DSTC10开放领域对话评估比赛冠军方法总结
Posted 美团技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSTC10开放领域对话评估比赛冠军方法总结相关的知识,希望对你有一定的参考价值。
本文介绍了国际竞赛DSTC10开放领域对话评估赛道的冠军方法MME-CRS,该方法设计了多种评估指标,并利用相关性重归一化算法来集成不同指标的打分,为对话评估领域设计更有效的评估指标提供了参考。相关方法已同步发表在AAAI 2022 Workshop上。希望能给从事该技术领域工作的同学一些启发或帮助。
1 背景
对话系统技术挑战赛DSTC(The Dialog System Technology Challenge)由微软、卡内基梅隆大学的科学家于2013年发起,旨在带动学术与工业界在对话技术上的提升,在对话领域具有极高的权威性和知名度。对话系统挑战赛今年已举办至第十届(DSTC10),吸引了微软、亚马逊、卡内基梅隆大学、Facebook、三菱电子研究实验室、美团、百度等全球知名企业、顶尖大学和机构同台竞技。
DSTC10共包含5个Track,每个Track包含某一对话领域的数个子任务。其中Track5 Task1 Automatic Open-domain Dialogue Evaluation较为系统全面地将开放领域对话的自动评估任务引入DSTC10比赛中。开放领域对话自动评估是对话系统的重要组成部分,致力于自动化地给出符合人类直觉的对话质量评估结果。相比于速度慢、成本高的人工标注,自动化评估方法可以高效率、低成本地对不同对话系统进行打分,有力促进了对话系统的发展。
不同于任务型对话有一个固定的优化目标,开放领域对话更接近人类真实的对话,评估难度更大,因而吸引了广泛的关注。DSTC10 Track5 Task1比赛共包含14个验证数据集(共包含37种不同的对话评估维度)和5个测试数据集(共包含11个评估维度)。美团语音团队最终以平均0.3104的相关性取得了该比赛的第一名,该部分工作已完成一篇论文MME-CRS: Multi-Metric Evaluation Based on Correlation Re-Scaling for Evaluating Open-Domain Dialogue,并收录在AAAI2022 Workshop。

2 赛题简介
开放领域对话评估比赛收集了对话领域论文中的经典数据集,包括14个验证数据集(12个Turn-Level级别数据集和2个Dialog-Level级别数据集)和5个测试数据集。
数据集中的每个对话主要包含以下信息:
-
Context:对话中的提问,或者说对话的上下文。
-
Response:针对Context的回复,也即评估的具体对象;对话数据集中的Response一般由不同对话生成模型产生,如GPT-2和T5。
-
Reference:人工给出的针对Context的参考回答,一般为5条左右。
每个对话包含多个评估维度,如Context和Response的相关性,Response本身的流畅度等。每个数据集的评估维度不同,14个验证集总共包含37种不同的评估维度,具体包含Overall、Grammar、Relevance、Appropriateness、Interesting等。每个评估维度都有人工标注的打分,打分从1到5,分数越高表示当前评估维度的质量越高。
验证集和测试集的统计信息如图2和图3所示:
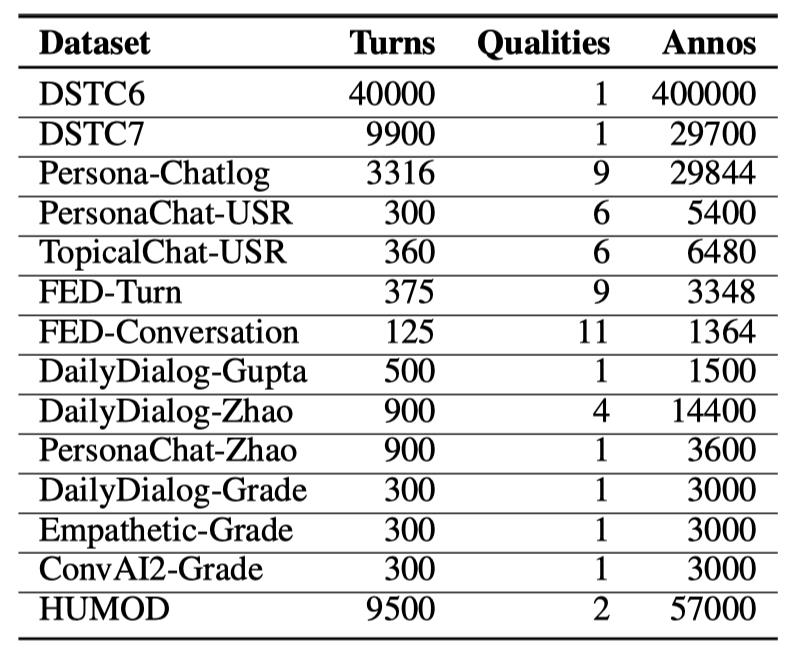

其中Turns表示对应数据集中的对话轮数;Qualities表示数据集中每个对话的评估维度,每个评估维度都有对应的人工标注打分;Annos表示每个数据集的标注量。
