爬虫学习 ----- 第二章 爬取静态网站 ---------- 05. 防盗链,爬取梨视频之 referer XHR
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习 ----- 第二章 爬取静态网站 ---------- 05. 防盗链,爬取梨视频之 referer XHR相关的知识,希望对你有一定的参考价值。
目录:

学习自:https://www.bilibili.com/video/BV1b64y117X6?p=43&spm_id_from=pageDriver
总述一下吧:
就是我们正常的页面,然后F12,看到的源码,是网页加载完毕之后的所有元素的源码, 但是我们 爬取和查看页面源代码看到的却和F12不一样,我们这时候查看到的就是 这一个页面的源码,
但是可能我们想要爬取的东西没有直接在 这个页面中,而是后期js或者Ajax等加载完的。然后我们要
1.好复杂啊,,,,吐了。。
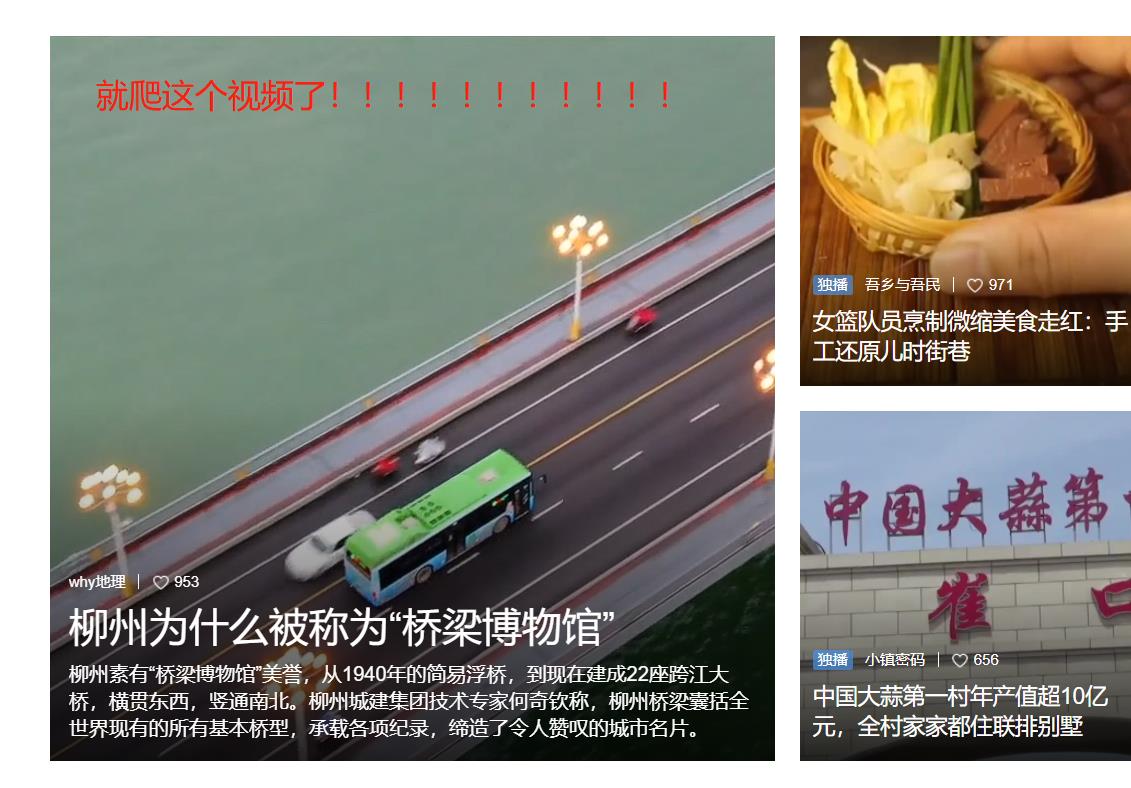
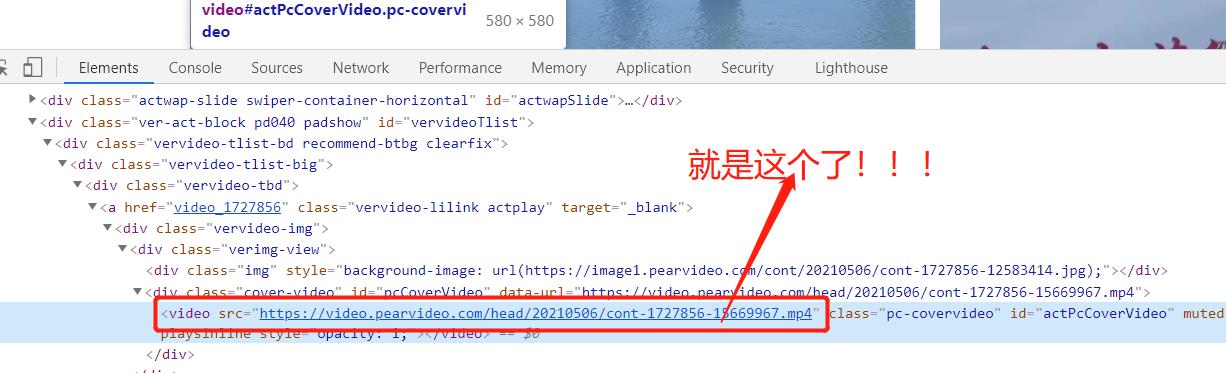
但是 这个在页面源代码中看不到。。。这就很恶心了,,就是反爬机制

那就判断,,既然不再 这个页面的源代码里面,那么就是 后期的js脚本,加载之后又放到了这里面了。
进入我们要爬取的视频的连接
然后点击进入那个视频连接
???这里有个疑问,只靠爬虫不能够找到这个进入的连接口吗??
