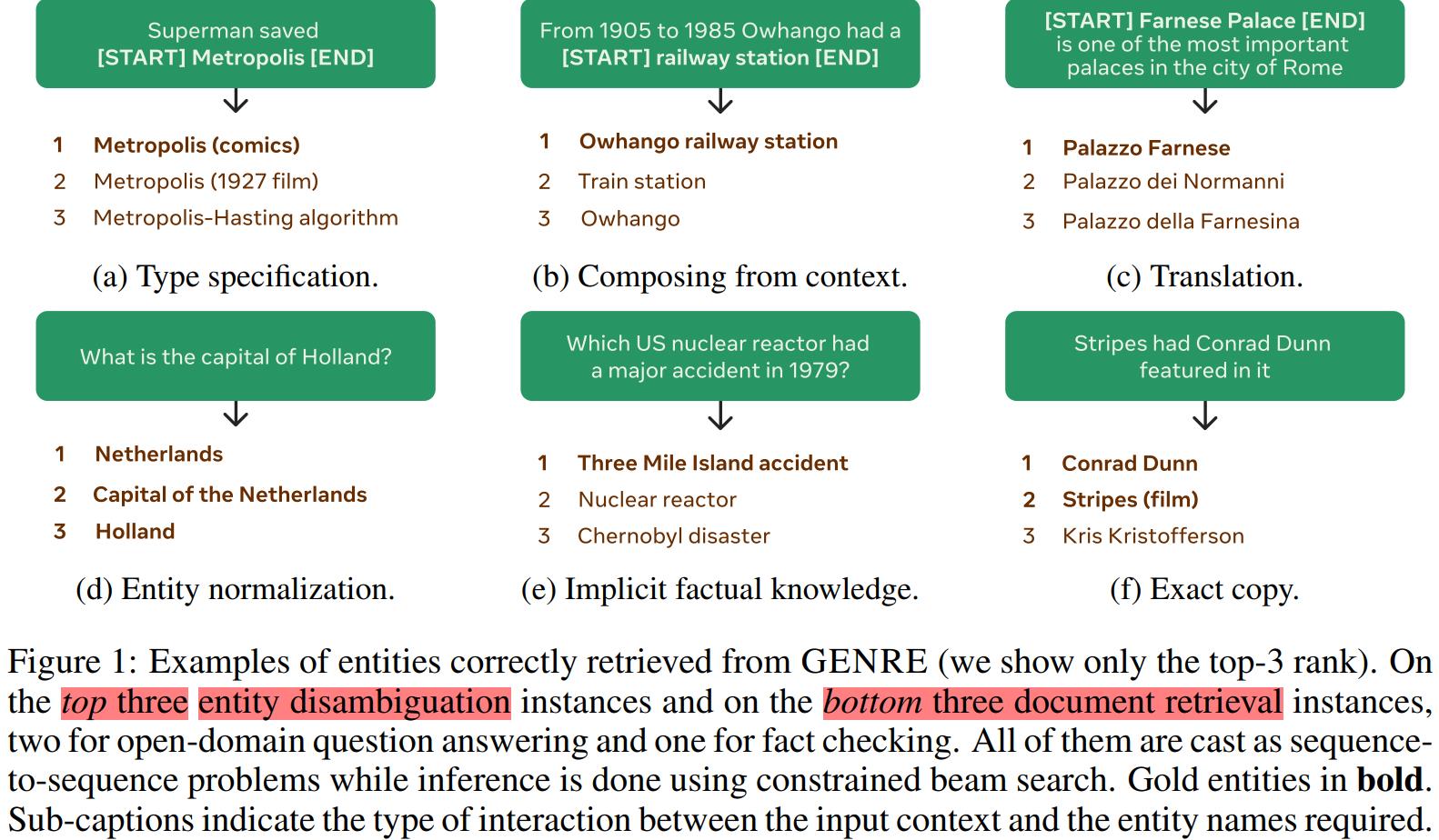
这些实体名称通常以可预测和规则的方式与实体提及(mention)的上下文进行交互。文章总结了6种实体名称与mention的匹配情形:
- 实体名称与mention相同,如Figure 1f
- 实体名称由上下文中的token组成,如Figure 1b
- 实体名称指定mention的类型信息,如Figure 1a
- 实体名称是mention的变换,如Figure 1c
- 实体名称是规范化后的mention,比如mention的别名,如Figure 1d
- 实体名称可能需要存储在模型参数中的事实知识,如Figure 1e
以Figure 1b的例子(属于第2种类型)进行展开说明。该例子中实体名称由context中的tokens组成,此处实体名称是Ōwhango railway station ,由context中的token Ōwhango 与 mention的字符串:railway station组成。综合以上6种情形可以看出,输入可以逐字翻译(或者说转换)成唯一的实体名称,而不是在一大堆候选项中进行分类。这6种类型说明实体名称和带mention的input之间存在着某种形式的映射,因此对于一个mention+context或者输入,是有可能采用生成的方式将其中的mention转换为一个唯一的实体名称的。
文章提出一种名为 GENRE (for Generative ENtity REtrieval)的模型,该模型首创一种利用seq2seq的体系结构和基于上下文的自回归方式生成实体名称的entity retriever(实体检索器)。具体来说,GENRE使用了transformer-based的BART预训练模型并在微调阶段生成实体名。这种体系结构在一定程度上保留了事实知识和语言翻译技能。