爬虫学习 ----- 第二章 爬取静态网站 ---------- 04 带着cookie去爬取东西
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习 ----- 第二章 爬取静态网站 ---------- 04 带着cookie去爬取东西相关的知识,希望对你有一定的参考价值。
学习自:https://www.bilibili.com/video/BV1b64y117X6?p=43&spm_id_from=pageDriver
1. 带着cookie去爬取东西
任务:
-
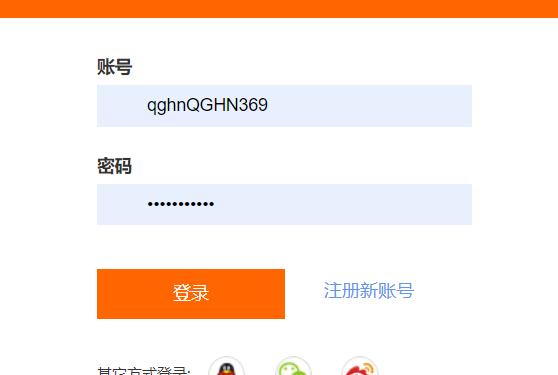
登陆->得到cookie
-
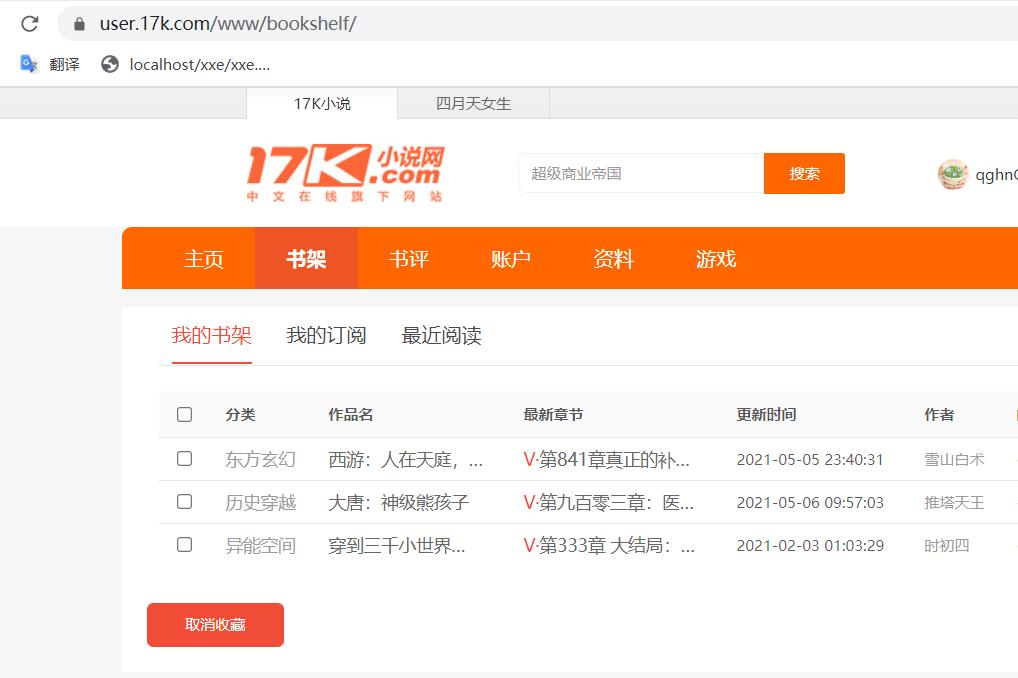
带着cookie 去请求到书架的 url ->爬取书架上的内容。
-
将 上面的两个操作 连接起来,
-
