关于Spark on Yarn的资源分配与Capacity Scheduler的研究
Posted bluishglc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Spark on Yarn的资源分配与Capacity Scheduler的研究相关的知识,希望对你有一定的参考价值。
文章目录
资源调度永远是一个对立统一的问题,在一个限定的资源范围里,我们总是希望资源可以这样有效地分配:
- 宏观上,整体的资源应该尽可能地被共享,这样才能提升资源利用率,节约成本
- 局部上,每一个请求资源的主体有权对一定的资源拥有优先或独占的权利,以确保其作业可以按时完成,这在宏观上是要求对资源进行隔离
简单总结就是:宏观上要求共享,提升整体的资源利用率,局部上需要独占,确保作业及时可控地完成,这是一组相互冲突和矛盾的需求,只有调度策略具备一定的弹性,才能在这种相互冲突的体系获得一种均衡和利益最大化。
回到Yarn的资源调度上,Yarn提供了三种资源分配策略,分别是:Fifo Scheduler,Fair Scheduler和Capacity Scheduler,今天我们单独讨论一下Capacity Scheduler。
首先,我们要时刻记住:一个作业可以获得多少资源是受两个“因子”同时制约的:队列(Queue)和用户(User),一个作业一定是以某个用户的身份提交给某一个队列的,但是多个队列和多个用户下,资源的分配策略将决定这个作业最终可以获得多少资源。通常大家关注队列的状况多一些,而忽视了用户在资源分配中作用,本文会通过测试用例进行一些详细说明。
1. 启用Capacity Scheduler
在开始我们的测试之前,我们先对Capacity Scheduler作一下简单介绍。启用Capacity Scheduler需要在yarn-site.xml文件中配置:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
然后在capacity-scheduler.xml中进行队列和capacity配置。在capacity-scheduler.xml中,有如下四项重要的配置,它们是:
| 配置项 | 描述 |
|---|---|
| yarn.scheduler.capacity.< queue-path>.capacity | 队列的容量,以浮点数表示的百分比%(比如12.5)。在每个层级的队列的容量之和必须等于100。队列中的应用是有可能消费更多的资源的,前提是有空闲资源弹性提供。 |
| yarn.scheduler.capacity.< queue-path>.maximum-capacity | 队列的最大容量,以浮点数表示的百分比%。该限制对于队列中的应用来说是弹性的。默认是-1代表无限制。 |
| yarn.scheduler.capacity.< queue-path>.minimum-user-limit-percent | 每个队列强制安排一个在任意时间分配给一个用户的资源占比限制,如果有资源需求的话。用户限制可以在最小值和最大值之间变化。最小值由该属性决定,而最大值依赖于已经提交了应用的用户数。比如,如果该值为25,有两个用户提交了应用作业到该队列,那么没有一个用户可以使用超过50%的资源。如果第三个用户提交了应用,那么没有一个用户可以占有超过33%的队列资源。当第四个或者更多用户来提交时,那么没有人能占有超过25%的资源。如果设置为100,那么表示没有用户限制。默认值就是100。此值为一个整数。 |
| yarn.scheduler.capacity.< queue-path>.user-limit-factor | 多个队列的容量可以被允许分配给一个用户。默认值是1,表示单一用户占有的资源不可能超过这个队列配置的容量限制,无论这个集群此时有多么空闲。此值是个浮点数。 |
由于Yarn队列资源协调策略是:在同一个父队列下的各子队列可以共享父队列的资源,这一共享优先级是高于其他外部队列的,即不会被外部优先抢占掉。这有利于形成一种“组织内资源共享”的模式。基于这一特性,队列通常被组织成“树”状,在资源的可控性和可预测性上要更好一些,这也符合人们的思维模式,对一项资源,我们总是倾向于先从顶层切分,然后层层细化。以下是一个树状队列的参考:
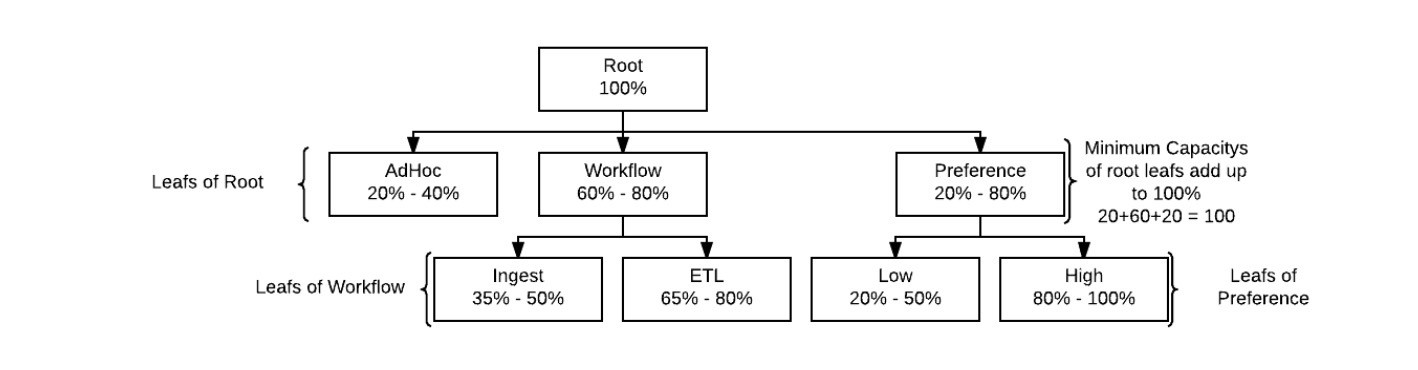
2. 集群信息与配置
