Spark On YARN内存和CPU分配
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark On YARN内存和CPU分配相关的知识,希望对你有一定的参考价值。
软件版本:
CDH:5.7.2,JDK:1.7;
问题描述:
在使用Spark On YARN时(无论是Client模式或者是Cluster模式,当然下面会有这种模式的对比区别),可以添加诸如:
[plain] view plain copy
–executor-memory 8G --executor-cores 5 --num-executors 20
等等这样的参数,但是这个和我们平常理解的感觉有误,或者说不直观,怎么说呢?
比如一个6节点(NodeManager)的集群,每个节点配置为:16 CPU核,64G内存,那么一般很容易提交代码的时候写成如下配置:
[plain] view plain copy
–num-executors 6 --executor-cores 15 --executor-memory 63G
但是这样配置后,你会发现,在8088端口的YARN监控上得到的不是你想得到的资源分配,那正确的配置应该是怎样的呢?
前备知识:
- YARN NodeManager资源
NodeManager所在的机器如果是16核、64G,那么设置如下参数(这两个参数是NodeManager能分配的最大内存和最大cpu):
[plain] view plain copy
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.cpu-vcores
***是小一点,比如设置内存为63G,核心为15,因为需要分配一些资源给系统以及后台Hadoop进程。当然,如果每个机器是6核,6G内存,那可以分配到5核以及5.5G内存左右;在原文中,说CDH机器可以自动的分配,不过我看到CDH集群设置这两个参数只是其能最大的值,也就是机器自身的资源。比如我的6核,6G内存,其配置如下:
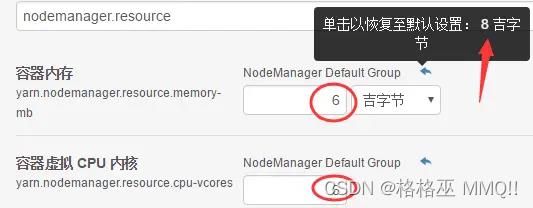
(当然,默认是8G内存,8核CPU的)
2. Spark On YARN Client 和Cluster
Spark提交任务首先由客户端(CLient)生成一个Spark Driver,Spark Driver在YARN的NOdeManager中生成一个ApplicationMaster,ApplicationMaster向YARN Resourcemanager申请资源(这些资源就是NodeManager封装的Container,其中包含内存和cpu),接着Spark Driver调度并运行任务;那么Client和CLuster过程如下:
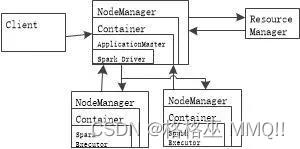
其中,左边是CLient模式,右边是Cluster模式,也就是说其实CLuster模式下,提交任务后,CLient可以离开了,而Client模式下,Client不可以离开;
另外,不管CLient或CLuster模式下,ApplicationMaster都会占用一个Container来运行;而Client模式下的Container默认有1G内存,1个cpu核,Cluster模式下则使用driver-memory和driver-cpu来指定;
但是这里有个问题,在Client模式下,这里的默认配置:
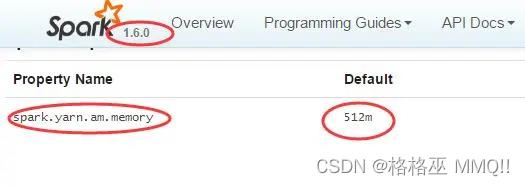
是512M的,但是参考博客里面说CDH里面这个默认是1G的(这里应该是1G的,不然的话,后面实验对应不到)
3. Spark On YARN资源申请
-
用户通过executor-memory设置内存;
-
经过spark.yarn.exeuctor.memoryOverhead的加持,申请的内存变为 executor-memory + max (384 , 0.1 * executor-memory) ;这里的384 和0.1(原文中这个值是0.07,这个需要注意)是参考下面的参数来的:

-
NodeManager在向上申请资源的时候会经过参数:
[plain] view plain copy
yarn.scheduler.minimum-allocation-mb // defalut 1G
yarn.scheduler.increment-allocation-mb // default 512M
的加持,向上取整为2中的倍数,并且最接近2中的数值。比如说–executor-memory是3G,那么2中的值就是3G+ max(384 , 0.1 *3 1024) = 3G + 384m ~ 3.5G ,所以NodeManager申请的资源应该就是3.5G(3584m),而不是3456m(31024+384)。
另外:
executor-cores其实是设置并行的个数的,由于HDFS的bug,executor-cores建议设置为5或以下;
实验及如何设置资源分配:
-
问题解答:
那么,回到最开始的问题,6个节点(NodeManager),每个64G内存,16核如果要使用尽可能多的集群资源,怎么分配: -
首先,去掉节点系统使用1G内存1核cpu,那么还剩63G内存,15核cpu;
-
加入executor-cpus设置为5,也就是建议值的最大,那么每个节点可以分配3个Container ,即 15 /5= 3 个Executor;
-
哪每个executor内存呢? 63/3 = 21G 内存,21G - max(384 ,0.1 *21G) = 18.9G ; 那么executor-memory应该设置为多少呢?这个值应该是18.5G,为什么是这个呢?