可以用session 进行请求 ,session,可以认为是 一连串的请求。这个过程中 的cookie 是 不会丢失的。
1. 登陆:
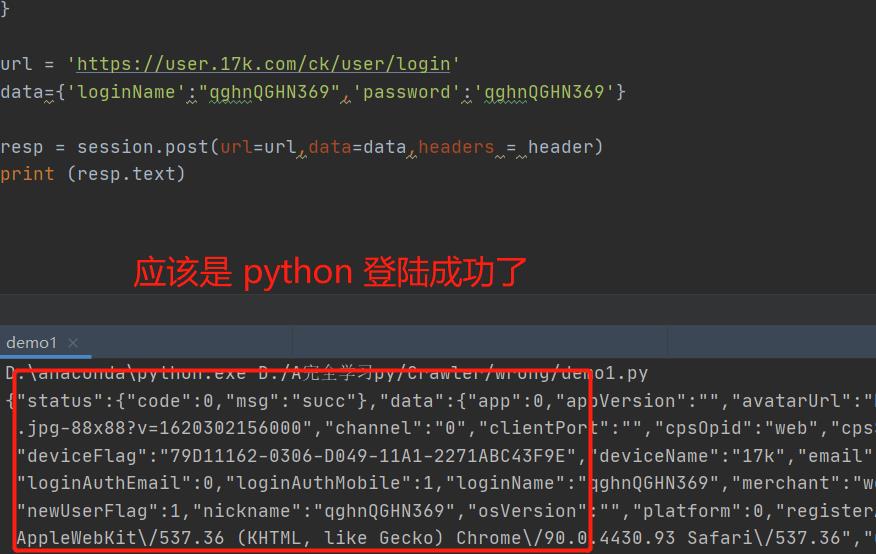
import re
import requests
# 开启会话
session = requests.session()
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
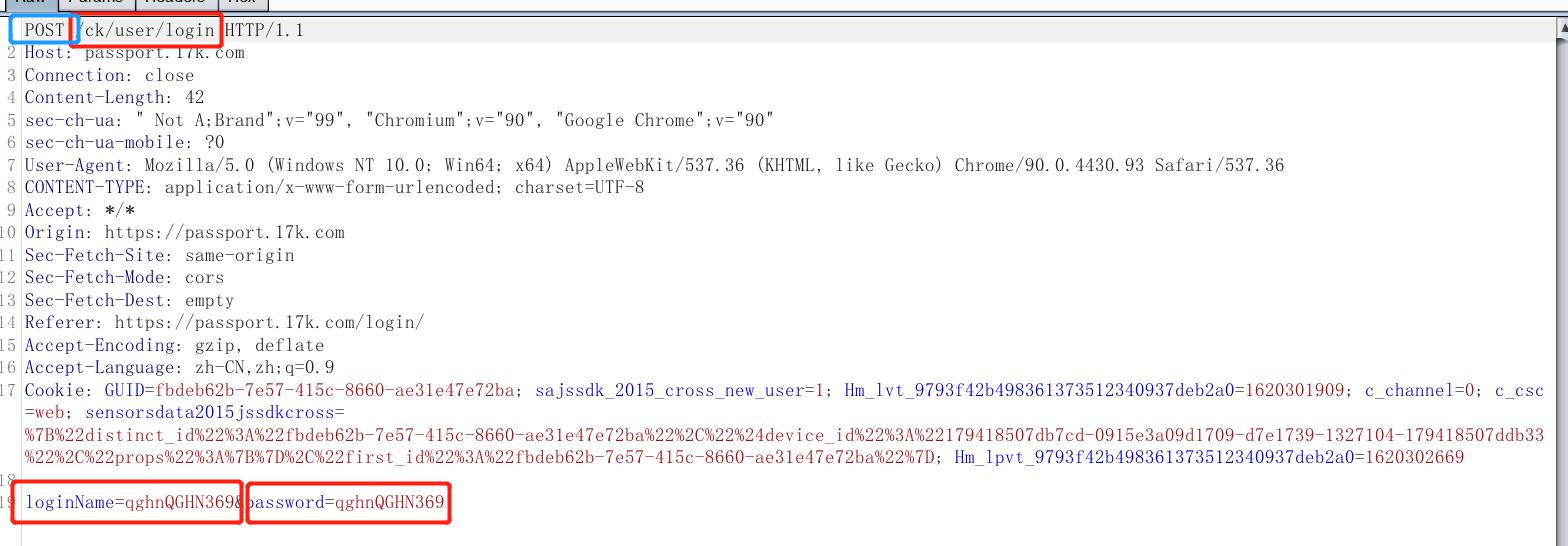
url = 'https://user.17k.com/ck/user/login'
data={'loginName':"qghnQGHN369",'password':'qghnQGHN369'}
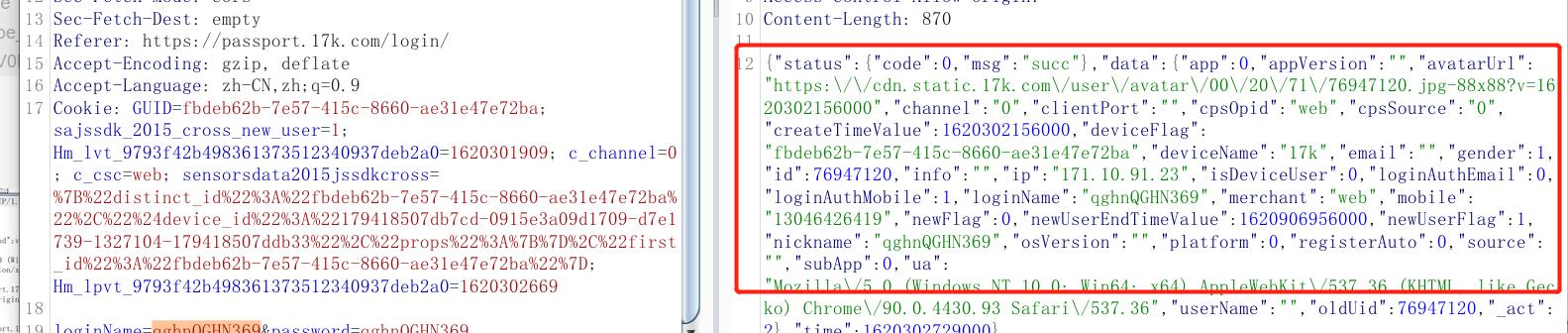
