爬虫学习 ----- 第二章 爬取静态网站 ---------- 01 . re 模块学习 ---- python的re库
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习 ----- 第二章 爬取静态网站 ---------- 01 . re 模块学习 ---- python的re库相关的知识,希望对你有一定的参考价值。
目录:
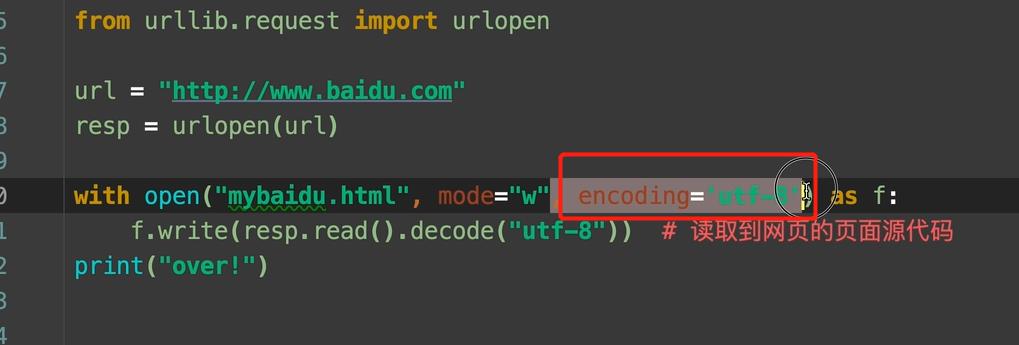
1. 写入文件的时候要encoding一下。
window默认的编码是 gbk 编码,

1. re
1. 正则的基础知识
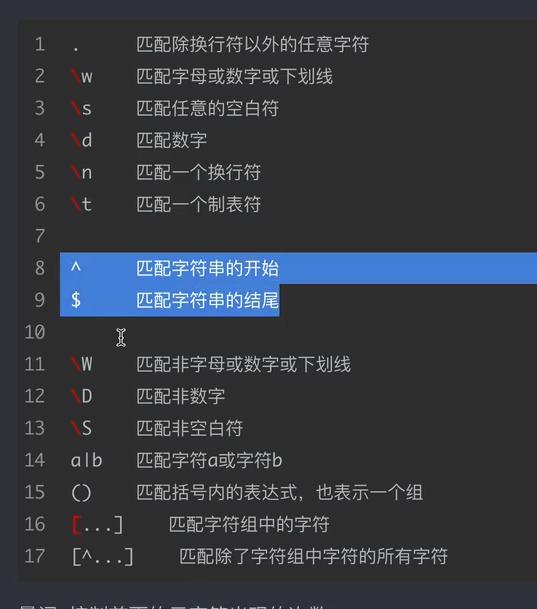