a. 第一,这个值需要是512M的倍数;
b,第二,xG + max(384m,0.1 * xG) < 21 G, 这个x 最大就是18.5G;
说道这里,需要说明一点,在参考的链接中参数0.1不是0.1,而是0.07,所以算的的executor-memory是19G,这个需要注意; -
那有多少个executor呢? 有人说这还不好算:6个节点 ,每个节点3executor,所以一共是18个;这个不对;
因为需要有一个container来部署ApplicationMaster,所以有个节点其资源就会减少,这也就是说在ApplicationMaster所在的节点上最多只能有2个executor,所以最终的参数是:
[plain] view plain copy
–num-executors 17 --executor-cores 5 --executor-memory 18944m
因为这个参数不能识别小数点,所以不能写成18.5G(注意这个值和原文中是不一样的,如果0.1参数在CDH集群中的默认值是0.07,那么就是原文的答案); -
5节点,6核cpu,6G内存怎么分配1
-
去掉节点系统内存512M,1核cpu;还剩5核cpu,5.5G内存;
-
如果每个executor的executor-cpus设置为5,那么也就是说每个节点有1个executor;
-
这样子的话,executor-memory就应该设置为5G , 5G + max(384, 0.1 * 5G ) = 5.5G ~ 5.5G ,这样子分配刚刚好;
-
executor就应该设置为4 ,因为其中一个NodeManager分配了ApplicationMaster,那么其就不能生成一个executor了;
启动参数为:
[plain] view plain copy
spark-shell --master yarn --deploy-mode client --executor-memory 5G --executor-cores 4 --num-executors 4 -
验证:
a. 首先看资源分配:

container个数5个?
这个怎么来的,明明申请了4个executor,每个executor对应一个container,那就是4个container,怎么会多一个呢?其实这个就是启动ApplicationMaster的container;
cpu核有17个?
4*4 = 16 ,另外一个当然就是启动ApplicationMaster的资源了;
内存23552m ?
4 *5 1024 = 20480,这不对呀,还差好多呢,那实际是怎么计算的呢?实际的计算方式应该是:
4 (5G + max(384m , 0.1 * 5G )) * 1024 + 1024 = 23552 ; 其中,最后一个加的就是启动ApplicationMaster默认的1G内存;
b. 看日志:
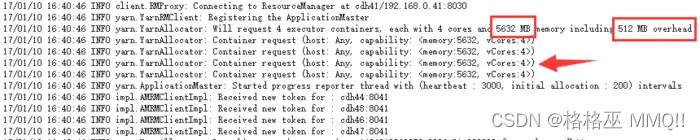
看日志其实这个过程就更加清晰了;
首先,可以看到4个container;其次内存是5632m = (5G + 0.1 5G ) 1024。
-
5节点,6核cpu,6G内存怎么分配2
除了2中的分配方式,有没有其他分配方式呢?如果每个executor-cpus是1呢? -
executor-cpus=1 ; 那么每个节点就可以分5个executor;
-
所以每个节点可以分 5.5G/ 5 = 1.1G ,所以最大只能1.1G,内存,而且NodeManager申请的资源只能是512M的整数倍,所以最大是1024M,那么executor-memory + max( 384, 0.1 * executor-memory) = 1024M ,那么executor-memory就等于640;