本次测试集群由三个Worker节点组成,每个节点48核,192GB内存,以下是yarn-site.xml中的相关配置节选:
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>12288</value>
</property>
<!-- 实际没有配置,默认最小值就是1 -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>32</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>188416</value>
</property>
2.1. yarn.nodemanager.resource.xxx
| 配置项 | 解释 |
|---|---|
| yarn.nodemanager.resource.cpu-vcores | 物理节点上的可用核数,单一容器可申请的最大核数不可以超过该值,但该值未必能生效,实际值总是以由yarn scheduler汇总所有nodemanager情况计算出的值为准 |
| yarn.nodemanager.resource.memory-mb | 物理节点上的可用内存,单一容器可申请的最大核数不可以超过该值,但该值未必能生效,实际值总以由yarn scheduler汇总所有nodemanager情况计算出的值为准 |
yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb用于设定物理节点可分配的最大核数与内存,一个Container只能部署于某一个物理节点上,所以这个值正是单一Container能申请的核数与内存的上限!但是要特别注意:yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb配置的值不一定能生效,yarn scheduler会基于注册的NodeManager重新计算单一容器可能的最大核数与内存,并以计算值为准(这个也比较容易理解,如果物理节点的硬件配置高低不一,只能汇总这些信息找到最小节点,以它的核数/内存为基准设置容器的最大的核数/内存了)。这里配置文件中设置的单一容器最大内核/内存:128核/184GB就明显是不对的,但并不影响集群运行,原因正是如此。如果我们在提交作业时单一容器请求超出48核或188416MB内存,会报如下错误:
InvalidResourceRequestException): Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[vcores], Requested resource=<memory:xxxx, vCores:xx>, maximum allowed allocation=<memory:188416, vCores:48>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:188416, vCores:128>
所以该集群单一容器最大可分配的内核/内存就是:48核/184GB,与物理节点的实际计算能力相当。
2.2. yarn.scheduler.minimum/maximum-xxxx
这里有四个配置项,对应CPU和内存两各一个最大值和最小值。这四个配置项既有独立意义又与实际的scheduler类型(FIFO、Fair、Capacity)相耦合。首先,最大
以下是对上述几个配置项的解释:
| 配置项 | 解释 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 单个容器可申请的最小内存 |
| yarn.scheduler.maximum-allocation-mb | 单个容器可申请的最大内存 |
| yarn.scheduler.minimum-allocation-vcores | 单个容器可申请的最小CPU核数 |
| yarn.scheduler.maximum-allocation-vcores | 单个容器可申请的最大CPU核数 |
在Yarn的Resource Manger页面可以查看到一个container可分配的最大/最小CPU和内存,下图是本测试集群的截图:

3. 测试队列资源划分方案
Total: 144 core
queue-1: 25% - 50%, 36 - 72 core,141312 MB - 282624 MB (138 GB - 276 GB)