字符组,数字,字母: [a-zA-Z0-9]
[^***]。除了这里面的都行,
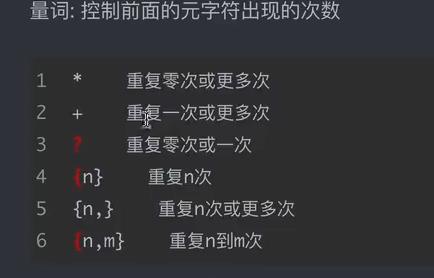
.*?非贪婪匹配
2. python的re模块。

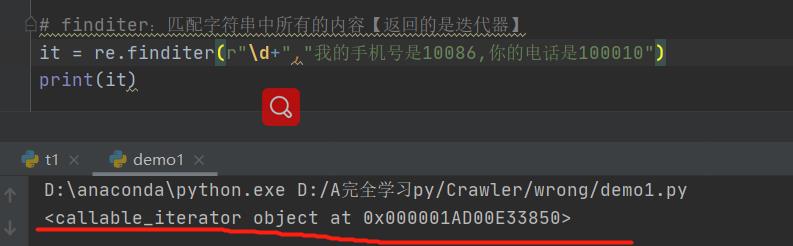
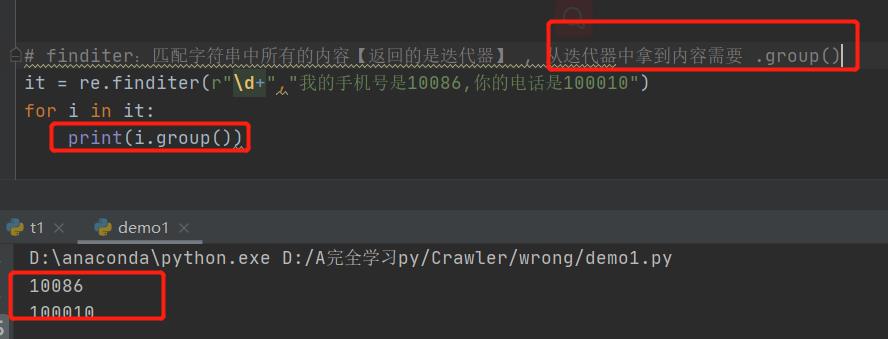
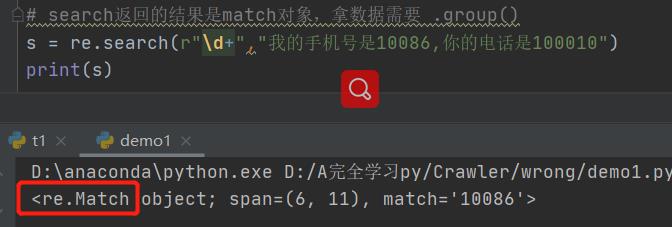
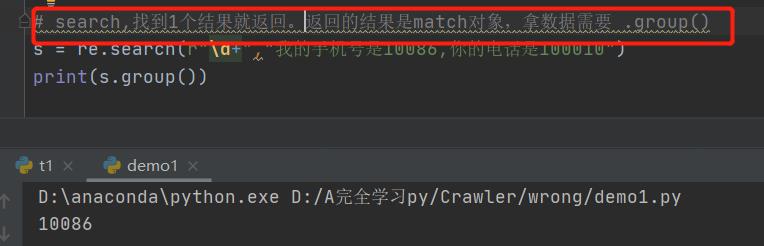
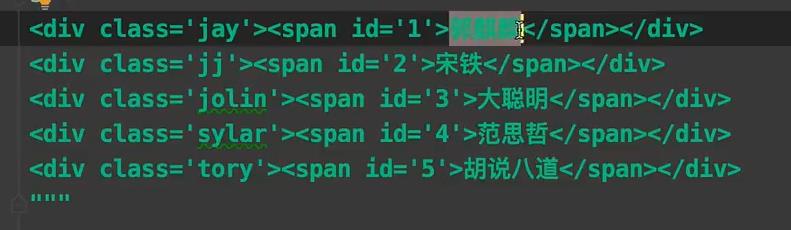
2. re.finditer ( r"\\d+", “********”) 最常用!!!!
取东西:

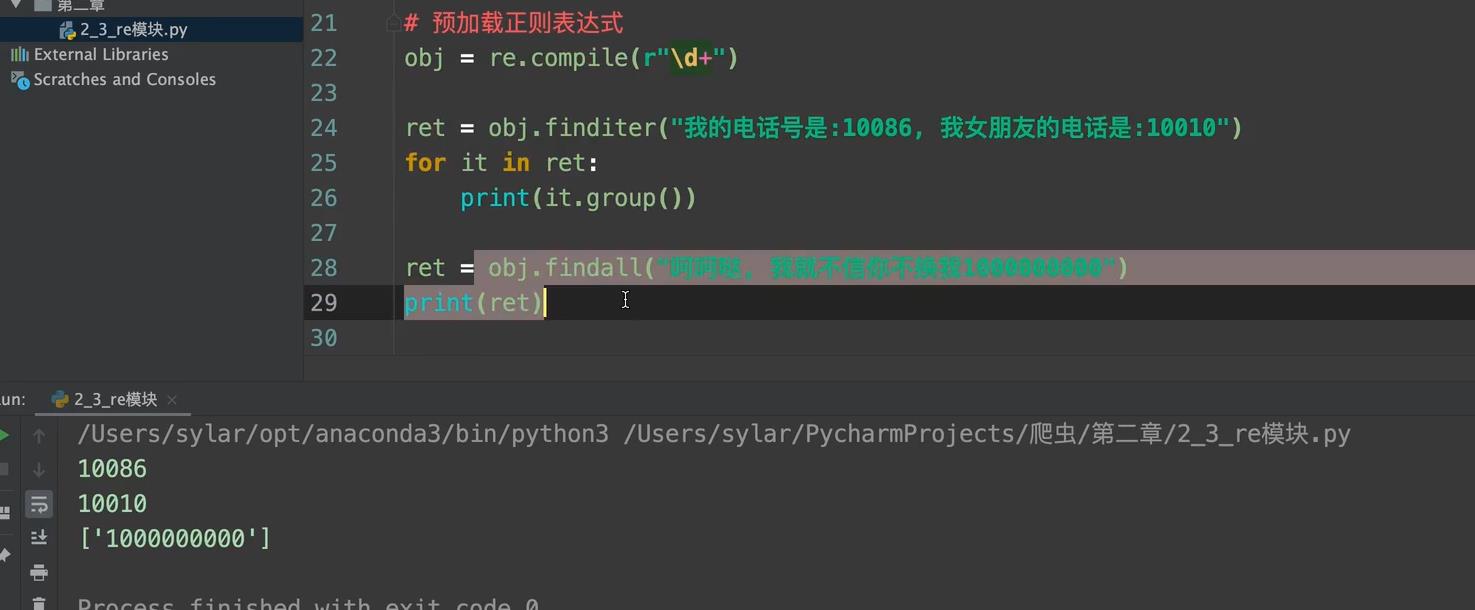
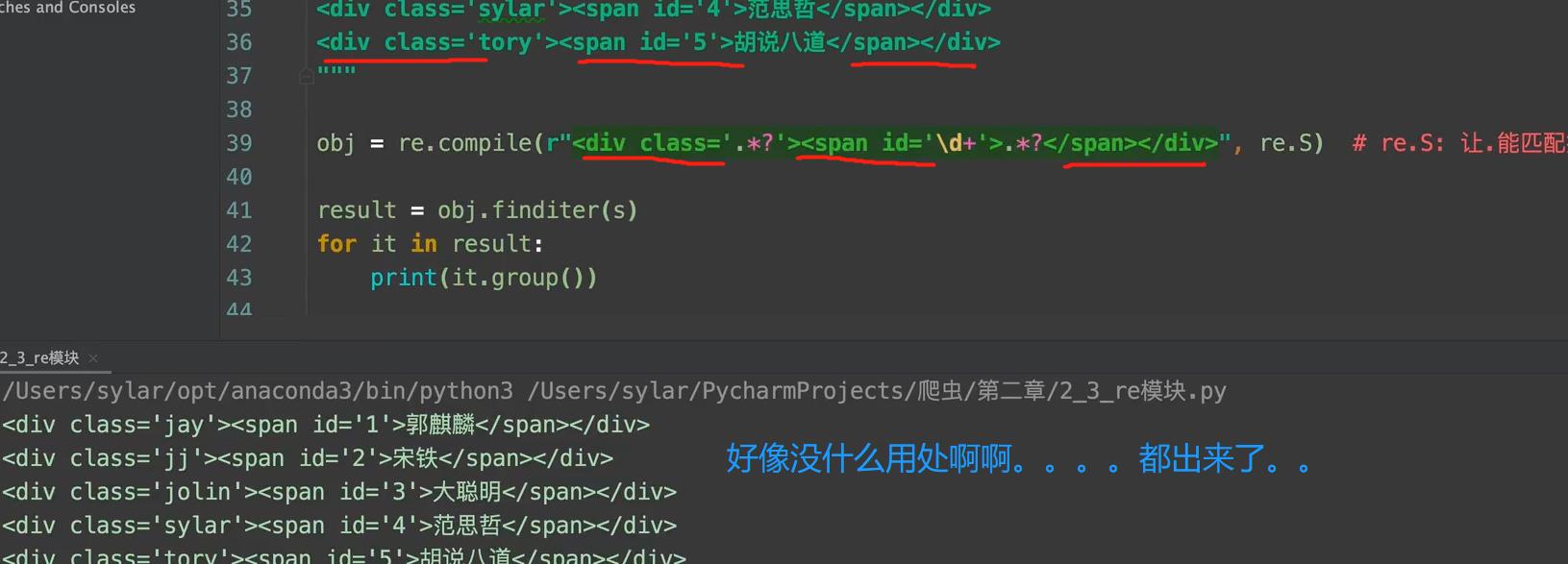
3. 预加载正则表达式:
正则很长的化,就很方便。。
4. 从正则中取出数据来。
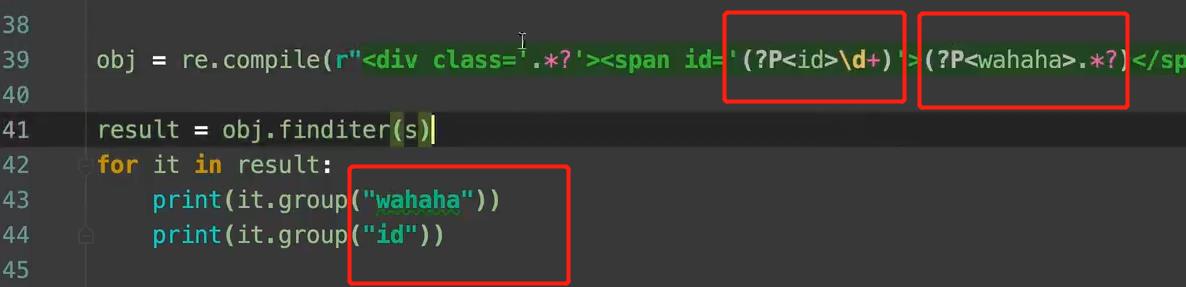
- 我想把里面的名字什么的拿出来。
(?P<name>正则 ) 可以单独从正则匹配的内容中进一步提取内容
(?P<name>.*?)。然后那的时候,it.group('name')。就拿到了。
以上是关于爬虫学习 ----- 第二章 爬取静态网站 ---------- 01 . re 模块学习 ---- python的re库的主要内容,如果未能解决你的问题,请参考以下文章