可以的。把后面的爬完之后在回来整这个。
进入这个单独的一个视频的网站,
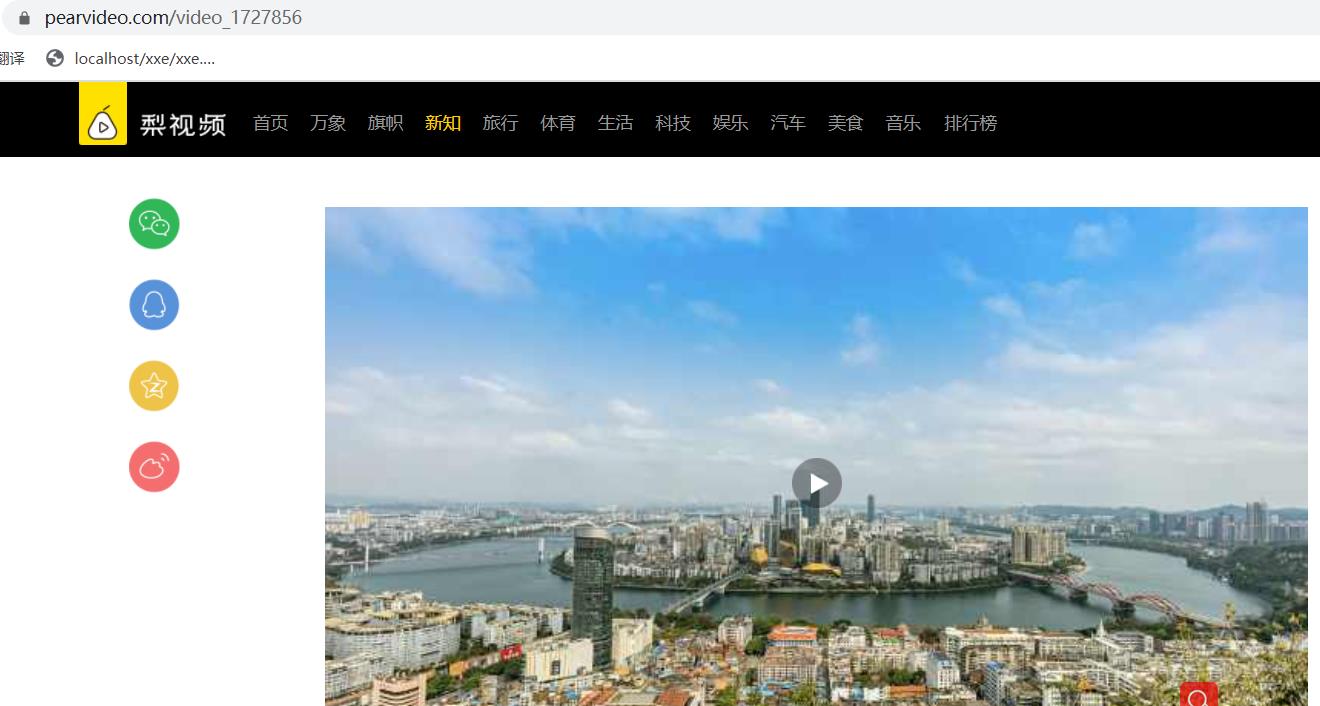
刷新页面,并选择 XHR。
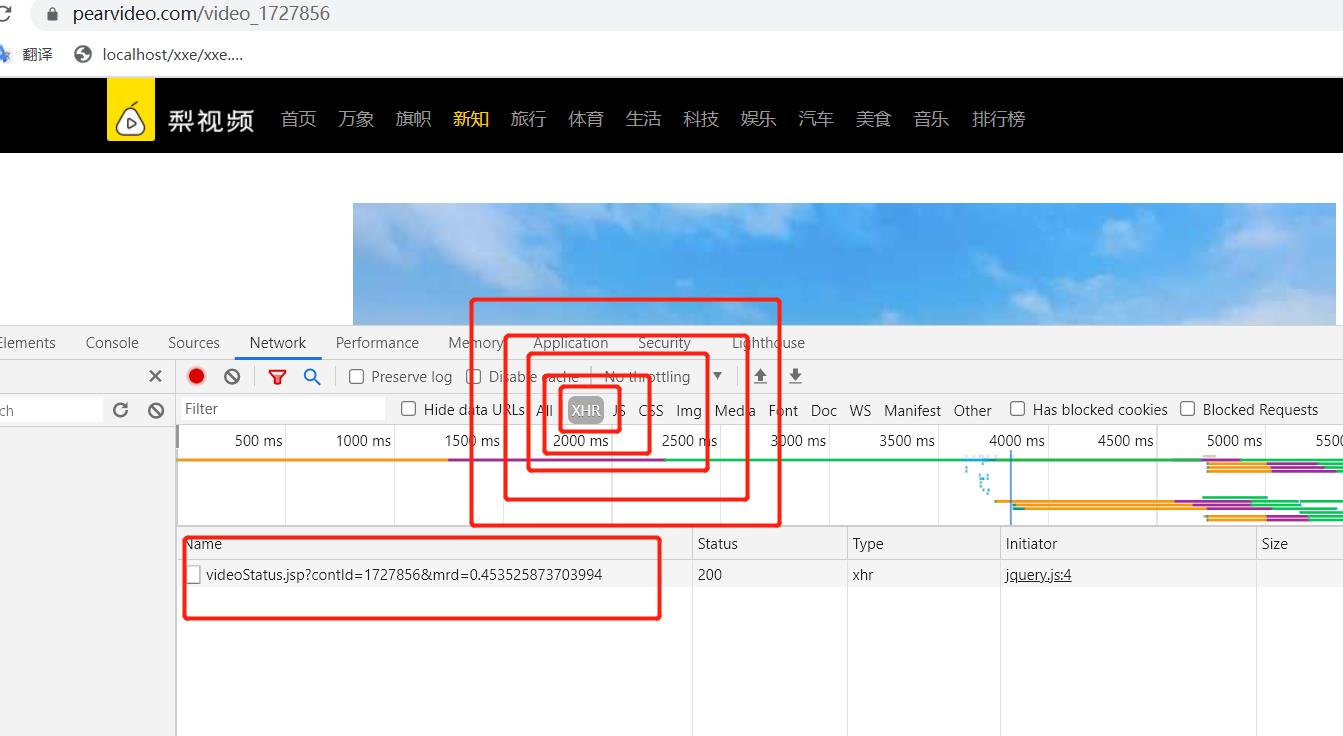
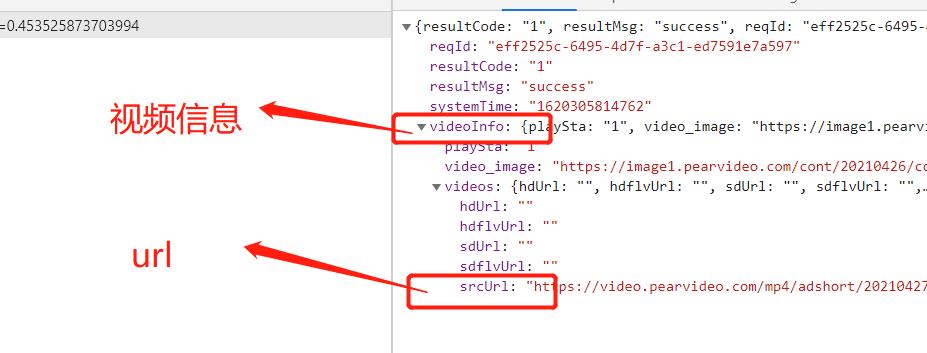
!!!就找到了啊!!!,,但是不对的,,,我赋值下来这个url之后, 访问,是不对的。