queue-2: 75% - 100%, 108 - 144 core
queue-2-1: 33% - 100%, 35 - 144 core,139898 MB - 565248 MB ( 136 GB - 553 GB )
queue-2-1: 67% - 100%, 72 - 144 core,284037 MB - 565248 MB( 277 GB - 553 GB )
4. Spark on Yarn的内存模型

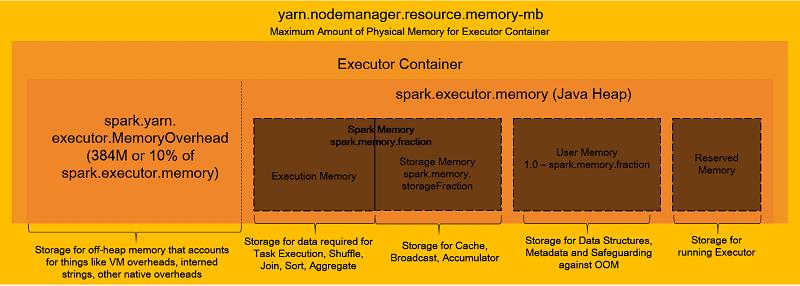
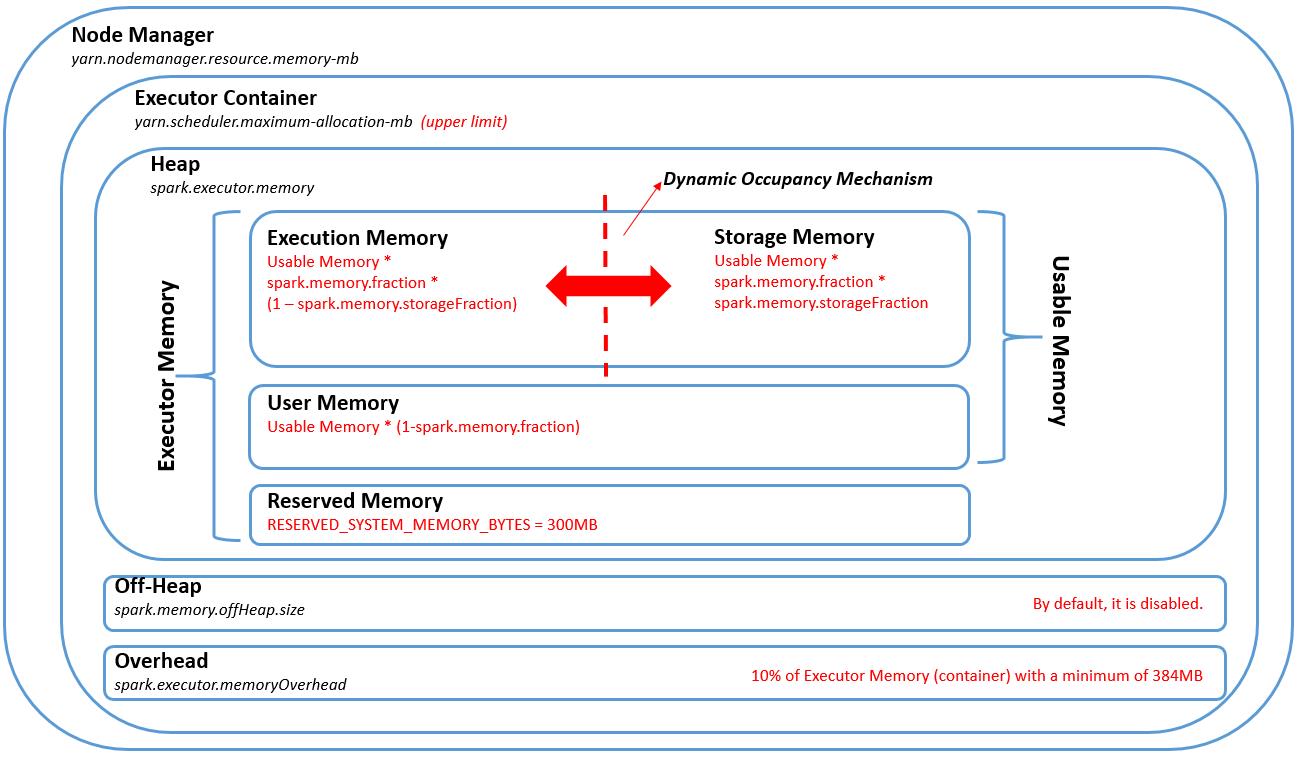
上面的三张图展示的都是Spark On Yarn的内存模型,首先明确一点:一个Saprk Executor运行在一个Yarn Container里,即Executor和Container是一对一的关系。关于内存,我们在提交Spark程序时通过--executor-memory参数指定的就是图中的spark.executor.memory部分的内存,但这不并不是一个Spark Excecutor实际申请的全部内存资源,因为Spark还需要额外申请spark.yarn.executor.memoryOverHead这样一部分内存,该部分内存是用于VM自身、Internal String(https://en.wikipedia.org/wiki/String_interning)等其他一些开销。该部分的大小是以spark.executor.memory为基数,配置百分比,如果得出的内存数小于384 MB,取384 MB。
例如:如果设定spark.executor.memory=1g,spark.yarn.executor.memoryOverHead=0.187,则计算出的这部分OverHead内存是:1024 MB * 0.187 = 191.488 MB,由于该值小于384 MB,故最终会取384 MB。后续的测试中我们会看到这种情形。
关于spark.yarn.executor.memoryOverHead,请参考Spark官方文档:https://spark.apache.org/docs/2.2.3/running-on-yarn.html
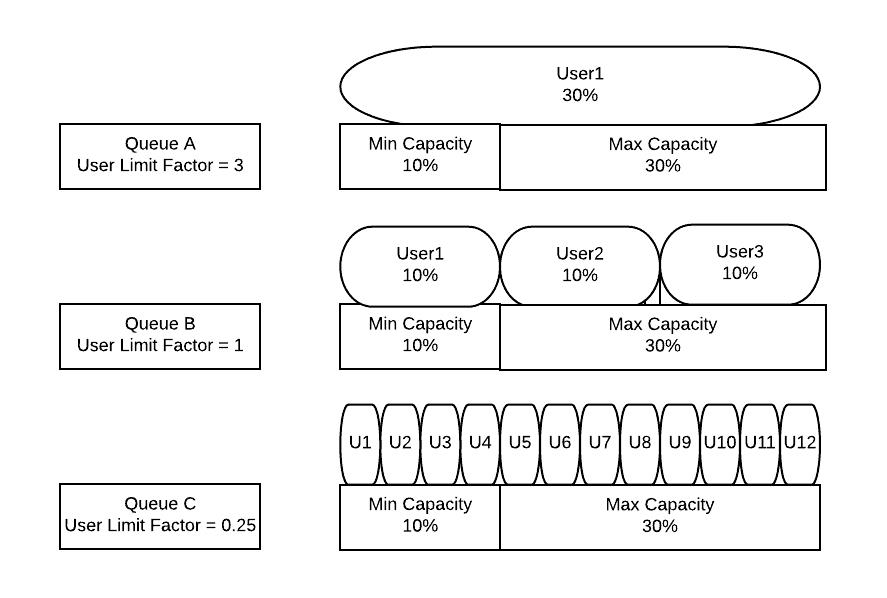
5. user-limit-factor:提升单一用户资源利用率
在单一用户的集群里,user-limit-factor是一个很重要的影响因子。通常情况下,在一个单一用户的应用里,作业对队列的资源利用率是无法自动触达yarn.scheduler.capacity.<queue-path>.maximum-capacity所设定的最大CPU与内存值的,它们最多只能占用到yarn.scheduler.capacity..capacity所设定的值,这让很多人感到不解。约束当前用户的当前作业只能使用capacity设定的资源的根本原因是yarn.scheduler.capacity.<queue-path>.user-limit-factor这个参数的默认值1,它规定了一个用户在队列中所能申请的队列capacity的倍数!由于其默认值是1,则一个用户只能使用到capacity划定的资源,无法触及max-capacity。在多用户的场景下,将该因子设置为1或更小的值将有助于限制单一用户获得多过的资源,导致其他用户无法提交作业,但是在单一用户的场景下,我们需要把扩大该值,如果想让一个用户有能力获取队列max-capacity规划的资源,可以将user-limit-factor设为:max-capacity除以capacity得到的比值。下图很准确地描述了user-limit-factor的作用:
6. 规整化因子
YARN在进行资源切分时会使用一套资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,如果应用程序申请的资源量小于最小可申请资源量,则YARN会将其大小改为最小可申请量,即应用程序获得资源不会小于最小可申请量;如果应用程序申请的资源量大于最大可申请资源量,则会抛出异常,无法申请成功;规整化因子是用来规整化应用程序资源的,应用程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值,公式为ceil(a/b)*b,其中a是应用程序申请的资源,b为规整化因子。对于不同的资源调度器其规整化因子的配置也不同,具体如下:
FIFO和Capacity Scheduler: 规整化因子等于最小可申请资源量(就是yarn.scheduler.minimum-allocation-mb和yarn.scheduler.minimum-allocation-vcores两个配置项),不可单独配置。
Fair Scheduler:规整化因子通过参数yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores设置,默认是1024和1。不过在Hadoop3.1.x 中这个2个参数已不推荐使用了,分别由 yarn.resource-types.memory-mb.increment-allocation 和 yarn.resource-types.vcores.increment-allocation替代。
因此,应用程序申请到的资源量可能大于申请的资源量,比如YARN的最小可申请资源内存量为1024,规整因子是1024,如果一个应用程序申请1500内存,则会得到2048内存,如果规整因子是512,则得到1536内存。
7. 测试计划
- 通过测试用例一,我们将了解Spark on Yarn在资源分配上的一些基本知识和影响因子
- 通过测试用例二,我们将了解user-limit-factor在单一用户场景下对提升资源利用率的作用
- 在测试用例三,为了准确观察资源分配状况,我们会关闭spark dynamic allocation,将resource-calculator改成DominantResourceCalculator,然后观察如何将队列CPU和内存的利用率拉满
- 通过测试用例四,我们在保证对列资源利用率拉满的前提下,尝试不同的容器数量,着重观察不同容器数量下作业的执行时长,以便找到作业的最大并行度配置。
7.1. 用例一
-
queue:queue-1
-
user-limit-factor: 1
-
num-executors: 3
-
executor-memory:1G
-
executor-cores: 40 ( Total: 3 * 40 = 120 (> 72) )
-
相关配置:
"yarn.scheduler.capacity.root.queues": "queue-1,queue-2",
"yarn.scheduler.capacity.root.queue-1.capacity": "25",
"yarn.scheduler.capacity.root.queue-1.maximum-capacity": "50",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels.CORE.capacity": "25",
"yarn.scheduler.capacity.root.queue-2.queues": "queue-2-1,queue-2-2",
"yarn.scheduler.capacity.root.queue-2.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels.CORE.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels.CORE.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.capacity": "67",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels.CORE.capacity": "67"
- 作业命令:
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--executor-memory 1g \\
--num-executors 3 \\
--executor-cores 40 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
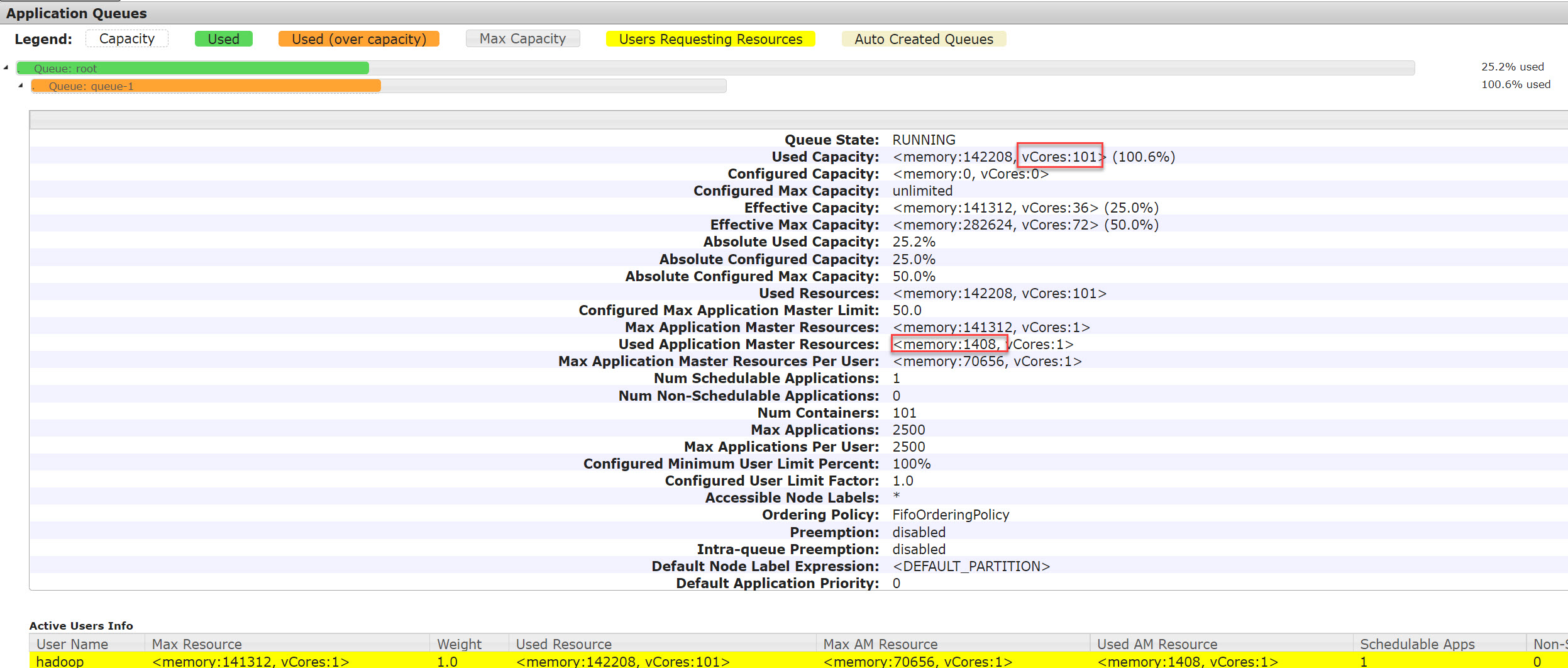
- 队列状态:
- 测试解读
作为第一个测试用例,我们要多花一些笔墨解读一些基本的数值。首先,Effective Capacity和Effective Max Capacity给出的是我们配置给队列的额定资源:36 - 72 core,141312 MB - 282624 MB,这个没有问题。而队列实际消耗的资源是Used Capacity: <memory:142208, vCores:101> (100.6%)则隐含了很多信息,需要深入解读。