-
有多少个executor呢? 4 * 5 = 20 ,运行ApplicationMaster节点的有多少个呢,去掉ApplicationMaster的资源1G内存,1cpu还剩4.5G内存,4cpu核,申请4个executor是可以的,所以一共就有 4* 5 + 4 = 24个container;
参数:
[plain] view plain copy
spark-shell --master yarn --deploy-mode client --executor-memory 640m --executor-cores 2 --num-executors 24 -
验证:
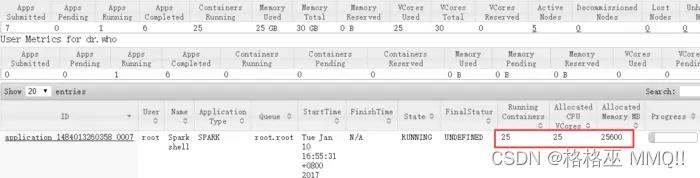
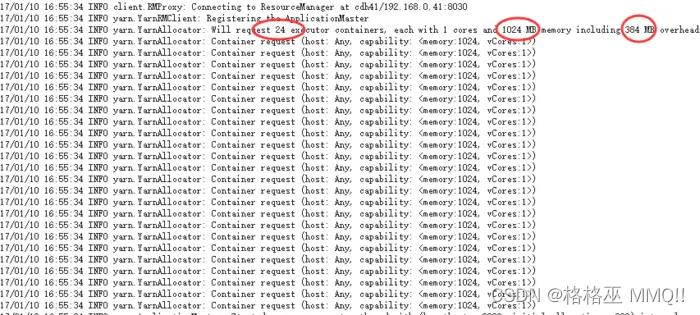
-
5节点,6核cpu,6G内存怎么分配3
除了2、3中的分配方式,有没有其他分配方式呢?如果每个executor-cpus是2呢? -
executor-cpus=2 ; 那么每个节点就可以分2个executor(5/2 ~ 2 ,只能往低约等于);
-
所以每个节点可以分 5.5G/ 2 = 2.75G ,所以最大只能2.75G,内存,而且NodeManager申请的资源只能是512M的整数倍,所以最大是2.5G,那么executor-memory + max( 384, 0.1 * executor-memory) ~ 2.5G ,那么executor-memory就等于2176;
-
有多少个executor呢? 4 * 2 = 8 ,运行ApplicationMaster节点的有多少个呢,去掉ApplicationMaster的资源1G内存,1cpu还剩4.5G内存,4cpu核,只能申请1个executor是可以的,所以一共就有 4* 2 + 1 = 9个container;
参数:
[plain] view plain copy
spark-shell --master yarn --deploy-mode client --executor-memory 2176m --executor-cores 2 --num-executors 9 -
验证:
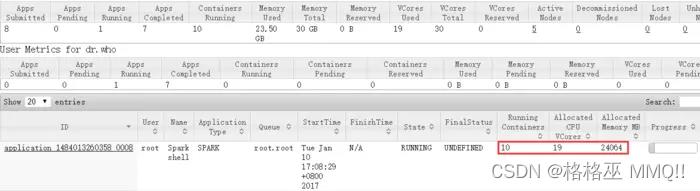

- 5节点,6核cpu,6G内存怎么分配4
但是,如果上一个分配中的第2中分配的内存是executor-memory + max( 384, 0.1 * executor-memory) ~ 2G, 那么executor-memory= 1664m;这个时候有多少个container呢?
运行ApplicationMaster的这时就可以运行2个executor了,所以一共有10个executor;
参数:
[plain] view plain copy
spark-shell --master yarn --deploy-mode client --executor-memory 1664m --executor-cores 2 --num-executors 10
验证:
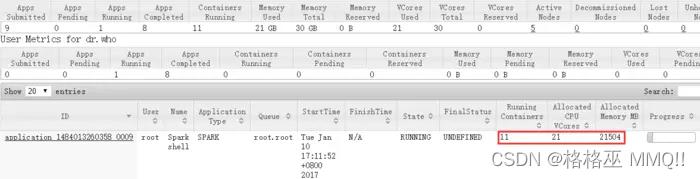

总结:
- Spark On YARN资源分配没有Spark StandAlone的那么明确,过程有点复杂;
以上是关于Spark On YARN内存和CPU分配的主要内容,如果未能解决你的问题,请参考以下文章