一场冠军两场Top,我的CCF比赛总结!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一场冠军两场Top,我的CCF比赛总结!相关的知识,希望对你有一定的参考价值。
本文是代码届的小白同学的分享,虽然刚入门学习,但已经有很多收获,希望能继续加油进步。
个人介绍
本人计算机专业研二在读,本科电子信息工程,由于疫情的原因,开学也晚了,很多都受到了影响,6月底七月初才开始学习机器学习的理论知识和深度学习的理论知识。
暑假两个月的学习过程中,感觉自己学的还行,就想找些比赛来看看,也是机缘巧合吧,看到Datawhale公众号和Coggle数据科学在介绍CCF的算法比赛,就抱着尝试的心情,选择了几个报名。

从0基础入门Kaggle,到天池再到后来的CCF比赛,短短的几个月对数据科学竞赛有了一定的了解,希望后序的比赛和明年的CCF比赛中可以拿到前排大奖。
这次CCF比赛一共参与了6个比赛,五个正式赛和一个训练赛。(理论学习终归是理论,从理论到实践还是有一段距离的,从比赛中你可以学习到很多东西,也可以帮助你把学到的知识充分利用一下,比赛真的可以帮助你快速成长,多参加比赛多与大佬交流,你会进步的更快!)
其中有四个结构化的比赛,有两个NLP方面的比赛,留个比赛自己真正全程参与的就3个,还有一个也花了一些时间,有两个比赛就点了参赛,但是没有提及结果。

女朋友是我不断上分的动力!
下面依次介绍一下自己全程参与的几个比赛吧,也总结一些从比赛中学到的知识。
室内用户运动时序数据分类
比赛地址:https://www.datafountain.cn/competitions/484
比赛类型:结构化、时序数据
这个赛题和队友的一起努力下,也取得了第一名的成绩,这个比赛我之前自己也写了一个baseline。
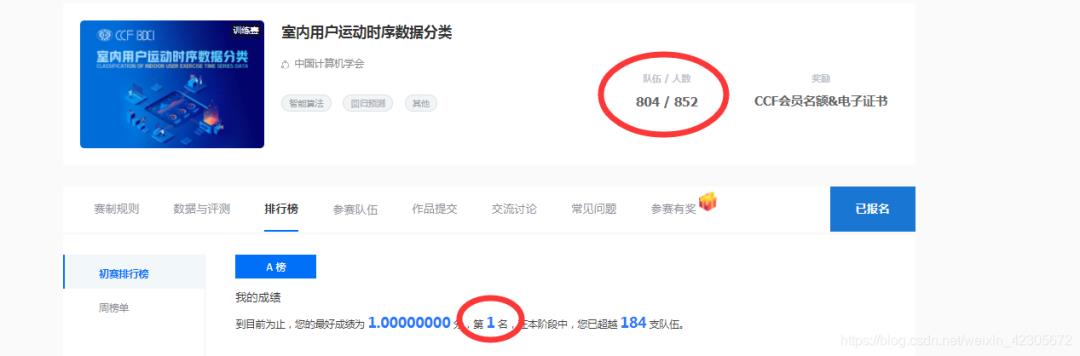
数据简介
基于上述实际需求以及深度学习的进展,本次训练赛旨在构建通用的时间序列分类算法。通过本赛题建立准确的时间序列分类模型,希望大家探索更为鲁棒的时序特征表述方法。
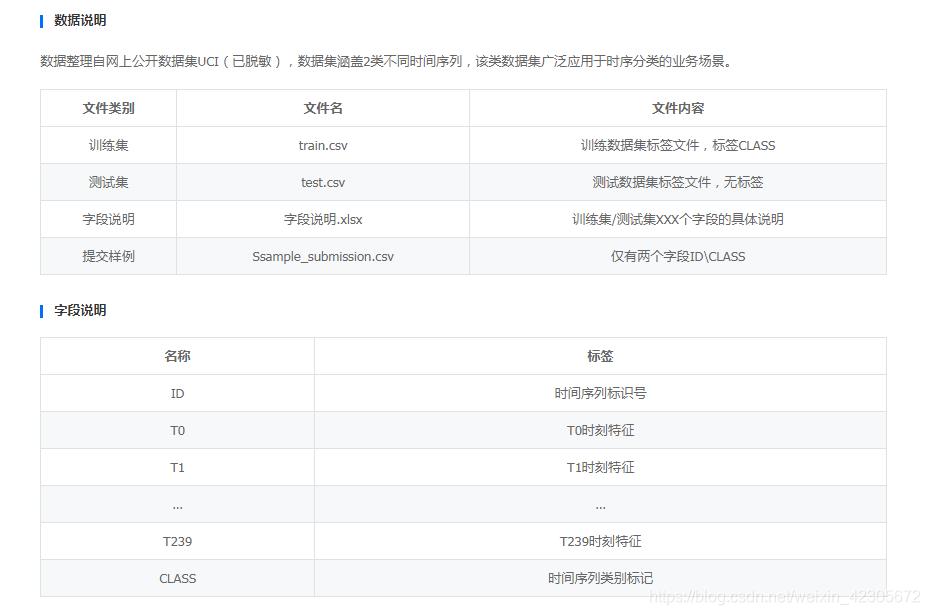
其实这个赛题是比较模糊的,没有给出很具体的说明,对于数据中的,一开始大家都是直接把数据丢到模型中去,然后直接提交结果就有一个不错的分数。
比赛收获
也是第一次接触这种时序类的题目,一开始也不知道如何下手,在队友分享的干货下,我们开始造特征,把造的特征加入到原来的数据中去,然后在一起训练,确实起到了不错的作用,分数提升的也是挺大的。
所以,如果当一个比赛给你的特征比较少,你要学会从给的数据中去挖掘新的特征,如下等等,一共造了30多新特征。
#统计特征
max_X=data.x.max()