而这两个属性都是 entity retriever 的理想属性。当然,生成的输出可能并不总是有效的实体名。为此,GENRE 采用了一种受限(或者说是带约束)的解码策略,强制生成的每个名称都在预定义的候选集中。GENRE 有以下优点:
- 自回归的范式使得GENRE能够直接捕获上下文和实体名称之间的关系,并且能有效地交叉编码
- 所需的内存占用比当前系统小几个数量级,因为序列到序列模型的参数与词汇表大小成线性关系,而非实体数量
- 准确高效地计算每个输出token的softmax(即,所有非标准token被认为是负样本),从而避免了对负样本进行下采样
- GENRE无需访问除标题之外的任何关于实体的显式元信息,因此,只需将它们明确的名称添加到候选集合,就可以实现新实体的添加
模型
文章将实体检索任务定义成一个sequence-to-sequence任务,从而生成文本实体标识符(即实体名称)。对于输入,要生成其对应的实体,并且属于知识库中的候选实体集合。利用BART预训练语言模型计算输入与每个候选实体的log-likelihood得分,然后按照分数取top-N个候选实体。以自回归方式计算得分:
score
(
e
∣
x
)
=
p
θ
(
y
∣
x
)
=
∏
i
=
1
N
p
θ
(
y
i
∣
y
<
i
,
x
)
\\operatorname{score}(e \\mid x)=p_{\\theta}(y \\mid x)=\\prod_{i=1}^{N} p_{\\theta}\\left(y_{i} \\mid y_{<i}, x\\right)
score(e∣x)=pθ(y∣x)=i=1∏Npθ(yi∣y<i,x)
其中
e
e
e是实体集合中的实体,
y
y
y是组成实体
e
e
e的N个token,
θ
