Python爬取《流浪地球》豆瓣影评与数据分析
Posted Facktoo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取《流浪地球》豆瓣影评与数据分析相关的知识,希望对你有一定的参考价值。
一、选题背景:
2019年年初,《流浪地球》全国上榜。在豆瓣上,首日开分站稳8分以上,评分了之后点映的高热。微博上跟着出现吴京客串31天与6000万的热度搜。知乎上关于“评价刘慈欣如何评价刘慈欣小说改编的同名电影《流浪地球片》”的热门话题,包括导演郭帆的最高赞回答。
二、数据说明:
本篇文章爬取了豆瓣网上《流浪地球》的部分影评,并进行数据分析和可视化处理。
三、实施过程及代码:
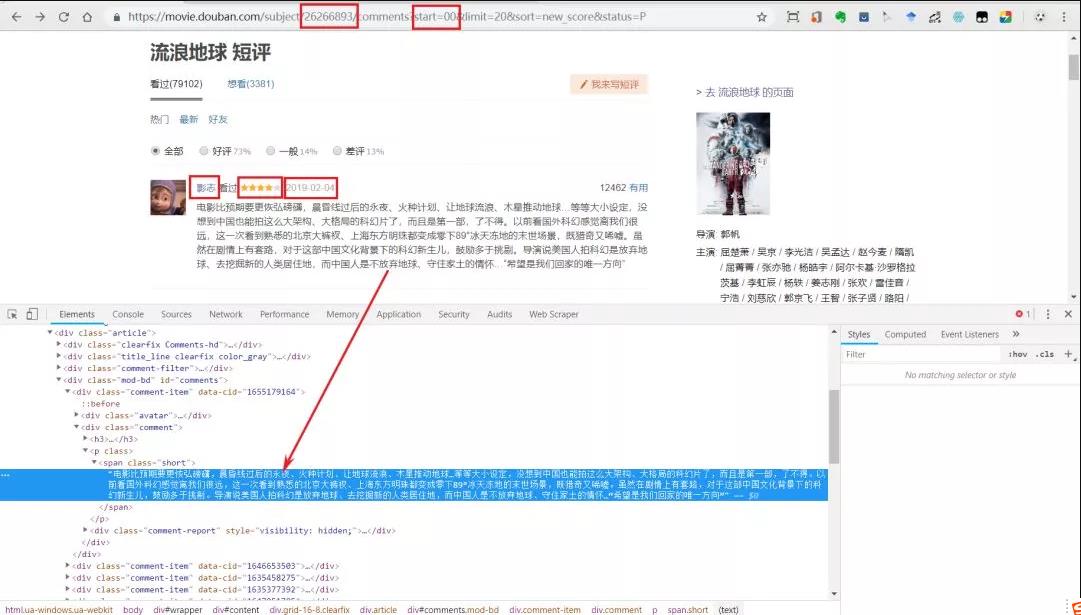
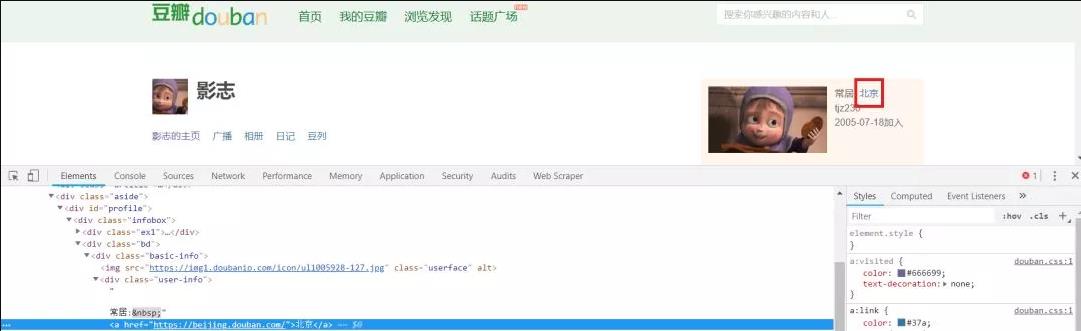
1 # 爬取电影《流浪地球》的影评 2 import requests 3 from lxml import etree 4 from tqdm import tqdm 5 import time 6 import random 7 import pandas as pd 8 import re 9 10 name_list, content_list, date_list, score_list, city_list = [], [], [], [], [] 11 movie_name = "" 12 13 def get_city(url, i): 14 time.sleep(round(random.uniform(2, 3), 2)) 15 headers = { 16 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'} 17 cookies = {\'cookie\': \'bid=Ge7txCUP3v4; ll="108303"; _vwo_uuid_v2=DB48689393ACB497681C7C540C832B546|f3d53bcb0314c9a34c861e9c724fcdec; ap_v=0,6.0; dbcl2="159607750:sijMjNWV7ek"; ck=kgmP; push_doumail_num=0; push_noty_num=0; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1549433417%2C%22https%3A%2F%2Fmovie.douban.com%2Fsubject%2F26266893%2Fcomments%3Fsort%3Dnew_score%26status%3DP%22%5D; _pk_ses.100001.8cb4=*; __lnkrntdmcvrd=-1; __yadk_uid=KqejvPo3L0HIkc2Zx7UXOJF6Vt9PpoJU; _pk_id.100001.8cb4=91514e1ada30bfa5.1549433417.1.1549433694.1549433417\'} # 2018.7.25修改, 18 res = requests.get(url, cookies=cookies, headers=headers) 19 if (res.status_code == 200): 20 print("\\n成功获取第{}个用户城市信息!".format(i)) 21 else: 22 print("\\n第{}个用户城市信息获取失败".format(i)) 23 pattern = re.compile(\'<div class="user-info">.*?<a href=".*?">(.*?)</a>\', re.S) 24 item = re.findall(pattern, res.text) # list类型 25 return (item[0]) # 只有一个元素,所以直接返回
(1)网页分析
获取对象:
-
评论用户
-
评论内容
-
评分
-
评论日期
-
用户所在城市
(2)数据获取与存储
1、获取饼干
本人用的是Chrome浏览器,Ctrl+F12进入开发者工具页面。F5刷新一下出现数据,找到cookies、headers。
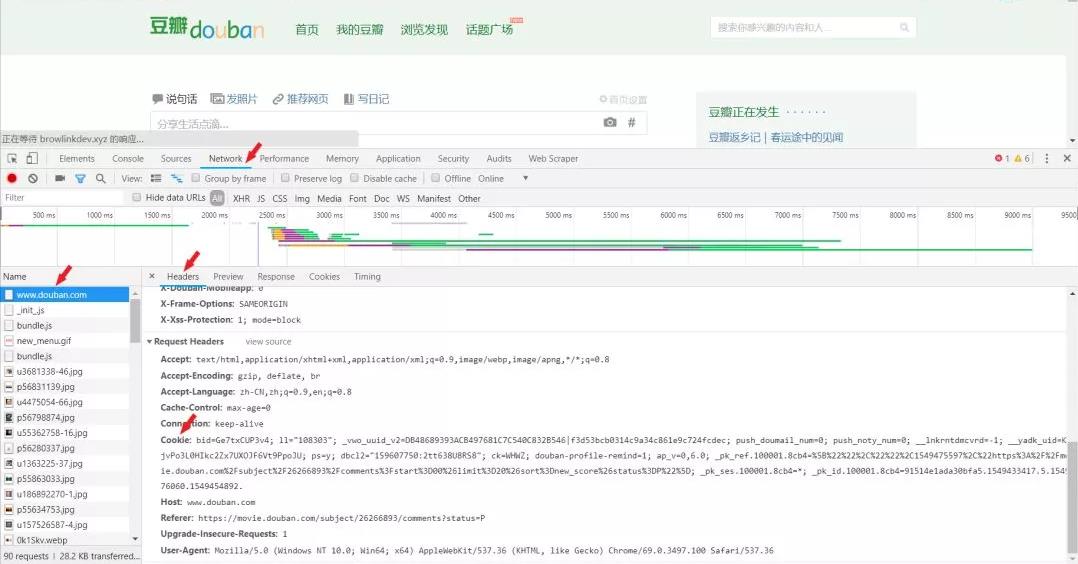
2、加载headers、cookies,并用requests库获取信息