min_X=data.x.min()
range_X=max_X-min_X
var_X=data.x.var()
std_X=data.x.std()
mean_X=data.x.mean()
median_X=data.x.median()
kurtosis_X=data.x.kurtosis()
skewness_X =data.x.skew()
Q25_X=data.x.quantile(q=0.25)
Q75_X=data.x.quantile(q=0.75)
#聚合特征
#差分值
max_diff1_x=data.x.diff(1).max()
min_diff1_x=data.x.diff(1).min()
range_diff1_x=max_diff1_x-min_diff1_x
var_diff1_x=data.x.diff(1).var()
std_diff1_x=data.x.diff(1).std()
mean_diff1_x=data.x.diff(1).mean()
median_diff1_x=data.x.diff(1).median()
kurtosis_diff1_x=data.x.diff(1).kurtosis()
skewness_diff1_x =data.x.diff(1).skew()
Q25_diff1_X=data.x.diff(1).quantile(q=0.25)
Q75_diff1_X=data.x.diff(1).quantile(q=0.75)另外从这个比赛中还学到了Stacking的融合方法,加上构造的新特征,然后使用这种融合方法,分数提升特别特别大,其他的比赛我不清楚,至少这个比赛是这样的!
企业非法集资风险预测
比赛地址:https://www.datafountain.cn/competitions/469
比赛类型:结构化、分类
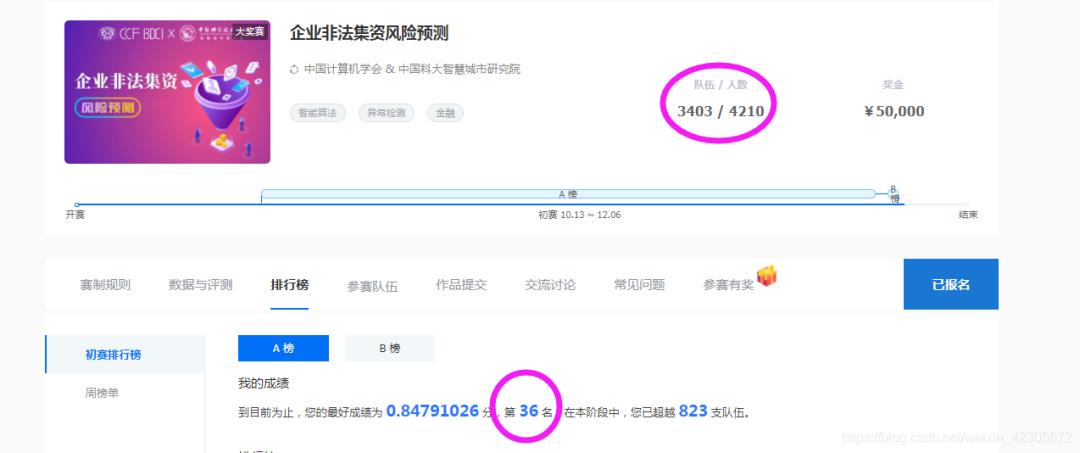
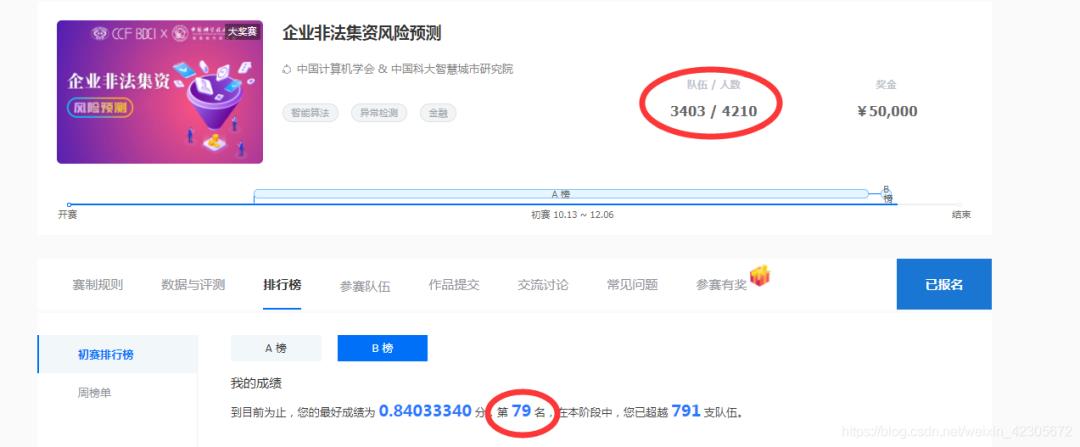
这个比赛官方给的数据还是比较多的,如何从多表中提取有用的特征是这个比赛的关键!
我之前也写了一个baseline分享,是在水哥的baseline基础改进的,最后排名A榜排名36,B榜79。整体还是不错的。
数据简介
该数据集包含约25000家企业数据,其中约15000家企业带标注数据作为训练集,剩余数据作为测试集。数据由企业基本信息、企业年报、企业纳税情况等组成,数据包括数值型、字符型、日期型等众多数据类型(已脱敏),部分字段内容在部分企业中有缺失,其中第一列id为企业唯一标识。
数据说明
这里以第一个表base_info.csv为例,包含数据集7和8中涉及到的所有企业的基本信息,每一行代表一个企业的基本数据,每一行有33列,其中id列为企业唯一标识,列之间采用“,”分隔符分割。