\\theta
θ是模型的参数,
x
x
x是输入的源文本(比如query)。使用标准的seq2seq目标函数(即最大化输出序列的likelihood)训练 GENRE。 具体来说,文章使用了神经机器翻译的典型目标函数,即最大
log
p
θ
(
y
∣
x
)
\\log p_{\\theta}(y \\mid x)
logpθ(y∣x)的模型参数θ。由于损失函数通过因式分解可以精确计算,因此不需要负采样来进行近似。简而言之,GENRE通过fine-tune BART模型来生成实体名称。
受限 Beam Search
GENRE 在decode阶段并没有在Wikipedia的所有实体(约6M)进行搜索,而是采用了beam search策略。具体来说,beam search 中的top-k设置为10,所以只从top10个实体中进行选择。传统的beam search解码允许每个位置可以是任意的token,如此无法保证生成的实体一定属于知识库。为确保生成的实体在知识库中,文章提出一种受限的Beam Search,从而强制只解码出有效的实体名称。在解码过程中,Beam Search 只考虑提前一步,所以解码时只能以前一步为条件控制下一个token的生成。因此,文章通过前缀树定义受限条件,树上的每一个节点表示词表中的一个token,节点的孩子表示所有可能的后续tokens。下图是前缀树的一个例子:
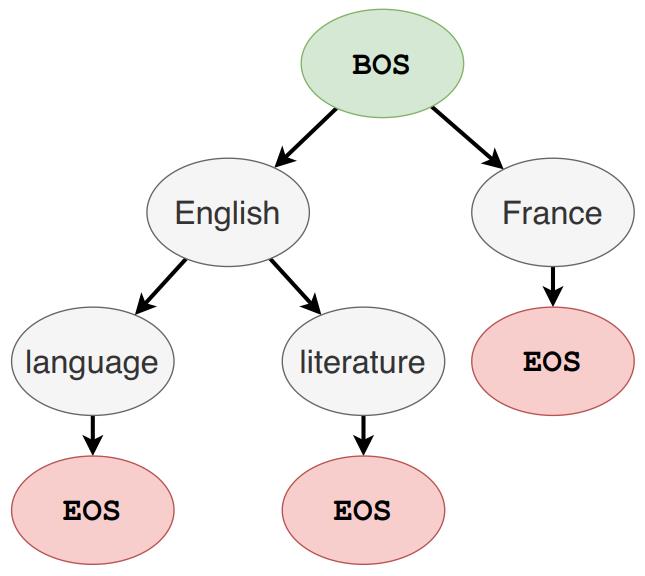
从上图可以看出Enligh这个token的后续tokens是language和literature,则解码时Enligh的下一个token只能从language和literature中选择。
自回归的端到端实体链接