1 def get_content(id, page): 2 headers = { 3 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'} 4 cookies = {\'cookie\': \' 此处填入自己的cookies,否则不能正常爬取 \'} 5 url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P" 6 res = requests.get(url, headers=headers, cookies=cookies) 7 8 pattern = re.compile(\'<div id="wrapper">.*?<div id="content">.*?<h1>(.*?) 短评</h1>\', re.S) 9 global movie_name 10 movie_name = re.findall(pattern, res.text)[0] # list类型 11 12 res.encoding = "utf-8" 13 if (res.status_code == 200): 14 print("\\n第{}页短评爬取成功!".format(page + 1)) 15 print(url) 16 else: 17 print("\\n第{}页爬取失败!".format(page + 1)) 18 19 with open(\'html.html\', \'w\', encoding=\'utf-8\') as f: 20 f.write(res.text) 21 f.close() 22 x = etree.HTML(res.text)
3、解析需求数据
此处我用xpath解析。发现有的用户虽然有评论,但没有给评分,所以分数和日期这两个的xpath位置是会变动的。因此需要加判断,如果发现分数里面解析日期,证明该条评论没有给出评分。
1 for i in range(1, 21): # 每页20个评论用户 2 name = x.xpath(\'//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()\'.format(i)) 3 # 下面是个大bug,如果有的人没有评分,但是评论了,那么score解析出来是日期,而日期所在位置spen[3]为空 4 score = x.xpath(\'//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title\'.format(i)) 5 date = x.xpath(\'//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title\'.format(i)) 6 m = \'\\d{4}-\\d{2}-\\d{2}\' 7 try: 8 match = re.compile(m).match(score[0]) 9 except IndexError: 10 break 11 if match is not None: 12 date = score 13 score = ["null"] 14 else: 15 pass 16 content = x.xpath(\'//*[@id="comments"]/div[{}]/div[2]/p/span/text()\'.format(i)) 17 id = x.xpath(\'//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href\'.format(i)) 18 try: 19 city = get_city(id[0], i) # 调用评论用户的ID城市信息获取 20 except IndexError: 21 city = " " 22 name_list.append(str(name[0])) 23 score_list.append(str(score[0]).strip(\'[]\\\'\')) # bug 有些人评论了文字,但是没有给出评分 24 date_list.append(str(date[0]).strip(\'[\\\'\').split(\' \')[0]) 25 content_list.append(str(content[0]).strip()) 26 city_list.append(city)
4、获取电影名称