resp = session.post(url=url,data=data,headers = header)
print (resp.text)
1. 拿cookie呀,
不用拿cookie的,我们是session访问的,期间的cookie是不变的。
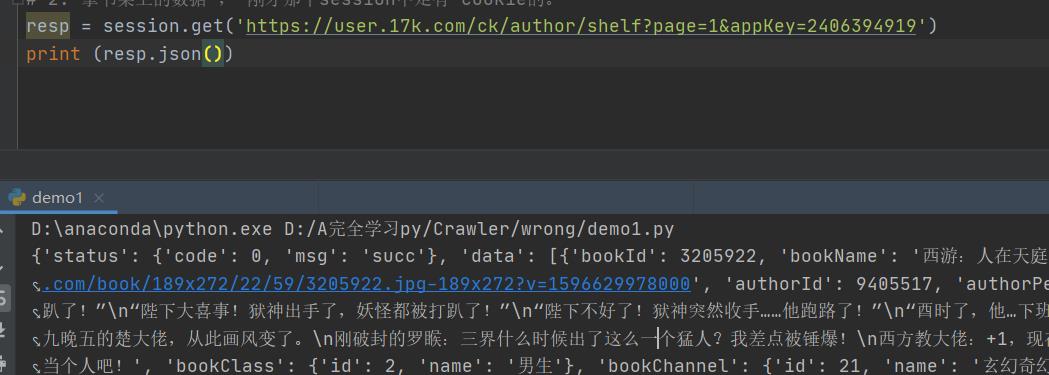
2. 拿书架上的数据。
那就点击书架,然后看包,看网页的数据,看看是从哪一个包里面来的。
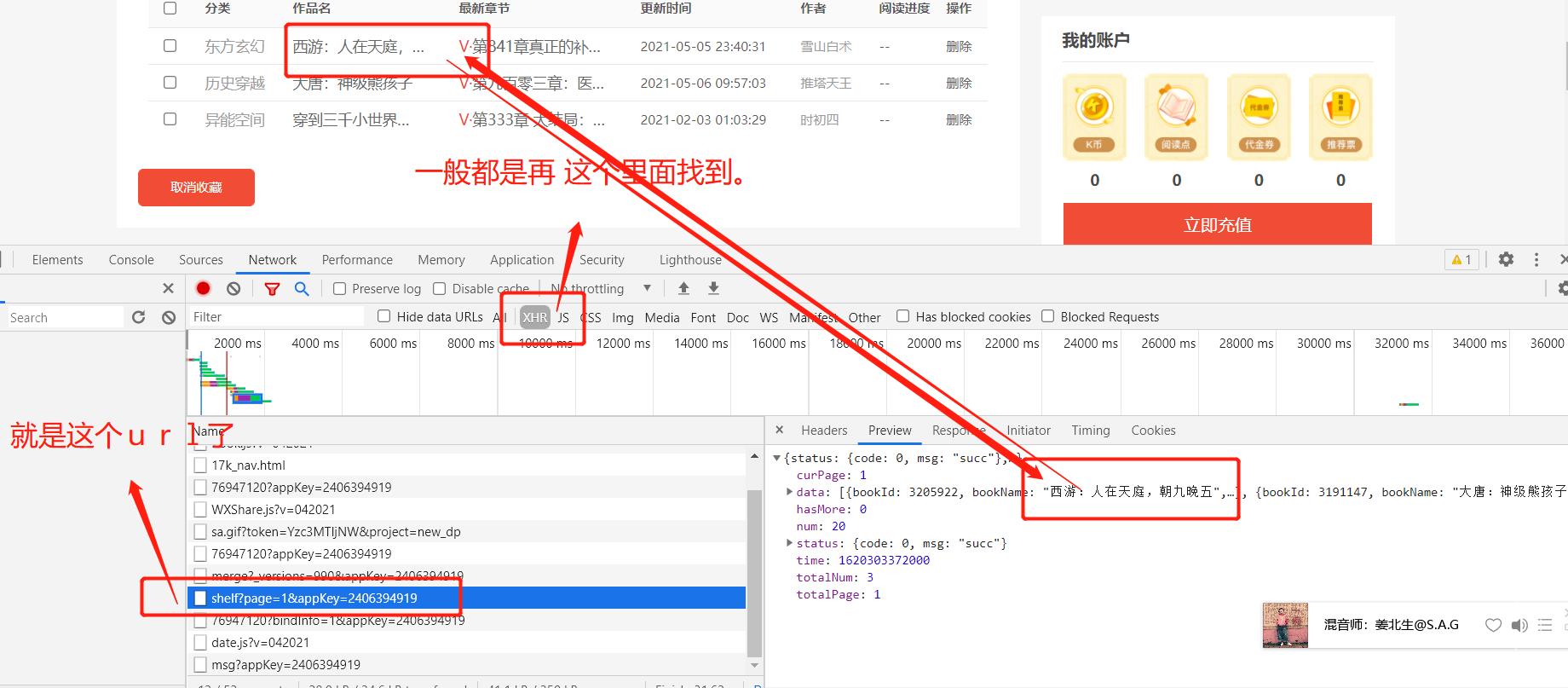
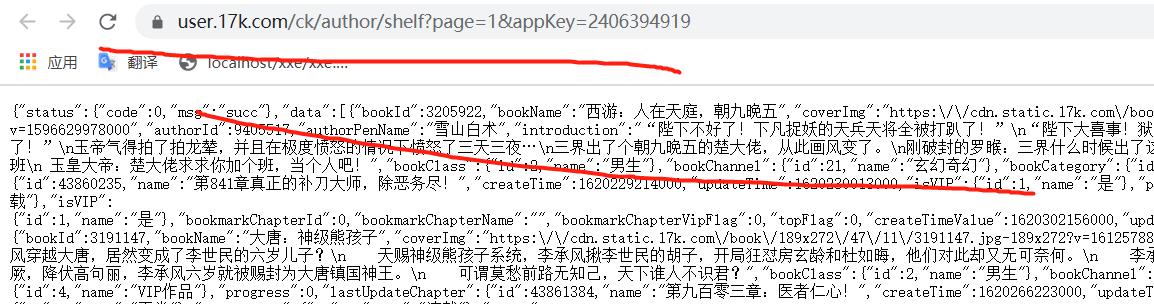
一个吊样,,,
总代码:
# -*- coding: utf-8 -*-
# @Time:2021/5/4 23:15
# @Author: adam
# @File:demo1.py
import re
import requests
# 开启会话
session = requests.session()