首先,从我们的资源请求上看,我们计划申请3个executor,每个executor使用1G内存,40个核,则总的申请资源是:3 * 1024 = 3072 MB内存,3 * 40 + 1 = 121 Core,单独加的1是AM的Container,这与集群实际分配的资源大相径庭,以下是对比信息:
| 请求资源 | 实际分配资源 | |
|---|---|---|
| 内存 | 3 * 1024 = 3072 MB | 142208 MB |
| CPU | 3 * 40 + 1 = 121 Core | 101 Core |
求解这个资源分配的问题,我们得逐层拆解。首先,观察实际的资源分配,有两点是可以确定的:
- 总的内存分配接近设定的阈值(142208 vs. 141312)
- 单个container分配的资源是1 Core, 1408 MB,基中AM的容器资源在UI上直接显示了:
Used Application Master Resources: <memory:1408, vCores:1>,而142208 / 101 = 1408 MB也证明单个container内存就是1408 MB
那现在就有三个问题需要弄清楚:
- 为什么container的内存是1408 MB而不是spark命令行申请的1024 MB?
- Yarn的资源分配是以内存为基准划分的吗?还是以CPU或内存+CPU的综合权衡?这里起决定作用的因子是什么?怎样配置的?
- 明明只申请了3个container,不管是按内存还是按CPU,都不应该分配<memory:142208, vCores:101>这么多资源,背后的原因是什么呢?
首先解决第一个问题:为什么这个内存值是1408而不是1024?回答这个问题需要了解Spark on Yarn的内存模型,前面我们已经介绍了这部分的知识,简答地说,Spark Executor除了要申请指定的内存空间之外,还需要一部分overhead内存,大小由memoryOverHead因子乘以executor确定,若乘得的结果小于384 MB,取384 MB。
在该测试用例中,我们设定了spark.executor.memory=1g,而集群的spark.yarn.executor.memoryOverHead=0.187,故乘出的结果是191.488 MB,由于这个值小于384 MB,Spark会取384,而不是191,这样,1024 + 384 = 1408 MB,这就是1408 MB内存的来历了。
接下来是第二个问题:Yarn的资源分配是以内存为基准?还是CPU或多种维度综合作为基准进行分配的呢?从队列内存已接近最高阈值这一点来推测,可以大概率的判定出Yarn是以内存作为分配基准的,意思就是说Yarn只看分配的内存是否达到阈值来决定资源分配是否已经到位,而不会看CPU的核数。否则在这个测试中,就不会出现101核这样远超规定阈值的核数了。
那到底是什么样的配置决定了Yarn这一行为呢?它就是:
| 配置项 | 描述 |
|---|---|
| yarn.scheduler.capacity.resource-calculator | The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator only uses Memory while DominantResourceCalculator uses Dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. A Java ResourceCalculator class name is expected. |
由于我们的测试集群并没有显示地配置yarn.scheduler.capacity.resource-calculator,所以使用的就是默认的DefaultResourseCalculator了,如文档所言,它只看内存,不考虑其他因素!
最后是第三个问题:明明只申请了3个container,为什么出来的却是101个?很显然,101个是因为容器的总内存数达到了队列的上限,如果提升这个上限,容器数量还会继续上涨,所以问题在于为什么容器的分配没有在达到请求数量后停止而是向着队列的最大可用资源不停地申请下去了呢?