1 pattern = re.compile(\'<div id="wrapper">.*?<div id="content">.*?<h1>(.*?) 短评</h1>\', re.S) 2 global movie_name 3 movie_name = re.findall(pattern, res.text)[0] # list类型
5、数据存储
1 def main(ID, pages): 2 global movie_name 3 for i in tqdm(range(0, pages)): # 豆瓣只开放500条评论 4 get_content(ID, i) # 第一个参数是豆瓣电影对应的id序号,第二个参数是想爬取的评论页数 5 time.sleep(round(random.uniform(3, 5), 2)) 6 infos = {\'name\': name_list, \'city\': city_list, \'content\': content_list, \'score\': score_list, \'date\': date_list} 7 data = pd.DataFrame(infos, columns=[\'name\', \'city\', \'content\', \'score\', \'date\']) 8 data.to_csv(movie_name + ".csv") # 存储名为 电影名.csv
(3)、数据分析与可视化
1、获取饼干
1 # 数据分析可视化 2 import os 3 import pandas as pd 4 from pandas import DataFrame 5 import re 6 from pyecharts import Line, Geo, Bar, Pie, Page, ThemeRiver 7 from snownlp import SnowNLP 8 import jieba 9 import matplotlib.pyplot as plt 10 from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator 11 12 fth = open(\'pyecharts_citys_supported.txt\', \'r\', encoding=\'utf-8\').read() # pyecharts支持城市列表
城市信息过滤器中文字
1 # 过滤字符串只保留中文 2 def translate(str): 3 line = str.strip() 4 p2 = re.compile(\'[^\\u4e00-\\u9fa5]\') # 中文的编码范围是:\\u4e00到\\u9fa5 5 zh = " ".join(p2.split(line)).strip() 6 zh = ",".join(zh.split()) 7 str = re.sub("[A-Za-z0-9!!,%\\[\\],。]", "", zh) 8 return str
匹配pyecharts支持的城市列表
1 # 下面是按照列属性读取的 2 def count_sentiment(csv_file): 3 path = os.path.abspath(os.curdir) 4 csv_file = path+ "\\\\" + csv_file + ".csv" 5 csv_file = csv_file.replace(\'\\\\\', \'\\\\\\\\\') 6 d = pd.read_csv(csv_file, engine=\'python\', encoding=\'utf-8\') 7 motion_list = [] 8 for i in d[\'content\']: 9 try: 10 s = round(SnowNLP(i).sentiments, 2) 11 motion_list.append(s) 12 except TypeError: 13 continue 14 result = {} 15 for i in set(motion_list): 16 result[i] = motion_list.count(i) 17 return result
2、基于nownlp的情感分析