1. 发现url不对啊,,404访问不到啊。。那就比较一下两个url,看看是哪里的问题。
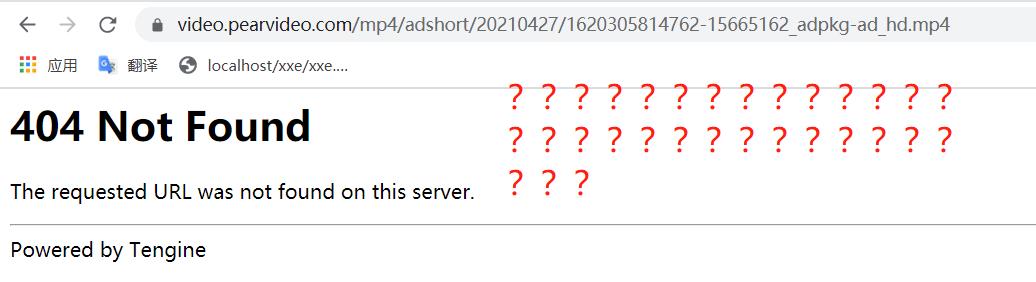
那我们看看url之间的区别。
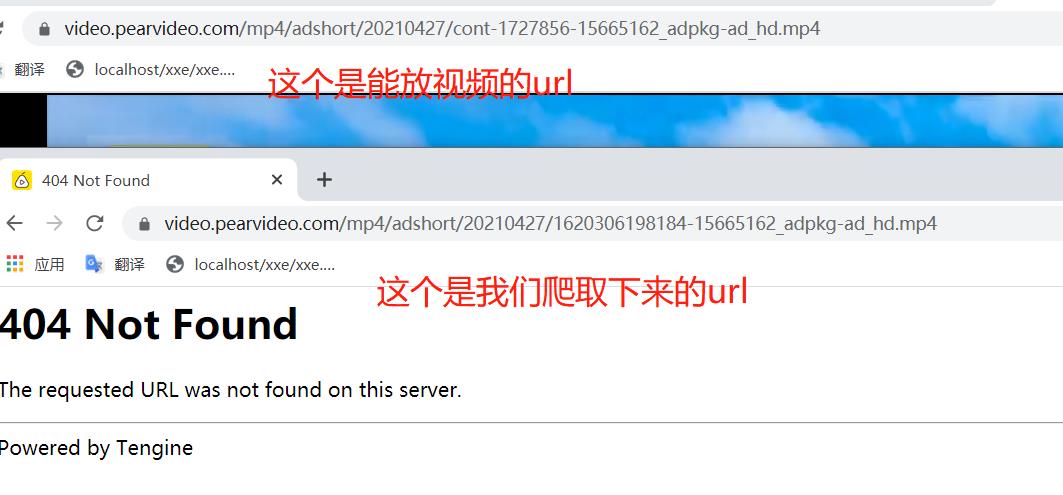
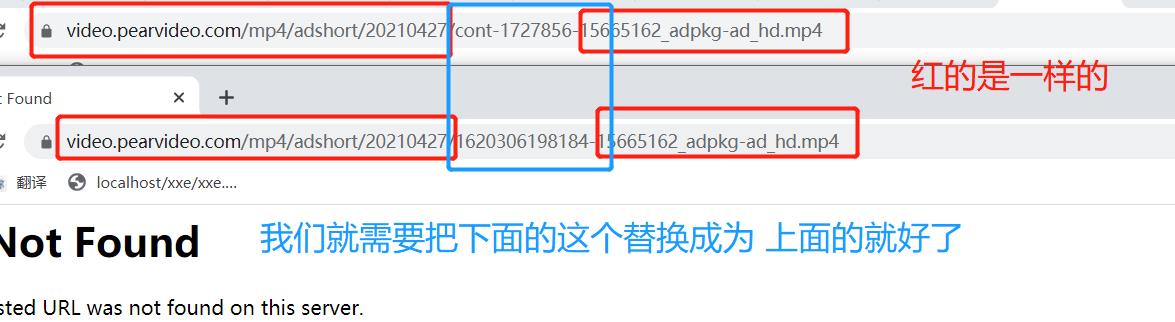
那么我们从网站的角度来思考是做了什么操作。