在实体消歧和页面级的文档检索任务上,直接将数据集输入到语言模型即可,但是生成式的端到端实体链接任务相对复杂。所谓的端到端实体链接是给定一个文档,系统需要检测其中的entity mentions,并将mentions链接到知识库中相应的实体。比如输入是 In 1503, Leonardo began painting the Mona Lisa, 则需要模型检测出其中的mention是 Leonardo 和 Mona Lisa,然后将其链接到知识库中的实体 Leonardo da Vinci 和 Mona Lisa 。为此,GENRE 进一步扩展了其自回归框架使其能够进行实体链接,这就要求能够同时检测和链接实体。
由于mention的文本形式千变万化(free-form),很难预定义所有mentions的前缀树,即使做到搜索空间也会非常大。因此文章采用动态解码的方案。具体示例如Figure 2所示。

每个生成步骤的 decoder 可能生成3种结果:mention span 、mention 链接的实体和输入源。在生成 mention/实体 阶段之外,decoder 有两个可能:(1)从输入源直接复制下一个token (2)生成mention 的起始token(即’[’),这使得decoder进入mention生成阶段。在生成 mention 时,decoder 也有2种可能:(1)从输入源中拷贝生成mention的下一个token (2)生成 mention的终止token(即’]’),这使得 decoder 进入实体链接阶段。生成实体时,decoder使用之前所说的前缀树以确保输出一个符合要求的实体。最后生成")"结束实体生成。
实验结果
文章在实体消歧、端到端实体链接和文档检索任务的20多个数据集上对 GENRE 进行了实验,实验结果表明 GENRE 确实高效可行。GENRE 非常能打,以很少的内存即可取得SOTA或非常有竞争力的结果。
