用Python分析了7w+《悬崖之上》影评,看看观众都是怎么说?
Posted 程序员启航
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python分析了7w+《悬崖之上》影评,看看观众都是怎么说?相关的知识,希望对你有一定的参考价值。
大家好,我是启航
五一假期的的时候和家人看了张艺谋导演《悬崖之上》,觉得还不错。并且在五一档的电影中,要说最为好看的可谓是张艺谋导演《悬崖之上》了,在五一档电影中评分排名第一。

虽然总票房还差一点,但是我觉得总票房升上去只是时间问题,毕竟拍片场次那么高。

本文通过爬取《悬崖之上》豆瓣短评,进行数据可视化分析,在后台回复【悬崖】即可获得全部代码。
01
数据采集
在之前的文章我们已经对爬虫这方面讲解了很多,数据采集有过详细的介绍,有不懂的小伙伴可以后台回复:入群,我们一起交流。这里我们直接展示爬虫核心代码:
for page in range(80):
try:
params = (
('start', str(page * 20)),
('limit', '20'),
('status', 'P'),
('sort', 'new_score'),
('comments_only', '1'),
('ck', 'qN8_'),
)
r = requests.get('https://movie.douban.com/subject/32493124/comments', headers=headers, params=params, cookies=cookies)
yonghumingchengs = re.findall('<a title="(.*?)href.*?">', r.json()['html'], re.S)
youyongshus = re.findall('<span class="votes vote-count">(.*?)</span>', r.json()['html'], re.S)
pinglunshijians = re.findall('<span class="comment-time " title="(.*?)">', r.json()['html'], re.S)