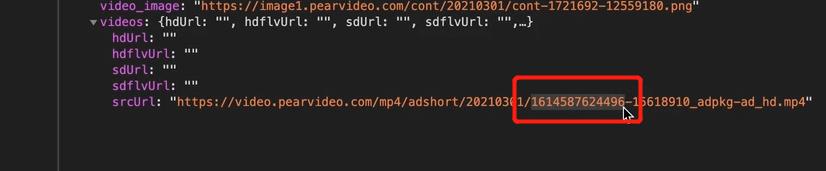
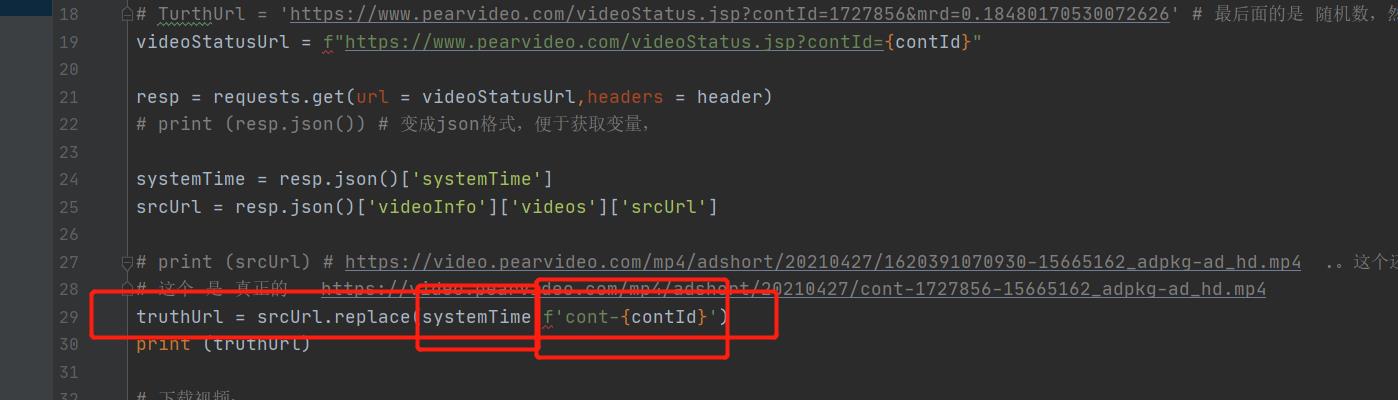
网页从这个XHR包中拿到srcurl之后,然后将中间这串数字替换成立 cont- ***之类的。然后我们就找一下在哪里。
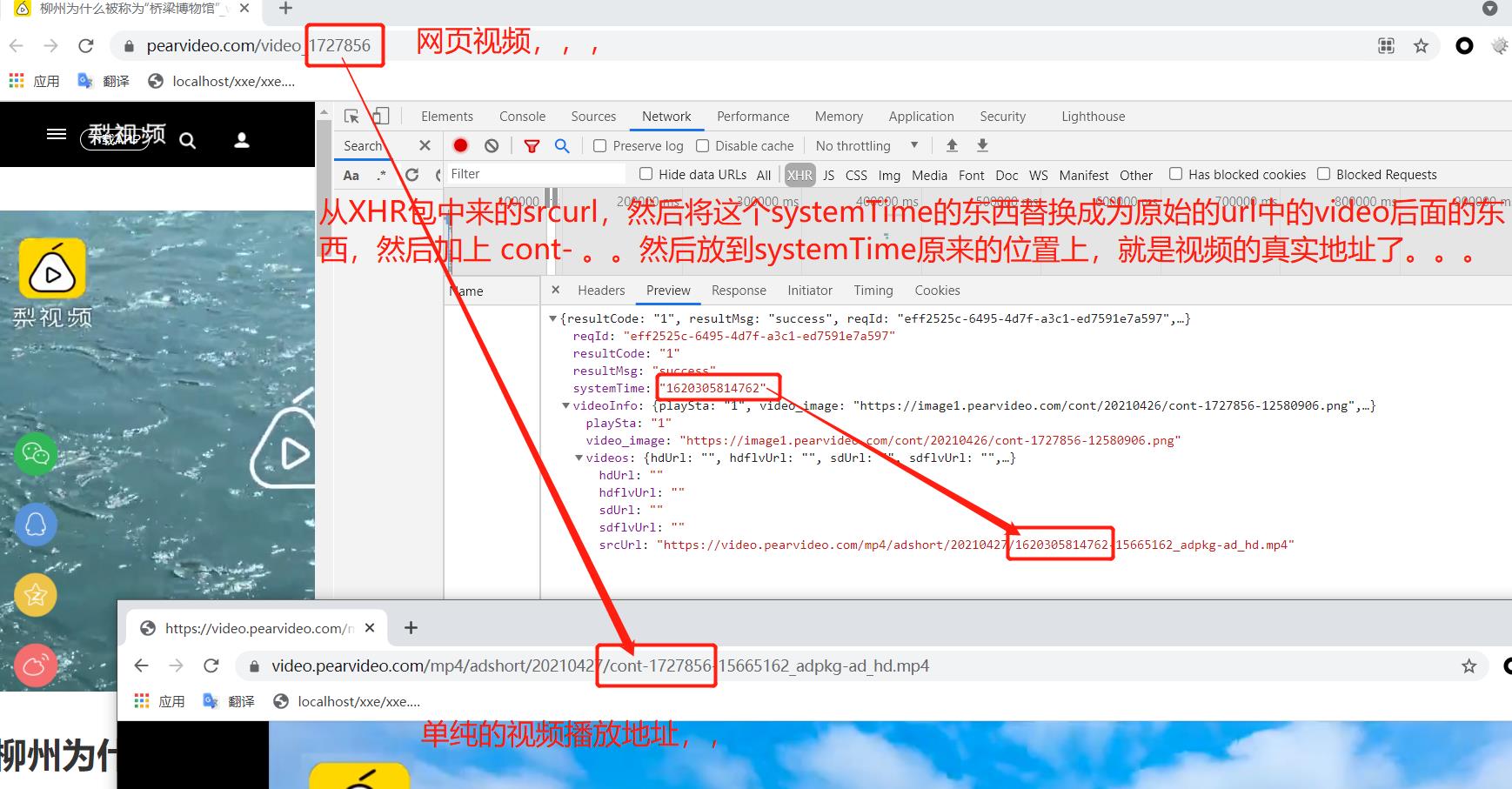
2. 获取url中的数据,不用re来做!!!,用到url.split。聪明啊!!!