这一情况是由Spark的Dynamic Allocation引起的。简单地说,当队列中还有可用资源时,Dynamic Allocation会突破num-executors的限制,申请Yarn的当前队列中尽可能多的空闲资源给到Spark Application,同样的,当executor空闲一段时间后,它又会主动释放executor。
为了验证Dynamic Allocation的作用,我们特意关闭了它,方法是修改/etc/spark/conf/spark-defaults.conf文件,将其设为false:
spark.dynamicAllocation.enabled false
修改之后再次执行作业,得到的队列状态就变成了:
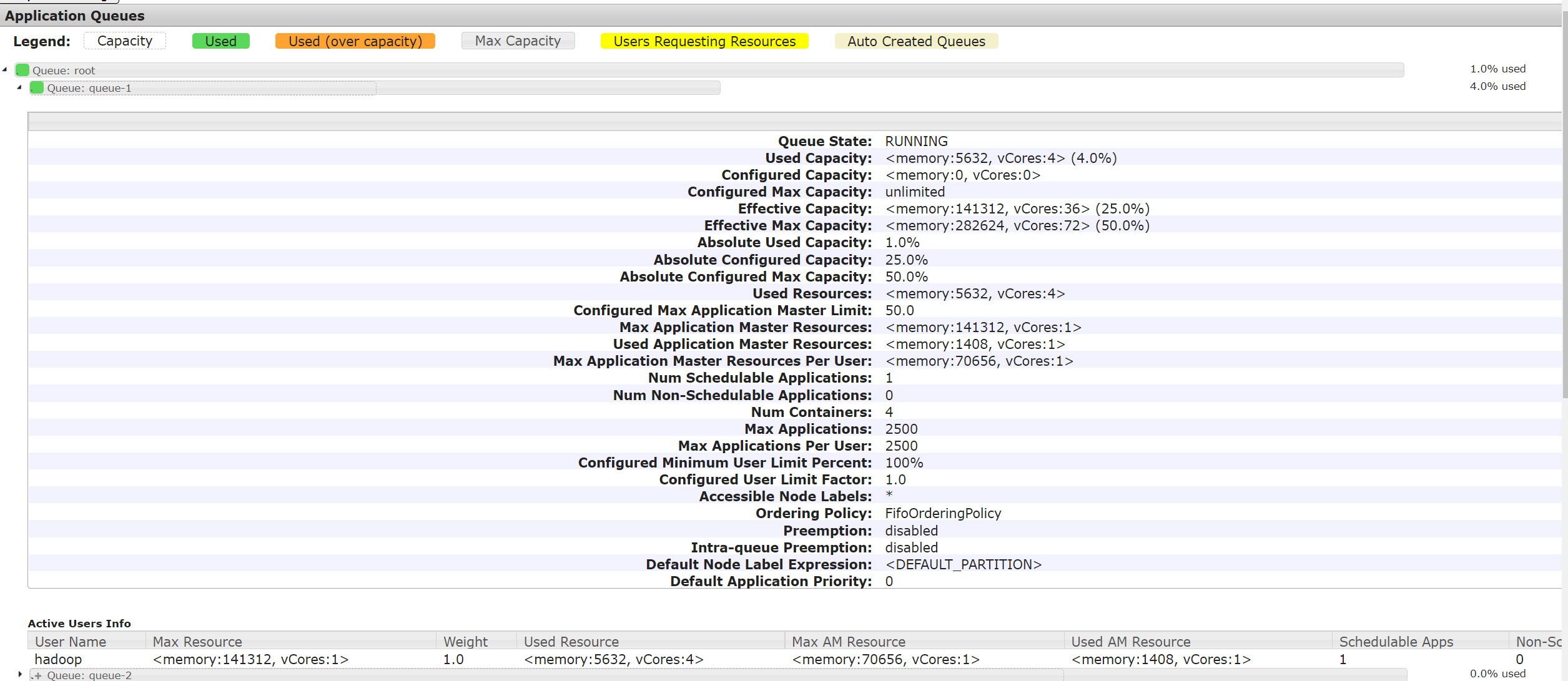
此时整个作业只分配了3个Container+1个AM Container=4个Container,与我们前面的推断完全一致。
除了上述三个问题,其实还有一个问题:为什么一个container只有一个core? 这个问题容易被总数101的vCores给掩盖掉,实际上101个vCore是101个container的,并不是3个executor,每个33上下,这个问题也是与请求完全不符的,我们留到测试二中去解释。
7.2. 用例二
通过测试用例一,我们了解了很多背景知识,但是用例一有一个“问题”:那就是它最大也只是达到了队列queue-1的额定capacity, 并没有达到max-capacity规定的集群50%的资源利用率上限,当时整个集群没有任何其他作业,所以不存在资源竞争,这是测试用例二要解决的。
此外,既然我们使用以内存为资源度量标准,为了简便有效的控制容器数量,我们在申请作业资源时,可以设置较大的数值,且不必关注其是否可以或需要那么多CPU,这只是为了便于测试,实际的应用还是需要根据作业自身的情况进行调整。
最后,在申请资源时,我们尽量通过请求的参数本身让队列资源饱和,避免Spark的Dynamic Allocation的影响,让测试参数和结果能比较直接的关联上。所以用例二的参数配置如下:
- queue:queue-1
- user-limit-factor: 2
- driver-memory:78G
- num-executors: 3
- executor-memory:78G
- executor-cores: 40 ( Total: 3 * 40 = 120 (> 72) )
- 相关配置:
"yarn.scheduler.capacity.root.queues": "queue-1,queue-2",
"yarn.scheduler.capacity.root.queue-1.capacity": "25",
"yarn.scheduler.capacity.root.queue-1.maximum-capacity": "50",
"yarn.scheduler.capacity.root.queue-1.user-limit-factor": "2",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels.CORE.capacity": "25",
"yarn.scheduler.capacity.root.queue-2.queues": "queue-2-1,queue-2-2",
"yarn.scheduler.capacity.root.queue-2.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels.CORE.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.user-limit-factor": "3",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels.CORE.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.capacity": "67",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels.CORE.capacity": "67",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.user-limit-factor": "1.49"
- 作业命令:
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 78g \\
--driver-cores 40\\
--executor-memory 78g \\
--num-executors 3 \\
--executor-cores 40 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
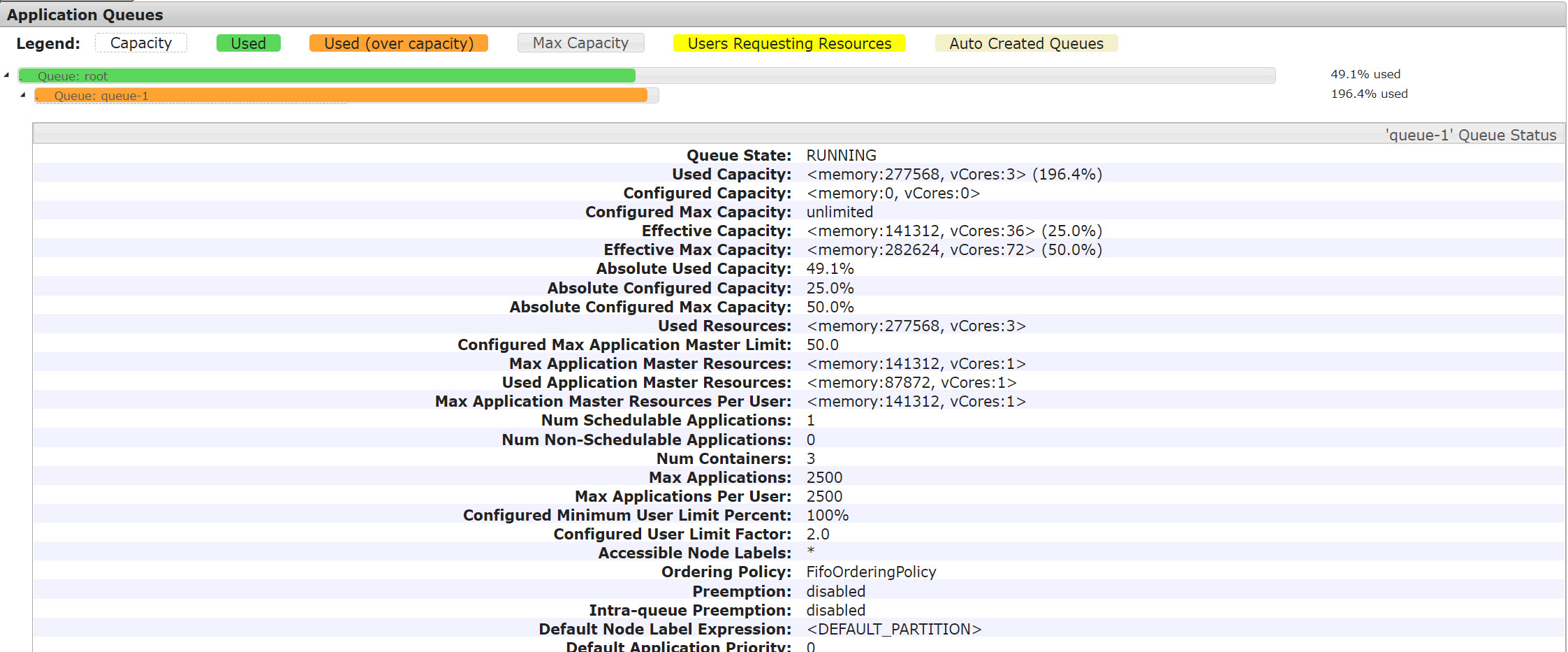
- 测试解读
从内存角度上看,200%的资源基本已全部获得(由于单一容器78G的内存值本身较大,在资源划分时不太可能刚刚正好是200%)。但是从CPU维度上,整个队列只有3个container,每个container只用了1个Core,其实这个数据是不准确的,从Spark UI上可以确定同一个stage是有多个task在并行的,即实际确实分配了多个核,这里的问题是由yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator引起的,这并不是DefaultResourceCalculator的bug,简单地说由于DefaultResourceCalculator只以内存作为基准进行计算,完全不考察CPU的情况,所以基于它统计的CPU信息也就只能是默认一个Container显示一个Core了,这里确实只是个UI的显示问题,并不是说在这一模式下一个Container就只能有一个Core,后面的测试用例我们将改用DominantResourceCalculator,避免产生不必要的误解。