pingluns = re.findall('<span class="short">(.*?)</span>', r.json()['html'], re.S)
for i in range(20):
a = a + 1
sheet.append([yonghumingchengs[i], youyongshus[i], pinglunshijians[i].split()[0].split("-")[-1],
pinglunshijians[i].split()[1].split(":")[0], pingluns[i]])
print(f"已爬取完第{page}页数据,存入{i + 1}条数据....")
except:
wb.save("全部.xlsx")
print(f"共爬取{page}页数据,存入{a}条数据....")
~~~
02
数据清洗
01
合并Excel
因为是分全部、好评、一般、差评四个部分来对影评进行爬取的,所以我们要对这四个影评文件夹进行合并。代码如下:
for i in files:
wb = openpyxl.load_workbook(i)
sheet = wb['豆瓣评论']
for i in range(2,502):
A_cell = sheet[f'A{i}']
B_cell = sheet[f'B{i}']
C_cell = sheet[f'C{i}']
D_cell = sheet[f'D{i}']
E_cell = sheet[f'E{i}']
a = [A_cell.value,int(B_cell.value),int(C_cell.value),int(D_cell.value),E_cell.value]
sheet_1.append(a)
~~~
02
导入景点数据
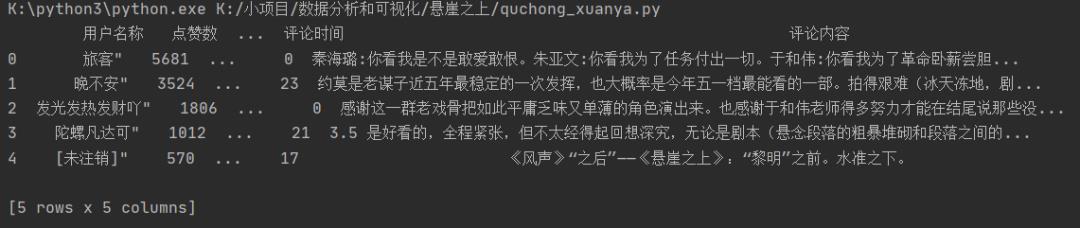
用pandas读取合并后的影评数据并预览。
df = pd.read_excel('总.xlsx',names=['用户名称','点赞数','评论日期','评论时间','评论内容'])
print(df.head())
02
删除重复数据
df.drop_duplicates()
03
查看数据类型
