[Python] 通过采集23万条数据,对《哪吒》影评分析
Posted reader
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python] 通过采集23万条数据,对《哪吒》影评分析相关的知识,希望对你有一定的参考价值。
一、说明
数据来源:猫眼;
运行环境:Win10/Python3.7 和 Win7/Python3.5;
分析工具:jieba、WorldCloud、pyecharts和matplotlib;
程序基本思路:分析接口 —> 下载数据 —> 过滤数据 —> 保存文件 —> 统计分析;
注意:本文所有图文和源码仅供学习,请勿他用,转发请注明出处!
参考:https://www.cnblogs.com/reader/p/10070629.html
二、开始
样本数据(23万+):
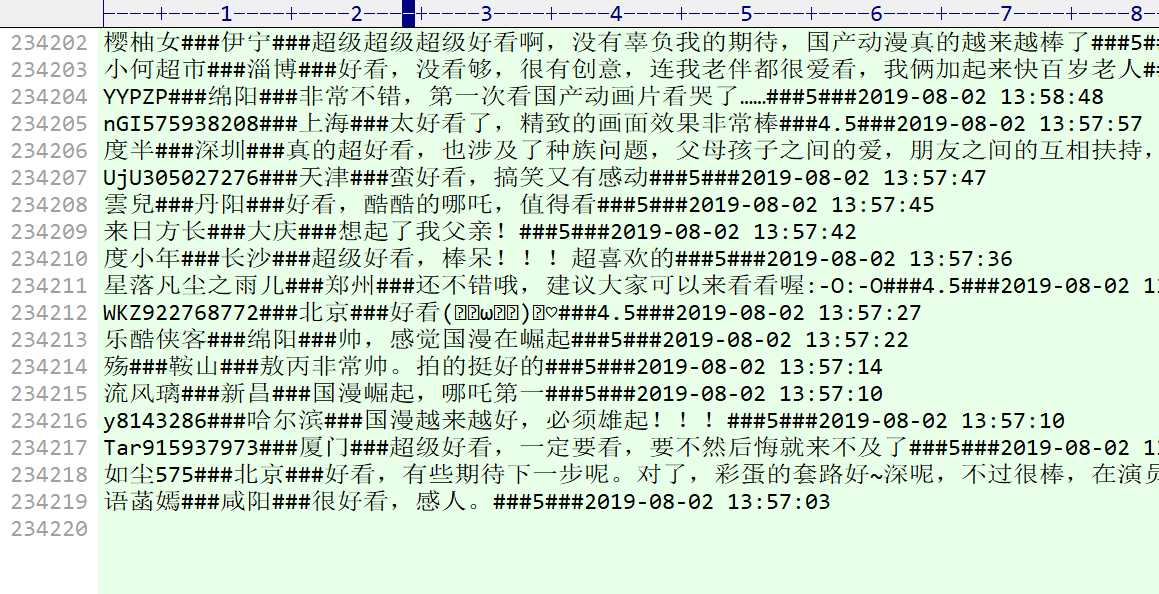
因为运行的脚本和之前基本差不多,对于数据采集和统计分析的流程直接参考:https://www.cnblogs.com/reader/p/10070629.html
优化下载部分代码,防止因网络原因导致下载失败,导致的程序停止(这里也可以考虑设置重试下载次数):
1 def download(self, url): 2 """下载内容""" 3 self.showstep(‘Downloading:‘+url) 4 5 # 防止网络原因导致下载失败 6 while True: 7 try: 8 response = requests.get(url, headers=self.headers) 9 10 if response.status_code == 200: 11 