Spark On Yarn 如何提高CPU利用率
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark On Yarn 如何提高CPU利用率相关的知识,希望对你有一定的参考价值。
问题描述:
Spark on Yarn是利用yarn进行资源调度,这两天我写的一个程序处理大概100W行文本,文本格式是txt,数据大小为50M左右。我将Scala写的代码打包扔到集群上执行,这么点数据量都需要执行3个小时,都说Spark是大数据处理的利器,但是哪里出问题了呢?带着这个问题,我查看了4个Slave节点(24核,60G内存)的CPU利用率如下图:
很明显,Job没有充分利用CPU。
解决方案:
首先我探索了spark-submit里的各个参数,主要关注了:number-executors和executor-cores,改了各种配置,他们都对提高CPU的利用率不起作用。
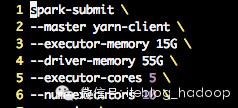
spark-submit参数
由于我的代码核心就是对一个RDD做map操作如下,其中调用了BLAS库做矩阵运算:
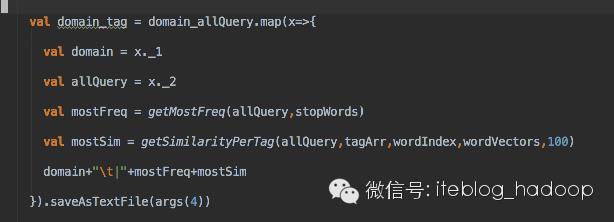
核心代码
我考虑了是不是需要将hadoop里的map/reduce vcore设置大一些,即mapreduce.map.cpu.vcores 和 mapreduce.reduce.cpu.vcores设置大些,可是依然不起作用。
最后,发现问题的关键了,我输入数据源为一个txt文件,数据并没有分片,所以导致单机单核可以执行,并没有利用到Hadoop/Spark的并行处理的优势。下面我就将数据源分片:
split -l 20000 xxx.txt -d -a 4 xxx.txt._
其实也可以这样来使得数据分片,这样的效果没有验证。
val distFile = sc.textFile("data.txt",num_of_partition)
这个命令将数据源(100W行)分成了 50份,这样的话集群就对此文件并行执行了。下面是执行结果:
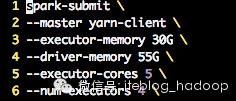
spark-submit
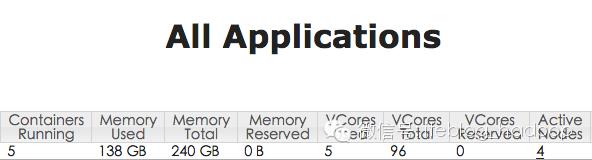
yarn占用资源
感觉速度快了很多,这次任务执行大概20min。如果有说的不对的地方,请大家多多指教,欢迎交流。
原文:http://www.jianshu.com/p/52a3ceedadc5
以上是关于Spark On Yarn 如何提高CPU利用率的主要内容,如果未能解决你的问题,请参考以下文章
关于Spark on Yarn的资源分配与Capacity Scheduler的研究