import re
import requests
url = 'https://www.pearvideo.com/video_1727856' # 这个就是点开的视频的样子,这个也是可以批量抓取的,抓不到的是视频的本身的地址。
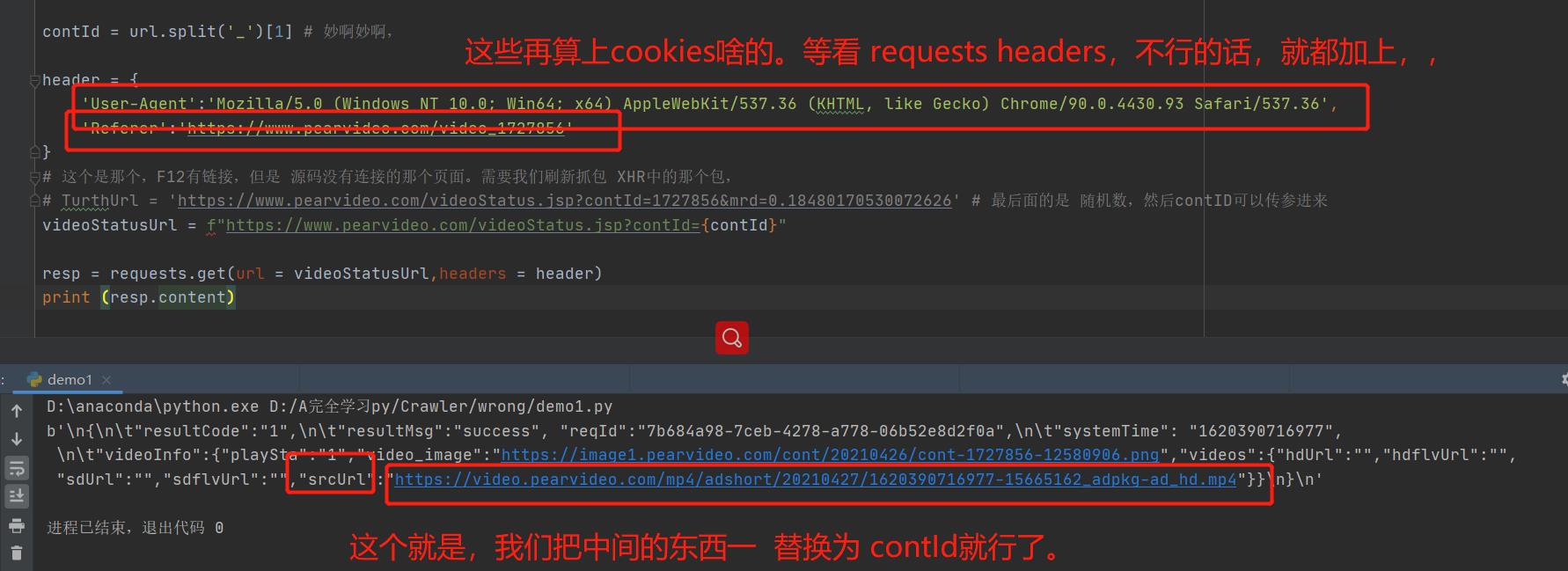
contId = url.split('_')[1] # 妙啊妙啊,
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer':'https://www.pearvideo.com/video_1727856'
}
# 这个是那个,F12有链接,但是 源码没有连接的那个页面。需要我们刷新抓包 XHR中的那个包,
# TurthUrl = 'https://www.pearvideo.com/videoStatus.jsp?contId=1727856&mrd=0.18480170530072626' # 最后面的是 随机数,然后contID可以传参进来
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}"
resp = requests.get(url = videoStatusUrl,headers = header)
print (resp.content)
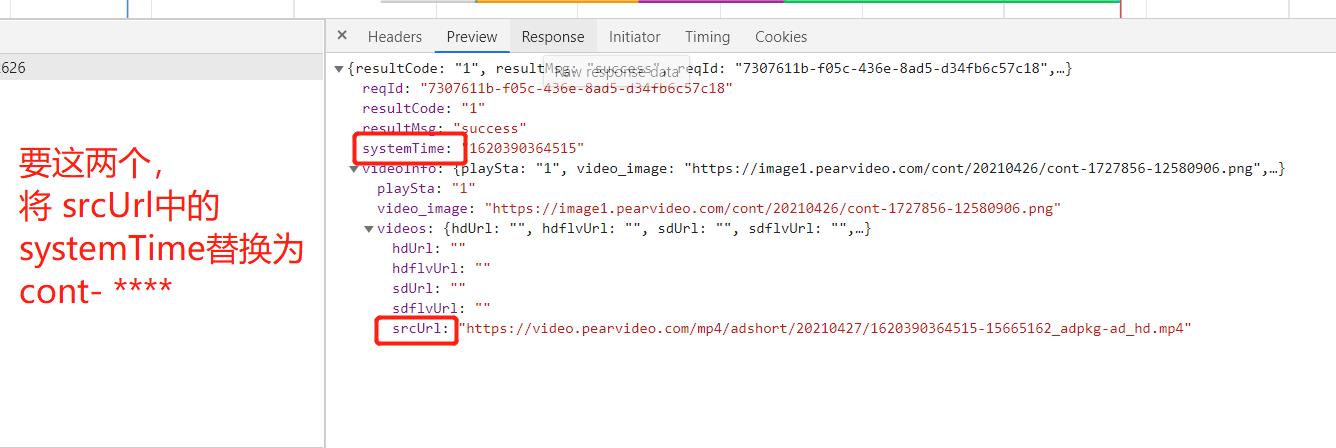
3. url的部分内容的替换:
import re
import requests
url = 'https://www.pearvideo.com/video_1727856' # 这个就是点开的视频的样子,这个也是可以批量抓取的,抓不到的是视频的本身的地址。
contId = url.split('_')[1] # 妙啊妙啊,
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer':'https://www.pearvideo.com/video_1727856'