snownlp主要进行中文分词(算法是Character-Base Generative Model)、词性可以官网的原理是TnT、3-gram 隐马)、情感分析(有介绍原理,但指定购物类的评论的准确率,其实是因为它的语料库主要是再生方面的,可以自己构建相关领域语料库,替换原来的,准确率也相当不错的)、文本分类(原理是朴素贝叶斯)、转换拼音、繁体转简体、提取文本关键词(原理是TextRank)、提取摘要(原理是TextRank)、分割句子、相似文本(原理是BM25)【摘自CSDN】。在此之前,可以先看一下官网,里面有最基础的一些命令的介绍。官网链接:https://pypi.org/project/snownlp/
因为已知p全部是unicode编码,所以要注意数据是否为unicode编码。是unicode编码,所以不要为了去除中文文本里面含有的英文,所以不要把中文文本里面含有的英文,都转码成统一的编码格式只是调用snownlp原生语料对文本进行分析,snlp重点针对购物领域,所以是为了提高情绪分析评价的适当程度,可以采取训练语料库的方法。
1 def draw_sentiment_pic(csv_file): 2 attr, val = [], [] 3 info = count_sentiment(csv_file) 4 info = sorted(info.items(), key=lambda x: x[0], reverse=False) # dict的排序方法 5 for each in info[:-1]: 6 attr.append(each[0]) 7 val.append(each[1]) 8 line = Line(csv_file+":影评情感分析") 9 line.add("", attr, val, is_smooth=True, is_more_utils=True) 10 line.render(csv_file+"_情感分析曲线图.html")
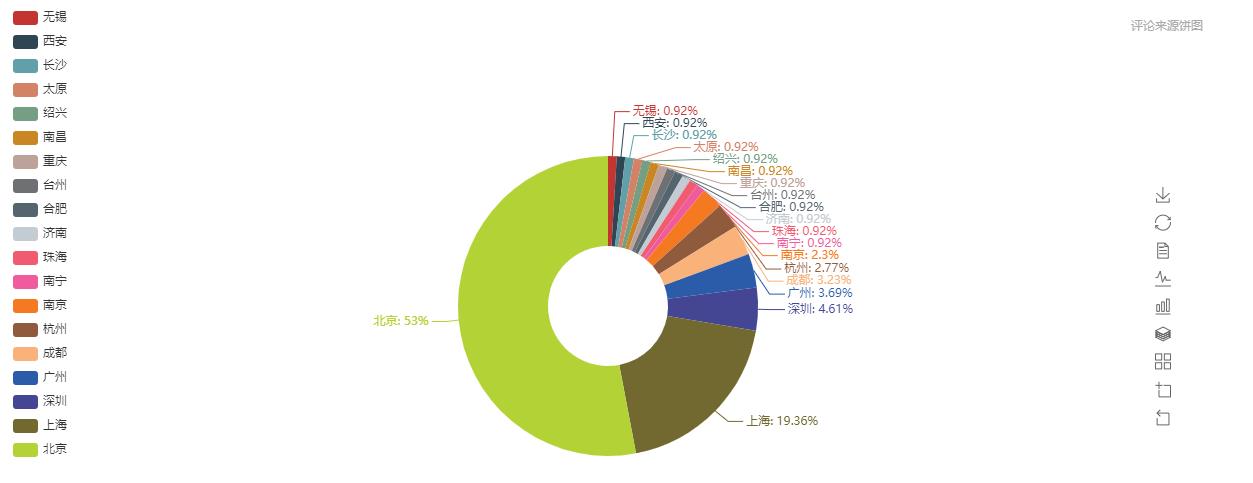
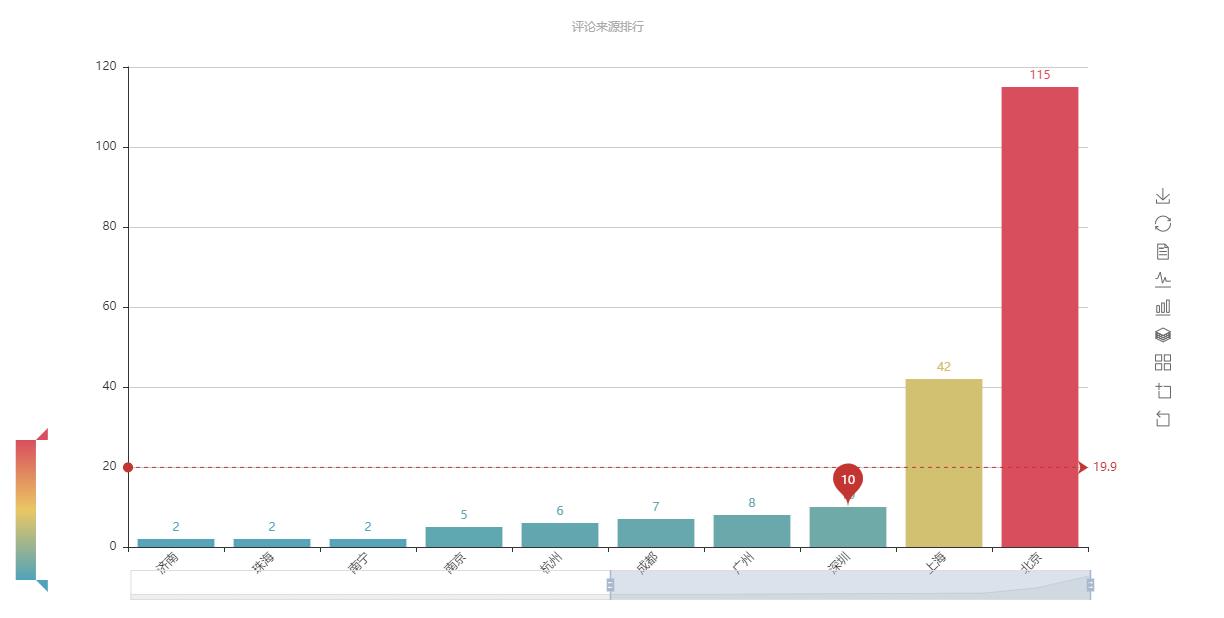
3、评论来源城市分析
调用pyecharts的页面函数,可以在一个图像对象中创建chart,只需要对应的添加组件。
1 def draw_citys_pic(csv_file): 2 page = Page(csv_file+":评论城市分析") 3 info = count_city(csv_file) 4 geo = Geo("","小本聪原创",title_pos="center", width=1200,height=600, background_color=\'#404a59\', title_color="#fff") 5 while True: # 二次筛选,和pyecharts支持的城市库进行匹配,如果报错则删除该城市对应的统计 6 try: 7 attr, val = geo.cast(info) 8 geo.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False, 9 is_piecewise=True, visual_split_number=6, symbol_size=15, is_visualmap=True) 10 except ValueError as e: 11 e = str(e) 12 e = e.split("No coordinate is specified for ")[1] # 获取不支持的城市名称 13 info.pop(e) 14 else: 15 break 16 info = sorted(info.items(), key=lambda x: x[1], reverse=False) # list排序 17 print(info) 18 info = dict(info) # list转dict 19 print(info) 20 attr, val = [], [] 21 for key in info: 22 attr.append(key) 23 val.append(info[key]) 24 25 26 geo1 = Geo("", "评论城市分布", title_pos="center", width=1200, height=600, 27 background_color=\'#404a59\', title_color="#fff") 28 geo1.