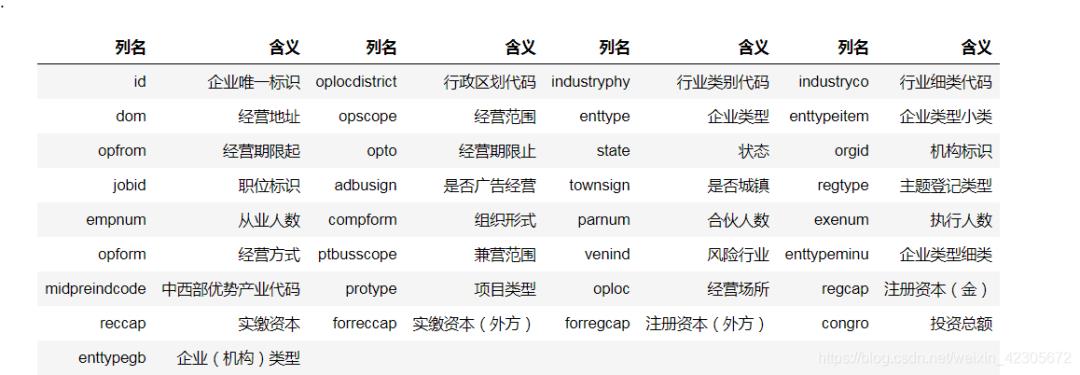
#读取数据
base_info = pd.read_csv(PATH + 'base_info.csv')
#输出数据shape和不重复企业id数
print(base_info.shape, base_info['id'].nunique())
#读取数据
base_info.head(1)
#查看缺失值,这里借助了missingno这个包,import missingno as msno。
msno.bar(base_info)#查看缺失值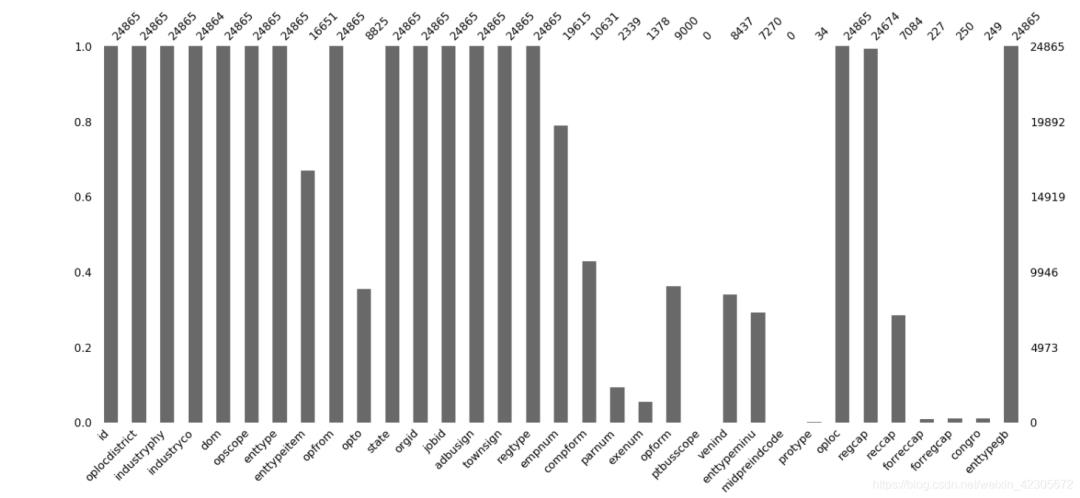
这个图就很明显的看出哪些数据存在缺失值,横轴是特征,纵轴的数据是非缺失值数,每个柱形的白色区域都代表缺失!
比赛收获
特征的选择与构造
这个比赛给的数据中,很多表是存在缺失值的,对于缺失值的处理,对于特征的选择与构造,特征交叉、分桶等,都需要有一定的了解,因为好的特征是进行下一步模型训练的基础。关于特征的处理可以参考我之前写的一篇文章。
#orgid 机构标识 oplocdistrict 行政区划代码 jobid 职位标识
base_info['district_FLAG1'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \\
base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG2'] = (base_info['orgid'].fillna('').apply(lambda x: str(x)[:6]) == \\
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
base_info['district_FLAG3'] = (base_info['oplocdistrict'].fillna('').apply(lambda x: str(x)[:6]) == \\
base_info['jobid'].fillna('').apply(lambda x: str(x)[:6])).astype(int)
#parnum 合伙人数 exenum 执行人数 empnum 从业人数
base_info['person_SUM'] = base_info[['empnum', 'parnum', 'exenum']].sum(1)
base_info['person_NULL_SUM'] = base_info[['empnum', 'parnum', 'exenum']].isnull().astype(int).sum(1)