实体消歧
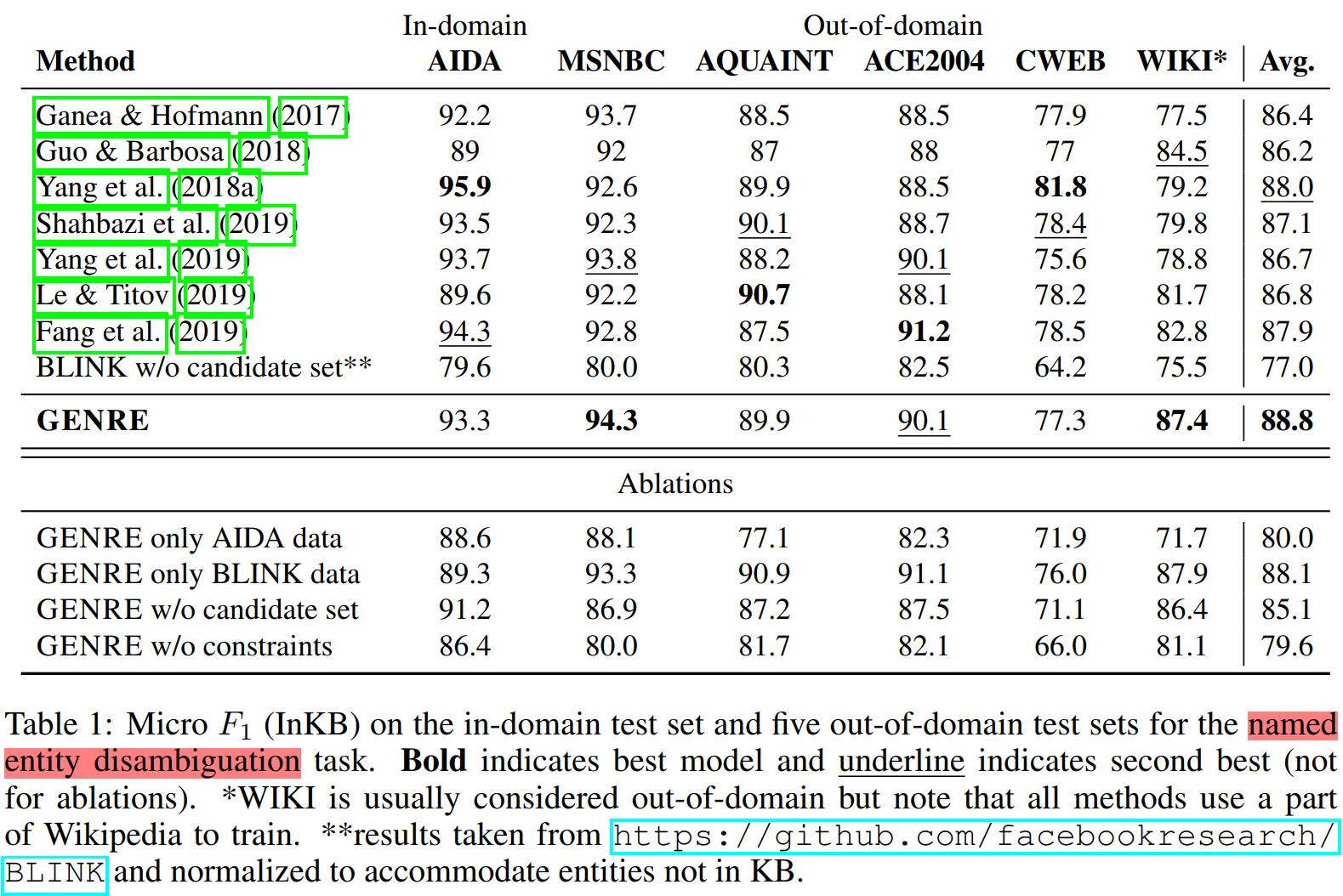
GENRE 在在6个实体消歧数据集上的性能提升整体较小,Micro F1只比之前的SOTA高出了0.8。具体如 Table 1所示。由于对这些实体消歧基准数据的研究已有十多年,整体刷榜差不多到头了,即使是3年前的模型也有较高的得分,所以,想要进一步大幅提升比较困难~
实体链接
GENRE 在8个实体链接数据集上的Micro F1比之前的SOTA高出1.8。具体如 Table 2所示。
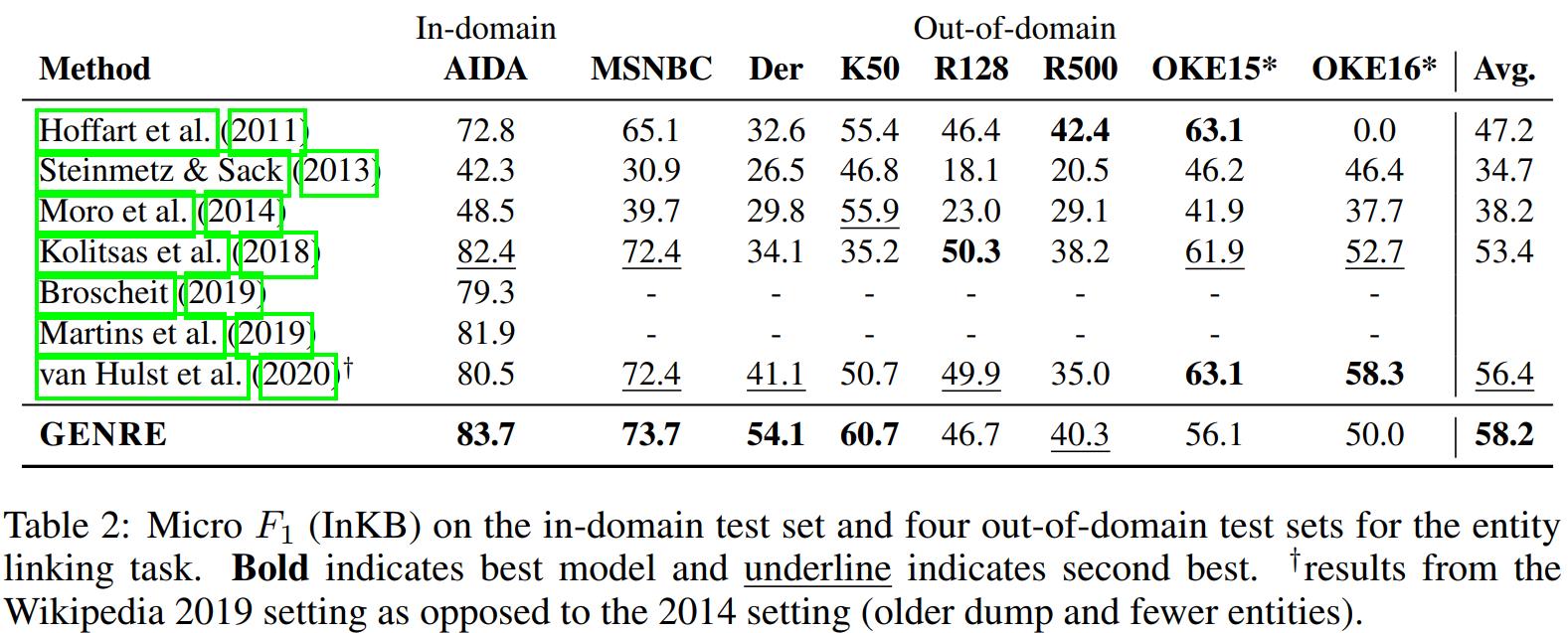
从中可以看出 GENRE 在Der和K50这两个数据集的提升最大,在 Micro F1 上分别提升13和4.7。
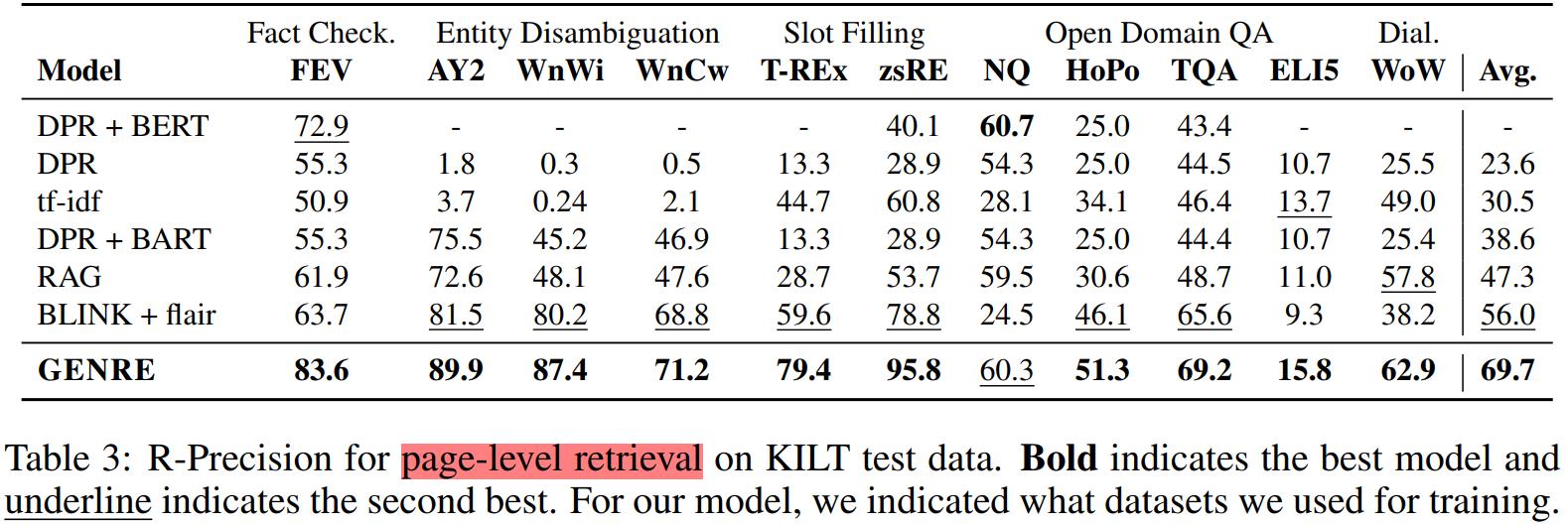
页面级文档检索
在页面级文档检索任务上,GENRE所展示出来的优越性非常显著。GENRE 在所有数据集上几乎都取得了SOTA,整体的R-Precision比之前的SOTA模型高出13.7。具体如 Table 3所示。
节省内存
文章对比了DPR 、RAG 、BLINK 和 GENRE在文档检索任务上的内存占用,具体如 Table 4所示。GENRE使用一个数量级较小的参数(数百万而不是数十亿)来存储实体索引,因为它只需要使用实体名称的前缀树,而不是为每个实体构建一个稠密向量。
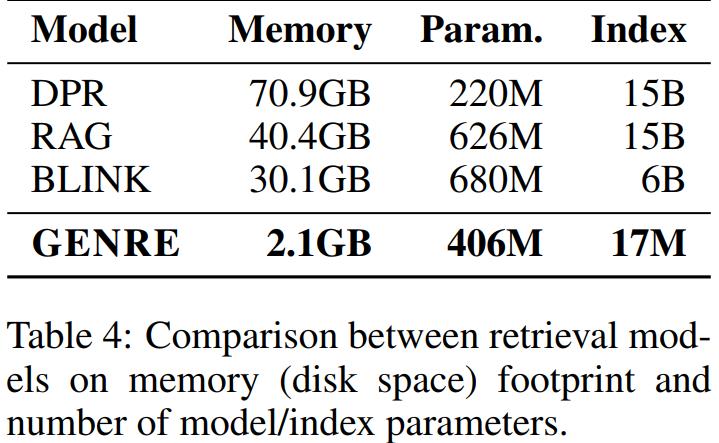
从以上表格可以看出 GENRE 的内存占用比 BLINK 少14倍,比 DPR 省了34倍。
实体名称比实体ID更好
文章在实体消歧任务上对比了生成实体名称和生成实体ID的区别。具体如Table 5所示。