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False, 29 is_piecewise=True, visual_split_number=10, symbol_size=15, is_visualmap=True, is_more_utils=True) 30 # geo1.render(csv_file + "_城市dotmap.html") 31 page.add_chart(geo1) 32 geo2 = Geo("", "评论来源热力图",title_pos="center", width=1200,height=600, background_color=\'#404a59\', title_color="#fff",) 33 geo2.add("", attr, val, type="heatmap", is_visualmap=True, visual_range=[0, 50],visual_text_color=\'#fff\', is_more_utils=True) 34 # geo2.render(csv_file+"_城市heatmap.html") # 取CSV文件名的前8位数 35 page.add_chart(geo2) 36 bar = Bar("", "评论来源排行", title_pos="center", width=1200, height=600 ) 37 bar.add("", attr, val, is_visualmap=True, visual_range=[0, 100], visual_text_color=\'#fff\',mark_point=["average"],mark_line=["average"], 38 is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45) 39 bar.render(csv_file+"_城市评论bar.html") # 取CSV文件名的前8位数 40 page.add_chart(bar) 41 pie = Pie("", "评论来源饼图", title_pos="right", width=1200, height=600) 42 pie.add("", attr, val, radius=[20, 50], label_text_color=None, is_label_show=True, legend_orient=\'vertical\', is_more_utils=True, legend_pos=\'left\') 43 pie.render(csv_file + "_城市评论Pie.html") # 取CSV文件名的前8位数 44 page.add_chart(pie) 45 page.render(csv_file + "_城市评论分析汇总.html")
4、电影推荐走势分析
-
读取csv文件,以dataframe(df)形式保存
-
遍历df行,保存到list
-
统计相同 日期相同 评分的个数
-
转换为df格式,设置列名
-
按日期排序
-
去新的每一个日期的推荐种,因此需要增加到最少的5种。
1 def score_draw(csv_file): 2 page = Page(csv_file+":评论等级分析") 3 score, date, val, score_list = [], [], [], [] 4 result = {} 5 path = os.path.abspath(os.curdir) 6 csv_file = path + "\\\\" + csv_file + ".csv" 7 csv_file = csv_file.replace(\'\\\\\', \'\\\\\\\\\') 8 d = pd.read_csv(csv_file, engine=\'python\', encoding=\'utf-8\')[[\'score\', \'date\']].dropna() # 读取CSV转为dataframe格式,并丢弃评论为空的记录 9 for indexs in d.index: # 一种遍历df行的方法(下面还有第二种,iterrows) 10 score_list.append(tuple(d.loc[indexs].values[:])) # 目前只找到转换为tuple然后统计相同元素个数的方法 11 print("有效评分总数量为:",len(score_list), " 条") 12 for i in set(list(score_list)): 13 result[i] = score_list.count(i) # dict类型 14 info = [] 15 for key