}
# 这个是那个,F12有链接,但是 源码没有连接的那个页面。需要我们刷新抓包 XHR中的那个包,
# TurthUrl = 'https://www.pearvideo.com/videoStatus.jsp?contId=1727856&mrd=0.18480170530072626' # 最后面的是 随机数,然后contID可以传参进来
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}"
resp = requests.get(url = videoStatusUrl,headers = header)
# print (resp.json()) # 变成json格式,便于获取变量,
systemTime = resp.json()['systemTime']
srcUrl = resp.json()['videoInfo']['videos']['srcUrl']
# print (srcUrl) # https://video.pearvideo.com/mp4/adshort/20210427/1620391070930-15665162_adpkg-ad_hd.mp4 .。这个还要替换一下
# 这个 是 真正的 https://video.pearvideo.com/mp4/adshort/20210427/cont-1727856-15665162_adpkg-ad_hd.mp4
truthUrl = srcUrl.replace(systemTime,f'cont-{contId}')
print (truthUrl)
# 下载视频:
with open('a.mp4',mode='wb') as f :
f.write(requests.get(url = truthUrl).content)
print ("oh");
以上是关于爬虫学习 ----- 第二章 爬取静态网站 ---------- 05. 防盗链,爬取梨视频之 referer XHR的主要内容,如果未能解决你的问题,请参考以下文章