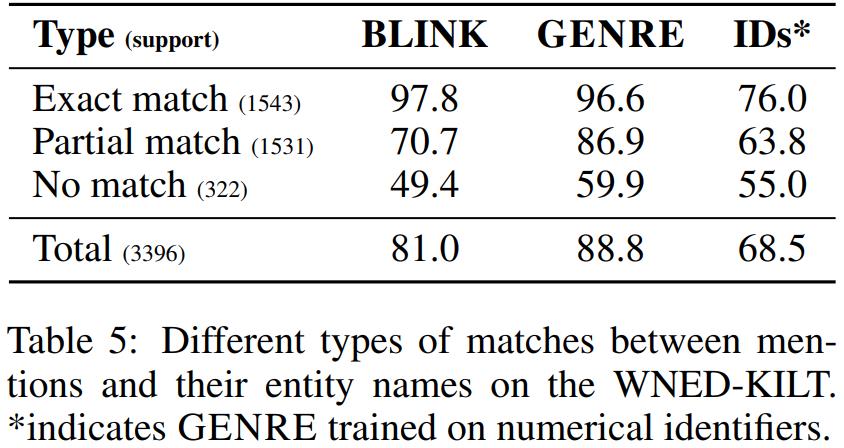
上图对比了3种mention和实体名称的匹配类型在不同模型上的效果,可以看出:
- 当mention和实体名称完全匹配时,GENRE取得了非常高的Micro F1,而使用IDs则降低了20.6。
- 当部分匹配时,GENRE依旧碾压IDs,说明实体名称确实是提供了有意义的信息。这种情况下实体名称的优势是,实体名称可以与mention的cotnext进行更多的细粒度交互,以帮助选择正确的候选实体。
- 当完全不匹配时,使用实体名称和IDs的区别相对较小,这说明:1)GENRE依赖于文本,2)即使是生成数值信息,模型也是有一定的实体消歧能力。
此外,文中还进一步讨论了 GENRE 对尾部实体的处理,实验结果表明GENRE确实可以有效处理链接罕见的实体。
总结
文章提出一种名为GENRE的方法进行实体检索,该方法以自回归的方式生成实体名称。GENRE有以下优点:
- 输入和实体名称之间的细粒度交互。实体名称(文章title)提供更详细的实体描述,使实体与mention及其context之间的编码可以有更细粒度的交互。换句话说,引入文章title来替代实体的ID,因为这里实体名称可以提供更多更多细粒度信息。
- 减少内存占用。在解码阶段使用前缀树来做beam search,使得内存占用仅与词表大小有关,而和实体数量无关,从而减少了存储空间。
- 避免负采样。因为准确的softmax loss可以直接计算得到,所有的非标准的token都被当做负样本,所以无需负采样。
简而言之,GENRE开创以seq2seq的生成方式进行实体检索之先河,且结果取得SOTA或近似SOTA。
以上是关于ICLR 2021 | Autoregressive Entity Retrieval的主要内容,如果未能解决你的问题,请参考以下文章