在该比赛中,每个数据集每个对话每个评估维度都有人工标注的打分,打分范围一般为1到5,一般求均值用于相关性计算。参赛队伍需要设计评估指标用于预测每个对话不同评估维度的打分。每个数据集的每个评估维度的预测打分会和人工标注的打分计算Spearman相关性,最后的比赛结果基于全部测试数据集的评估维度求均值。
3 现有方法和问题
3.1 现有方法
开放领域对话的自动评估方法主要分为三类。
Overlap-based方法
早期研究人员将对话系统中Reference和Response类比于机器翻译中的原句和翻译句,借鉴机器翻译的评价指标来评估对话质量。Overlap-based方法计算对话中Response和Reference之间的词重叠情况,词重叠越高打分越高。经典方法包括BLEU[1]和ROUGE[2]等,其中BLEU根据精确率衡量评估质量,而ROUGE根据召回率衡量质量。Response的评估依赖于给定的Reference,而开放领域下合适的Response是无限的,因此,Overlap-based方法并不适用于开放领域对话评估。
Embedding-based方法
随着词向量和预训练语言模型的快速发展,Embedding-based评估方法取得了不错的性能。基于深度模型分别编码Response和Reference,并基于二者的编码计算相关性打分。主要方法包括Greedy Matching[3]、Embedding Averaging[4]和BERTScore[5-6]等。Embedding-based方法相比Overlap-based方法有较大的提升,但是同样依赖于Reference,仍然存在较大的优化空间。
Learning-based方法
基于Reference的开放领域对话评估存在一个One-To-Many[7]困境:即开放领域对话合适的Response是无限的,但人为设计的Reference是有限的(一般为5条左右)。因此,基于对比Reference和Response的相似性(字面重叠或者语义相似)设计开放领域评估方法存在较大局限性。相比已有的Overlap-based方法和Embedding-based方法,ADEM方法[8]首次使用层次化的编码器来编码Context和Reference,并对输入的Response进行打分。ADEM方法基于模型打分和人工打分的均方误差来优化模型参数,期望逼近人类的打分。ADEM模型相比Overlap-based方法和Embedding-based方法取得了很大的成功,Learning-based方法也逐渐成为了开放领域自动化评估的主流方法。
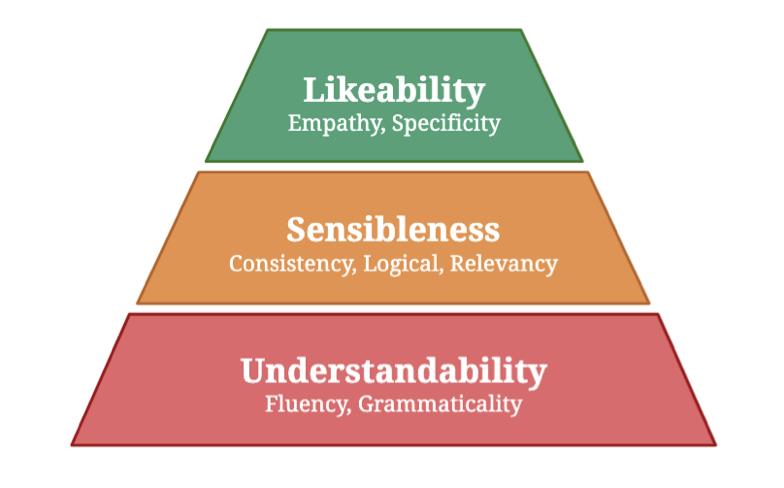
为了不断提高对话评估的准确和全面性,各种不同的评估维度层出不穷。为了应对越来越多评估维度带来的挑战,USL-H[9]将评估维度分为Understandability、Sensibleness和Likeability三类,如图4所示。USL-H针对性提出了VUP(Valid Utterance Prediction)、NUP(Next Utterance Prediction)和MLM(Mask Language Model)3种指标,分别衡量对话中:
-
Response是否通顺流畅。
-
Context和Respose的相关程度。
-
Response本身是否详细,更像人类等。
3.2 问题
现有的评估方法主要有以下问题:
设计的对话指标不够全面,难以综合衡量对话的质量
现有的自动评估方法主要聚焦在个别数据集的部分评估维度上。以当前较为全面的USL-H为例,该方法考虑了Response的流畅度、丰富度以及Context-Response句子对的相关性,但是USL-H忽略了:
-