查看字段类型和缺失值情况,符合分析需要,无需另做处理。
df.info()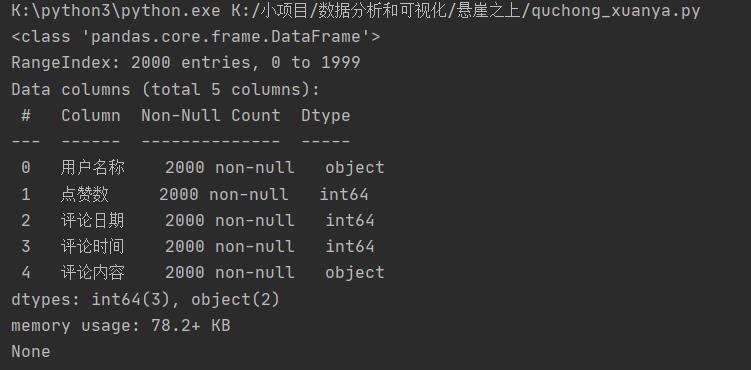
03
数据可视化
01
各类评论占比
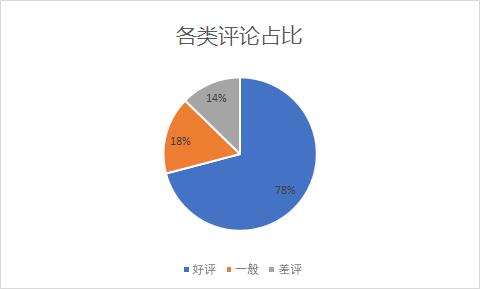
这部电影的短评数有7w+,好评竟能占到快80%,果然张艺谋导演的剧都是好剧~,建议大家抓住五一的小尾巴,去刷一下这个剧。
02
主演提及次数
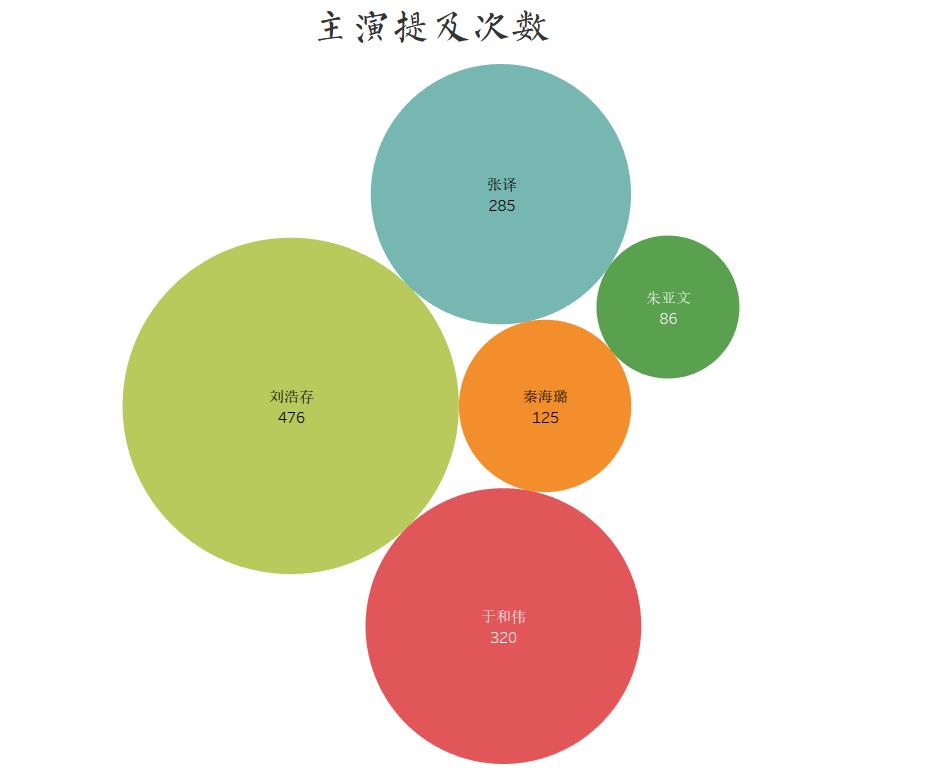
这部影片一共有五个主演,没想到男一张译和女一秦海璐竟然不是被提及次数最多的,反而是刘浩存被提及次数最多,那让我们来看看大家在影评中都是怎么评价她的。

从词云图中看出,作为新晋的谋女郎,刘浩存确实实力很强,演技很好,同时影片中的角色也很好,可能是这样才导致它的被提及次数成为第一吧。
03
各类星级占比
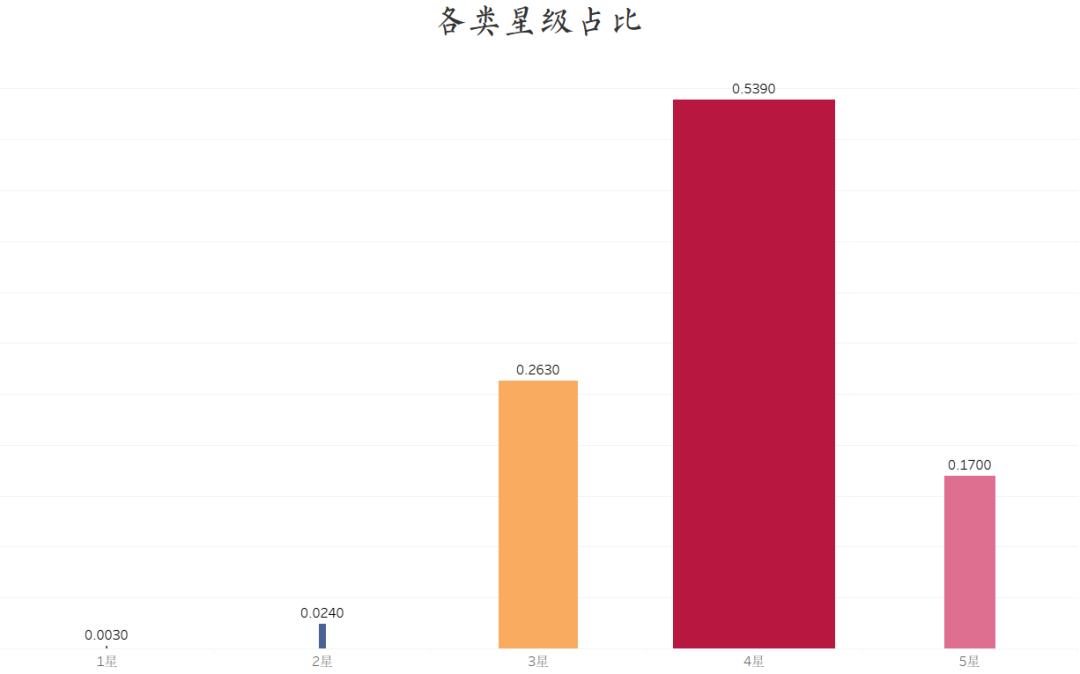
从图中,我们可以明显的看出,打4星的观众最多,占了54%,其次是3星和5星,分别占26%和17%。这样看来,观众还是非常肯定这部影片的。
04
评论发表时间分布
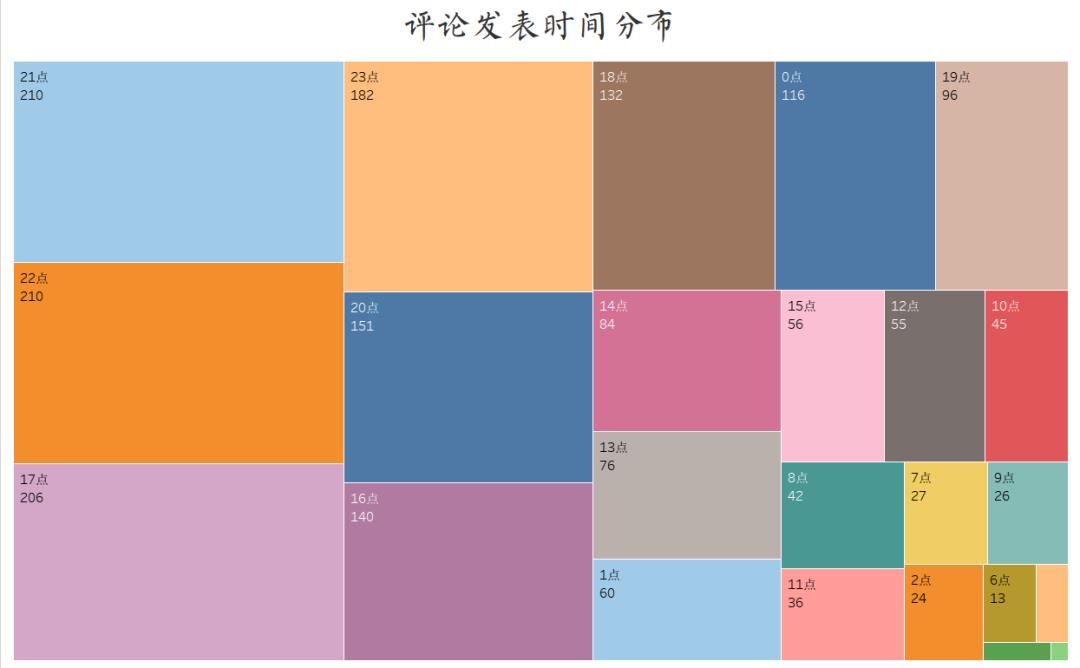
从图中,我们可以看出,大部分影评发表时间在晚上和凌晨,白天发表影评的数量很少,影院可以适当增加晚上和凌晨的场次。
04. 小结
1. 本文仅供学习研究使用,提供的评论仅供参考。
2. 本人对影视的了解有限,言论粗糙,还请勿怪
如果大家对本文代码源码感兴趣,公众号(程序员启航)后台回复:悬崖,获取完整代码!

文章到这里就结束了,感谢你的观看
说实在的,每次在后台看到一些读者的回应都觉得很欣慰,我想把我收藏的一些编程干货贡献给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python所有知识点汇总(可以弄清楚Python的所有方向和技术)
*如果你用得到的话可以直接拿走,在我的QQ技术交流群里,可以自助拿走,群号是421592457。*
以上是关于用Python分析了7w+《悬崖之上》影评,看看观众都是怎么说?的主要内容,如果未能解决你的问题,请参考以下文章