in result: 16 score= key[0] 17 date = key[1] 18 val = result[key] 19 info.append([score, date, val]) 20 info_new = DataFrame(info) # 将字典转换成为数据框 21 info_new.columns = [\'score\', \'date\', \'votes\'] 22 info_new.sort_values(\'date\', inplace=True) # 按日期升序排列df,便于找最早date和最晚data,方便后面插值 23 print("first df", info_new) 24 # 以下代码用于插入空缺的数据,每个日期的评分类型应该有5中,依次遍历判断是否存在,若不存在则往新的df中插入新数值 25 mark = 0 26 creat_df = pd.DataFrame(columns = [\'score\', \'date\', \'votes\']) # 创建空的dataframe 27 for i in list(info_new[\'date\']): 28 location = info_new[(info_new.date==i)&(info_new.score=="力荐")].index.tolist() 29 if location == []: 30 creat_df.loc[mark] = ["力荐", i, 0] 31 mark += 1 32 location = info_new[(info_new.date==i)&(info_new.score=="推荐")].index.tolist() 33 if location == []: 34 creat_df.loc[mark] = ["推荐", i, 0] 35 mark += 1 36 location = info_new[(info_new.date==i)&(info_new.score=="还行")].index.tolist() 37 if location == []: 38 creat_df.loc[mark] = ["还行", i, 0] 39 mark += 1 40 location = info_new[(info_new.date==i)&(info_new.score=="较差")].index.tolist() 41 if location == []: 42 creat_df.loc[mark] = ["较差", i, 0] 43 mark += 1 44 location = info_new[(info_new.date==i)&(info_new.score=="很差")].index.tolist() 45 if location == []: 46 creat_df.loc[mark] = ["很差", i, 0] 47 mark += 1 48 info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True) 49 score_list = [] 50 info_new.sort_values(\'date\', inplace=True) # 按日期升序排列df,便于找最早date和最晚data,方便后面插值 51 print(info_new) 52 for index, row in info_new.iterrows(): # 第二种遍历df的方法 53 score_list.append([row[\'date\'], row[\'votes\'], row[\'score\']]) 54 tr = ThemeRiver() 55 tr.add([\'力荐\', \'推荐\', \'还行\', \'较差\', \'很差\'], score_list, is_label_show=True, is_more_utils=True) 56 page.add_chart(tr) 57 58 attr, v1, v2, v3, v4, v5 = [], [], [], [], [], [] 59 attr = list(sorted(set(info_new[\'date\']))) 60 bar = Bar() 61 for i in attr: 62 v1.append(int(info_new[(info_new[\'date\']==i)&(info_new[\'score\']=="力荐