base_info['opfrom'] = pd.to_datetime(base_info['opfrom'])#opfrom 经营期限起
base_info['opto'] = pd.to_datetime(base_info['opto'])#opto 经营期限止
base_info['opfrom_TONOW'] = (datetime.now() - base_info['opfrom']).dt.days
base_info['opfrom_TIME'] = (base_info['opto'] - base_info['opfrom']).dt.days
#opscope 经营范围
base_info['opscope_COUNT'] = base_info['opscope'].apply(lambda x: len(x.replace("\\t", ",").replace("\\n", ",").split('、')))
#对类别特征做处理
cat_col = ['oplocdistrict', 'industryphy', 'industryco', 'enttype',
'enttypeitem', 'enttypeminu', 'enttypegb',
'dom', 'oploc', 'opform','townsign']
#如果类别特征出现的次数小于10转为-1
for col in cat_col:
base_info[col + '_COUNT'] = base_info[col].map(base_info[col].value_counts())
col_idx = base_info[col].value_counts()
for idx in col_idx[col_idx < 10].index:
base_info[col] = base_info[col].replace(idx, -1)
base_info = base_info.drop(['opfrom', 'opto'], axis=1)#删除时间
for col in ['industryphy', 'dom', 'opform', 'oploc']:
base_info[col] = pd.factorize(base_info[col])[0]我自己在代码里把这些字段的含义都加上了,也便于自己理解这些含义,从而做一些处理,大家同样可以把这些含义加上。
模型的选择
关于模型的选择大家基本都是选择集成学习的几个比较火的模型,比如XGboost、Lightgbm和Catboost等。
这些单模在很多比赛中就有不错的成绩,如果将这些模型的结果融合可能效果会更好,当然有的比赛可能几个模型的效果存在差异性,而且这些集成学习的模型可以自动对缺失值的特征自行处理!