但是整个作业只启动了3个container而不是3个executor container + 1个driver container = 4 个container是有原因的,原因就在于driver/executor的memory的取值:78G, 由于单一物理节点最大可用内存是184G,则184/2/1.1875=77.47, 即如果想在一个节点里放下两个container,container不得大于77.47,故而整个集群最多只能建出3个78G的container了。
7.3. 用例三
紧接用例二,我们先把resource-calculator改成DominantResourceCalculator,(注意:如果使用的是capacity scheduler,yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator必须配置在capacity-scheduler.xml中,而不是yarn-site.xml中),同时关闭spark dynamic allocation,然后重跑用例二,观察一下实际的cpu利用率。
此外,根据用例二一些不合理的地方,我们把过大的executor/driver内存降下来,确保根据内存划分容器时可以产出3+1容器。
- 相关配置
"spark.dynamicAllocation.enabled": "false"
"yarn.scheduler.capacity.resource-calculator": "org.apache.hadoop.yarn.util.resource.DominantResourceCalculator",
"yarn.scheduler.capacity.root.queues": "queue-1,queue-2",
"yarn.scheduler.capacity.root.queue-1.capacity": "25",
"yarn.scheduler.capacity.root.queue-1.maximum-capacity": "50",
"yarn.scheduler.capacity.root.queue-1.user-limit-factor": "2",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-1.accessible-node-labels.CORE.capacity": "25",
"yarn.scheduler.capacity.root.queue-2.queues": "queue-2-1,queue-2-2",
"yarn.scheduler.capacity.root.queue-2.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.accessible-node-labels.CORE.capacity": "75",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.user-limit-factor": "3",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-1.accessible-node-labels.CORE.capacity": "33",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.capacity": "67",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.maximum-capacity": "100",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels": "*",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.accessible-node-labels.CORE.capacity": "67",
"yarn.scheduler.capacity.root.queue-2.queue-2-2.user-limit-factor": "1.49"
- 作业命令:
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 75g \\
--num-executors 3 \\
--executor-cores 40 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000

解读:
只生成了两个container!除去AM, 实际只分配了一个executor的container,64G/40核。通过将executor-cores该为20再次运行得到3+1=4个容器,3*20 + 1 = 61核的对此测试可知是由于40 core的executor-cores过高,导致只能分配一个container,具体逻辑应该封装在了DominantResourceCalculator,我们不好直接推断。
在我们前面的所有测试用例中,始终有一个隐含的中心意图:就是想看一下在一个最粗粒度的container(就是在一个物理节点上只能建出一个的最大配置的container)配置下,应用程序所能占用的资源和执行效率如何。在我们当前的集群下(使用DominantResourceCalculator做resource-calculator,禁用Spark Dynamic Allocation),受分配策略的影响,当申请的内存与CPU越大(container的粒度越粗),可获得的container就越少, 但不管是单一容器40核,还是三个容器20*3=60核,作业的整体并行度都不高,队列中的CPU资源并没有被充分利用,换句话说就是:在容器内我们给到的资源已经非常富余了,对提升作业的整体吞吐量已经没有再多的帮助了,这时候我们需要把优化方向装向提升container/executor数量上去了。