return response.json() 12 else: 13 self.showstep(‘Download Fail:‘ + url) 14 return "" 15 except Exception as e: 16 print(e) 17 time.sleep(3)
三、图形化分析
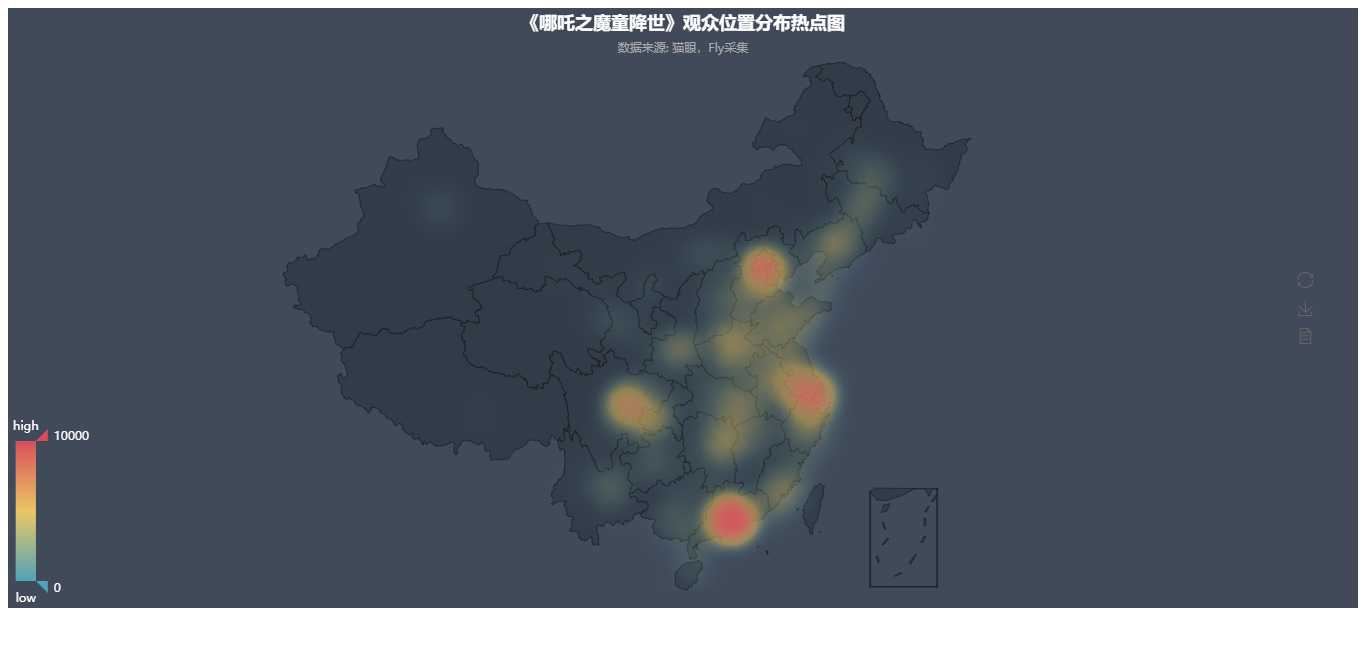
3.1 观众城市分布热点图
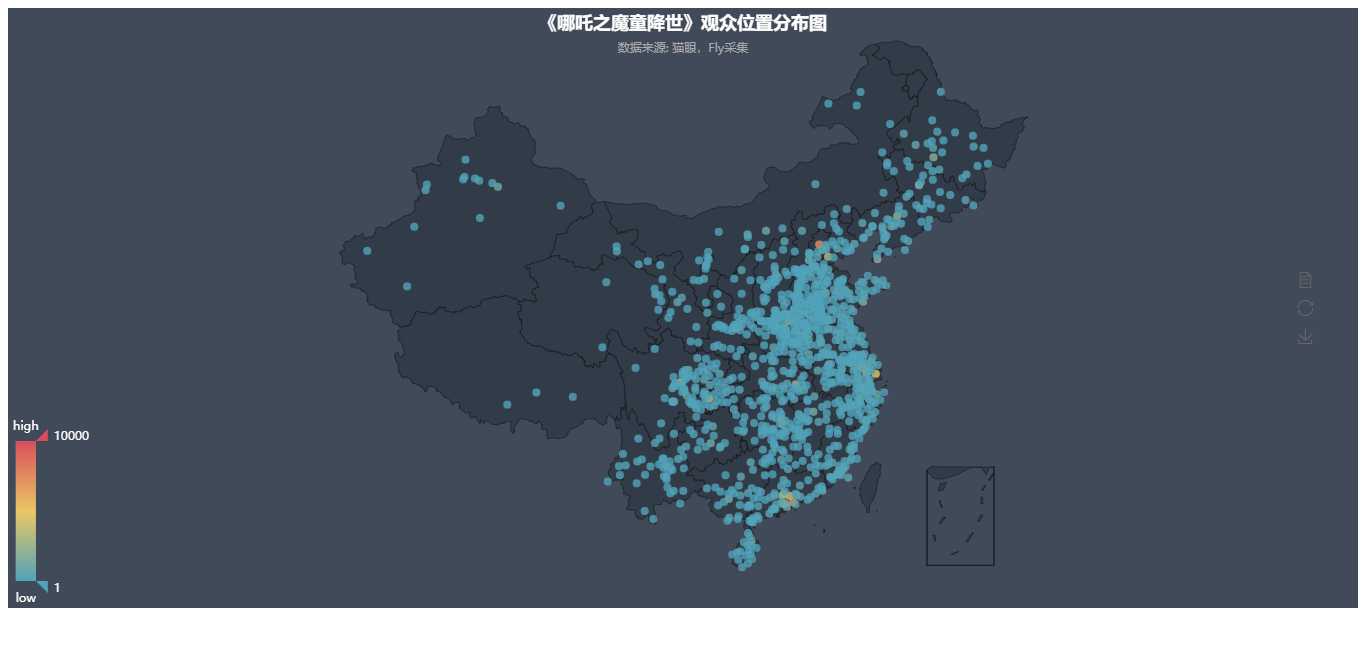
3.2 观众位置分布图
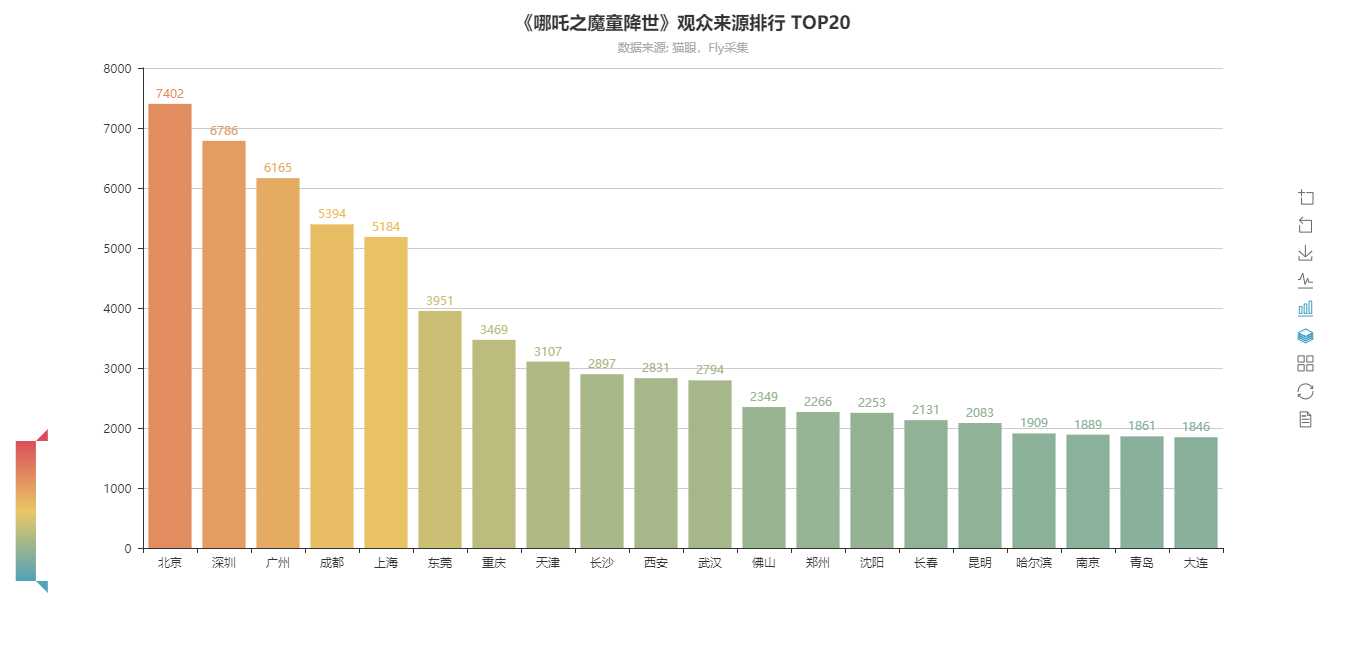
3.3 城市分布人数排行 TOP 20
3.4 词云

以上是关于[Python] 通过采集23万条数据,对《哪吒》影评分析的主要内容,如果未能解决你的问题,请参考以下文章