但是建议大家去学习一下这几个集成学习的理论知识,对你的后序的学习或者比赛都有很大的帮助。
面向数据治理的内容分类
比赛地址:https://www.datafountain.cn/competitions/471
比赛类型:自然语言处理、文本分类
这是一个NLP相关的比赛,说实话NLP的相关理论我看的不多,所以这个比赛也算是一个作为个人学习的入门比赛吧,我也没有使用到深度学习的方法,用的是传统的机器学习做的,实验室也没有条件做深度学习,对深度学习的这块模型也只是做了简单的了解。
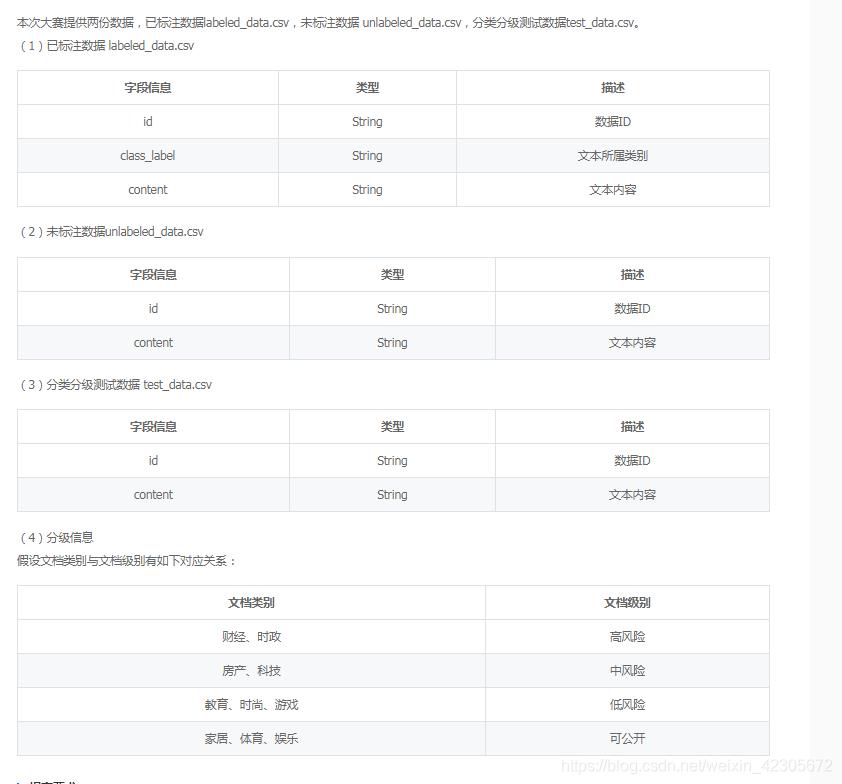
数据简介
已标注数据:共7000篇文档,类别包含7类,分别为:财经、房产、家居、教育、科技、时尚、时政,每一类包含1000篇文档。
未标注数据:共33000篇文档。
分类分级测试数据:共20000篇文档,包含10个类别:财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐、体育。
数据说明
这个比赛总体来说就是一个分类的任务,但是存在一个难点就是,官方只给了7个类别的训练集,但是需要你预测的是十个类别的,因此另外的三个类别就需要你自己给他们加上标签,然后在一起训练!
比赛收获
第一次接触NLP的知识,真的是小白一枚,很多理论知识也不是很了解,所以这个比赛也是投机取巧的方式吧,对文本类型的数据也学到了一些新的概念。
思路1:TF-IDF+机器学习分类器
直接使用TF-IDF对文本提取特征,使用分类器进行分类,分类器的选择上可以使用SVM、LR、XGboost等
思路2:FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建分类器
思路3:WordVec+深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRnn或者BiLSTM。
思路4:Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。
总结
第一次参加这种数据科学竞赛,收获也是蛮多的,在比赛中可以快速的成长,和其他同学交流,可以学到很多新的知识,有些内容可能只是在理论中看到过,但是并没有实际操作过。
通过竞赛可以学到更多理论中看不到的技巧和方法,第一次的CCF比赛圆满结束,转战其他的比赛吧,明年的CCF比赛我还会回来的!
# 竞赛交流群 邀请函 #

△长按添加竞赛小助手
添加Coggle小助手微信(ID : coggle666)
 干货学习,点赞三连↓
干货学习,点赞三连↓
以上是关于一场冠军两场Top,我的CCF比赛总结!的主要内容,如果未能解决你的问题,请参考以下文章