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 5g \\
--num-executors 9 \\
--executor-cores 10 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
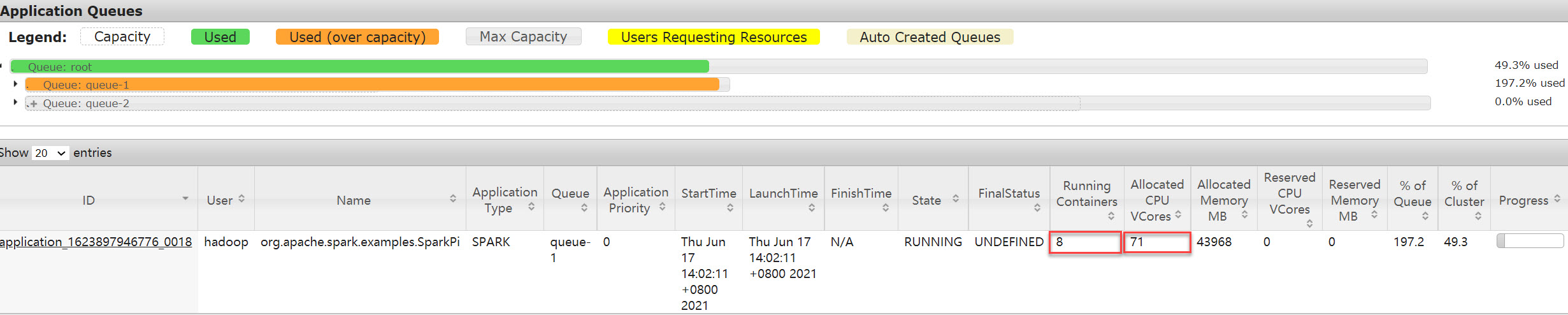
这套配置已经可以让作业获得最大的可用资源了,因为core已经触及到了queue-1的最大可用内核数了,所以申请的9个executors实际只拿到了7个,每个10个核。
7.4. 用例四
- 相关配置: 同用例三
(282624 - 1408) = 281216 / 1.1875 = 236813 MB
72 - 1 = 71 Cores
| 目标容器数量 | 最大队列资源下的单一executor饱和CPU与内存 | 执行耗时 |
|---|---|---|
| 7 | 10 core / 33830 MB | 127 S |
| 14 | 5 core / 16915 MB | 62 S |
| 35 | 2 core / 6766 MB | 34 S |
| 70 | 1 core / 3383 MB | 30 S |
7 container : 10 core / 33830 MB (由于规整化因子的原因,33830只能建6个container, 故实际改为33800)
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 33800m \\
--num-executors 7 \\
--executor-cores 10 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
用时:2分07秒
14 container : 5 core / 16915 MB
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 16915m \\
--num-executors 14 \\
--executor-cores 5 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
用时:62S
35 container : 2 core / 6766 MB
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 6766M \\
--num-executors 35 \\
--executor-cores 2 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
用时:34S
70 container : 1 core / 3383 MB
spark-submit --class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 1g \\
--driver-cores 1 \\
--executor-memory 3383M \\
--num-executors 70 \\
--executor-cores 1 \\
--queue queue-1 \\
/usr/lib/spark/examples/jars/spark-examples.jar \\
200000
用时:30S
8. 小结
- 在做资源调优或观察资源分配效果时,最好做如下两个配置,以便排除干扰,准确反映参数调整后的效果:
# spark-defaults.conf
"spark.dynamicAllocation.enabled": "false"
# yarn-site.xml
"yarn.scheduler.capacity.resource-calculator": "org.apache.hadoop.yarn.util.resource.DominantResourceCalculator"
-
在单一用户场景下,user-limit-factor是提升作业资源占用率的重要参数
-
Spark有一项spark.yarn.executor.memoryOverHead配置,一个Executor实际分配的内存是在executor-memory申请的数值之上再加executor-memory乘上该因子的部分,如果乘积不足384MB, 取384MB
-
在框定了作业可用的总资源下,或者是确定了作业内存与CPU的合适比例下,增加容器数量并成比例减少单一容器的CPU和内存,可以观察到作业并行度有明显差别,可通过多次尝试找到最合适的容器数量。(注:这是在关闭Spark Dynamic Allocation的前提下进行的)
参考文章:
关于作者:架构师,15年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,热衷函数式编程。对Hadoop/Spark 生态系统有深入和广泛的了解,参与过Hadoop商业发行版的开发,曾带领团队建设过数个完备的企业数据平台,个人技术博客:https://laurence.blog.csdn.net/ 作者著有《大数据平台架构与原型实现:数据中台建设实战》一书,该书已在京东和当当上线。

以上是关于关于Spark on Yarn的资源分配与Capacity Scheduler的研究的主要内容,如果未能解决你的问题,请参考以下文章