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url = 'https://user.17k.com/ck/user/login'
data={'loginName':"qghnQGHN369",'password':'qghnQGHN369'}
resp = session.post(url=url,data=data,headers = header)
# print (resp.text)
# print (resp.cookies) # 看cookie
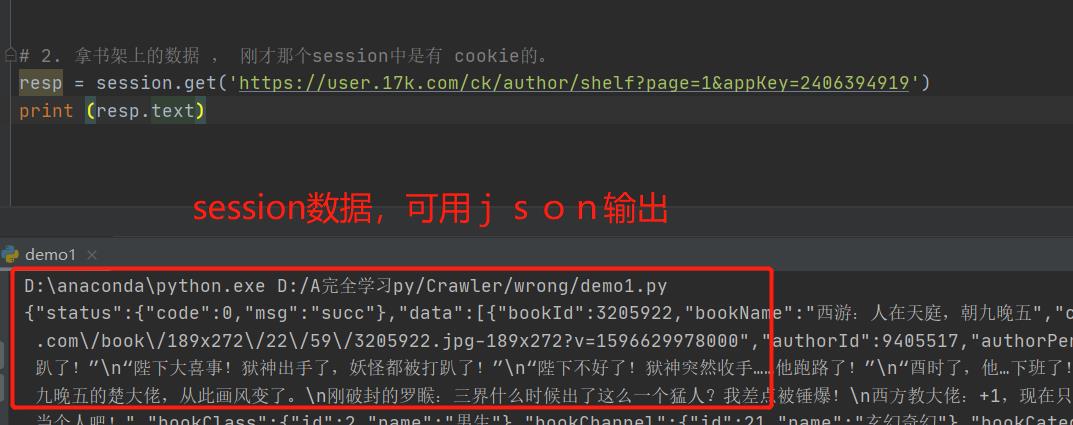
# 2. 拿书架上的数据 , 刚才那个session中是有 cookie的。
resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
content = resp.text
# print (content)
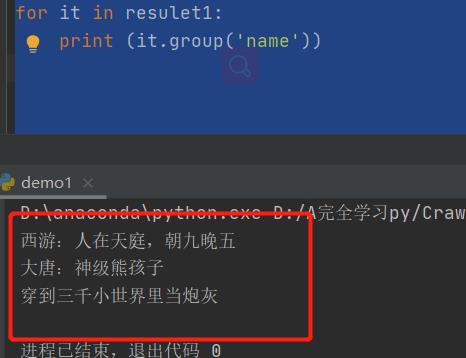
obj1 = re.compile(r'bookName":"(?P<name>.*?)"',re.S)
resulet1 = obj1.finditer(content)
for it in resulet1:
print (it.group('name'))
然后连接数据库,放到数据库里就好了。
以上是关于爬虫学习 ----- 第二章 爬取静态网站 ---------- 04 带着cookie去爬取东西的主要内容,如果未能解决你的问题,请参考以下文章
爬虫学习 ----- 第二章 爬取静态网站 ---------- 05. 防盗链,爬取梨视频之 referer XHR
爬虫学习 ----- 第二章 爬取静态网站 ---------- 01 . re 模块学习 ---- python的re库