文本匹配——ICLR 2021CT
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本匹配——ICLR 2021CT相关的知识,希望对你有一定的参考价值。
1. 介绍
论文《SEMANTIC RE-TUNING WITH CONTRASTIVE TENSION》地址:https://openreview.net/pdf?id=Ov_sMNau-PF
之前讲到的Sentence-BERT是用有监督的方式进行句子向量的匹配等任务。那当没有标注数据的时候,如何训练出更好的句子向量呢?
本文作者提出了“对比张力”(CONTRASTIVE TENSION)的对比学习方案——CT:
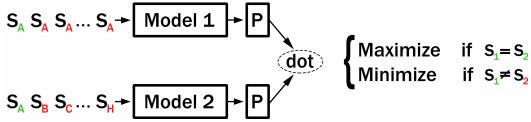
如上图所示,在训练期间,CT 构建了两个独立的编码器(“Model1”和“Model2”),它们共享初始参数以对一对句子进行编码。如果 Model1 和 Model2 编码同一个句子,那么这两个句子嵌入的点积应该变大。如果 Model1 和 Model2 编码不同的句子,那么它们的点积应该变小。原始 CT 论文使用包含多个小批量的批次。对于 K=7 的例子,每个 mini-batch 由句子对
(
S
A
,
S
A
)
,
(
S
A
,
S
B
)
,
(
S
A
,
S
C
)
,
.
.
.
,
(
S
A
,
S
H
)
(S_A, S_A), (S_A, S_B), (S_A, S_C), ..., (S_A, S_H)
(SA,SA),(SA,SB),(SA,SC),...,(SA,SH) 组成,对应的标签是 1, 0, 0, …, 0. 换句话说,一对相同的句子被视为正例,而另一对不同的句子被视为反例(即1个正+ K个负对)。训练目标是生成的相似度分数和标签之间的二元交叉熵:

经过训练后,Model2将用于推理,通常具有更好的性能。
2. 实验效果
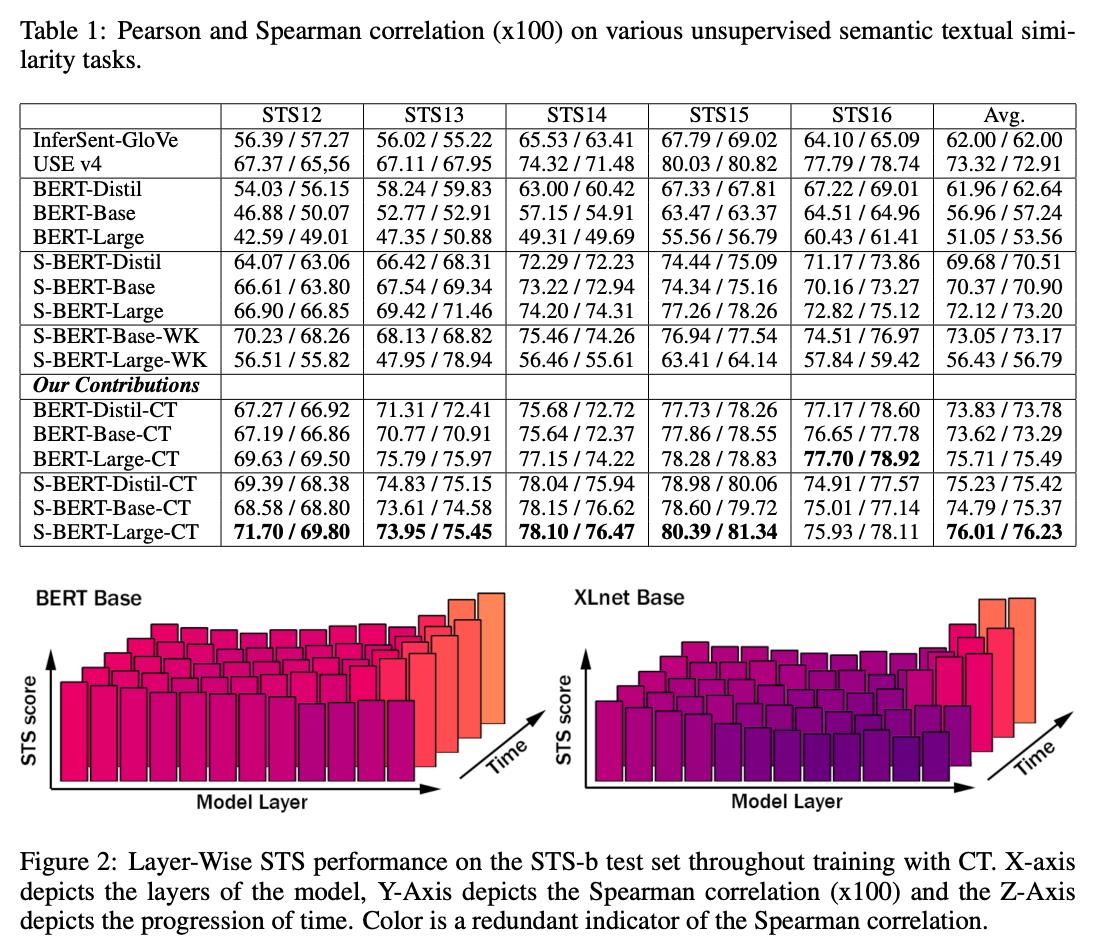
3. 实现
sentence_transformers已经把CT已经封装成pip包,完整的训练流程例子可以参考《Sentence-BERT》。我们在此基础上只用修改DataLoader和Loss就能轻松的训练CT:
from sentence_transformers import SentenceTransformer, InputExample
from sentence_transformers import models, losses
# ....
# 对于 ContrastiveTension,我们需要一个特殊的数据加载器来构建具有所需属性的批次
train_dataloader = losses.ContrastiveTensionDataLoader(train_sentences, batch_size=batch_size, pos_neg_ratio=pos_neg_ratio)
# loss, 我们使用 losses.ContrastiveTensionLoss
train_loss = losses.ContrastiveTensionLoss(model)
# ……
# 训练模型
model.fit(train_objectives=[(train_dataloader, train_loss)],
epochs=num_epochs,
warmup_steps=warmup_steps,
optimizer_params='lr': 5e-5,
checkpoint_path=model_output_path,
show_progress_bar=True,
use_amp=False
)
4. 负采样的改进
sentence_transformers中还是实现了一个CT使用批量负采样的改进版本:模型 1 和模型 2 都编码相同的句子集。最大化匹配索引的分数(即 M o d e l 1 ( S i ) Model1(S_i) Model1(Si)和 M o d e l 2 ( S i ) Model2(S_i) Model2(Si)),同时最小化不同索引的分数(即 M o d e l 1 ( S i ) Model1(S_i) Model1(Si)和 M o d e l 2 ( S j ) Model2(S_j) Model2(Sj) for i != j)。使用批量负采样提供比原作者提出的原始损失函数有更强的训练信号。
实验效果:

代码实现中就不用改变DataLoader,只用修改Loss就能轻松的训练:
from sentence_transformers import SentenceTransformer, InputExample
from sentence_transformers import models, losses
from torch.utils.data import DataLoader
# ……
train_loss = losses.ContrastiveTensionLossInBatchNegatives(model)
# ……
# 训练模型
model.fit(train_objectives=[(train_dataloader, train_loss)],
epochs=num_epochs,
warmup_steps=warmup_steps,
optimizer_params='lr': 5e-5,
checkpoint_path=model_output_path,
show_progress_bar=True,
use_amp=False
)
以上是关于文本匹配——ICLR 2021CT的主要内容,如果未能解决你的问题,请参考以下文章