更细粒度的Context-Response句子对的主题一致性。
-
回复者对当前对话的参与度。
实验证明,这些指标的遗漏严重影响了评估方法的性能。为了更全面稳定地评估多个对话数据集,设计考虑更多评估维度的指标势在必行。
缺乏有效的指标集成方法
现有方法大多倾向于为每种评估维度设计一种评估指标,这种思路面对越来越多的评估维度显得力不从心(考虑下比赛测试集共包含37种不同的评估维度)。每种对话维度的评估可能依赖数种评估指标,如Logical评估维度需要对话:1)Response流畅;2)Response和Context是相关的。设计基本的评估子指标,再通过合适的集成方法集成多个子指标打分,可以更全面有效表示不同的对话评估维度。
4 我们的方法
针对评估指标不够全面,本文设计了5类共7种评估指标(Multi-Metric Evaluation,MME)用于全面衡量对话的质量。基于设计的5类7种基础指标,我们进一步提出了相关性重归一化方法(Correlation Re-Scaling Method,CRS)来集成不同评估指标的打分。我们将提出的模型称为MME-CRS,模型整体架构图5所示:
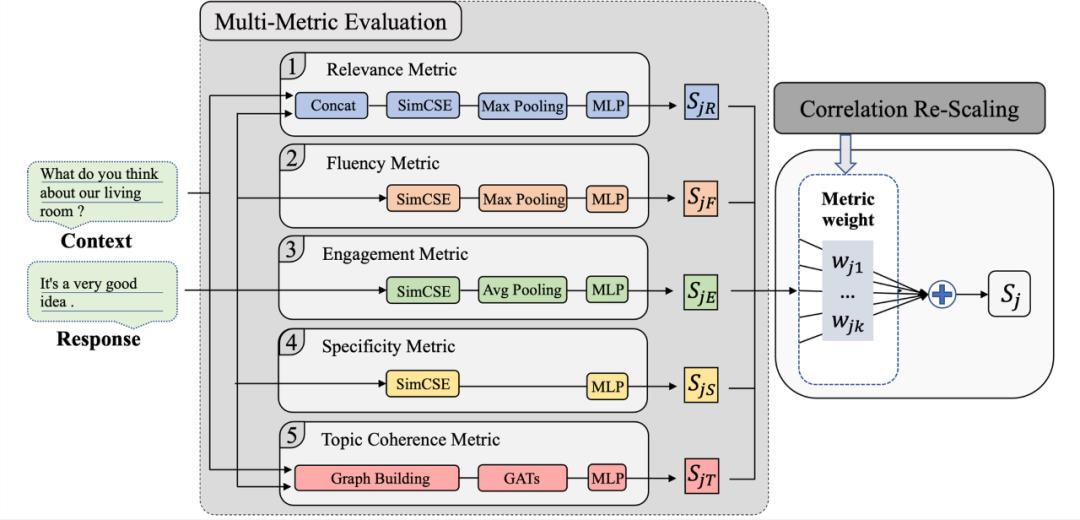
4.1 基础指标
为了解决现有方法的第一个问题,即设计的对话指标不够全面,我们在比赛中设计了5类共7种评估子指标。
4.1.1 Fluency Metric (FM)
目的:分析Response本身是否足够流畅可理解。
内容:首先基于Dailydialog数据集[10]构建response流畅度数据集,流程如下:
-
在Dailydialog数据集中随机选择一个Response,并以0.5概率决定r是正样本还是负样本。
-
如果样本r是正样本,随机选择一种调整:a.不调整;b.对每一个停用词,以0.5的概率删除。
-
如果样本r是负样本,随机选择一种调整:a.随机打乱词序;b.随机删除一定比例的词语;c.随机选择部分词语并重复。
基于上述规则构建流畅度数据集后,在预训练模型SimCSE模型[11]上微调。微调后的模型可以计算任一对话的Response流畅度打分,记为FM打分。
4.1.2 Relevance Metric (RM)
目的:分析Context和Response的相关程度。
内容:基于Dailydialog数据集构建Context-Response句子对形式的相关性数据集,其中句子对相关为正样本,不相关则为负样本。负样本的通常构建思路是将Response随机替换成其他对话的Response。PONE方法[12]指出随机挑选的Respose和Context基本不相关,模型训练收益很小。因此,这里的做法是随机选择10条Response,并计算和真实Response的语义相关度,并选择排名居中的句子作为伪样本。构造数据集后再在SimCSE模型上微调,微调后的模型可用于计算对话中Context和Response的相关度打分,记为RM打分。
4.1.3 Topic Coherence Metric (TCM)
目的:分析Context和Response的主题一致性。
内容:GRADE方法[13]构建了Context和Response的主题词级别的图表示,并计算了Context和Response的主题词级别的相关度。相比粗粒度的相关性指标,GRADE更加关注细粒度级别的主题相关程度,是相关性指标的有效补充。TCM指标借鉴GRADE方法。
具体流程如下:首先提取Context和Response中的关键词构建图,其中每个关键词都是一个节点,只有Context和Response的关键词之间存在边。基于ConceptNet获取每个节点的表示,再使用图注意力网络(GATs)聚集关键词邻居节点的信息并迭代每个节点的表示,最后综合全部节点的表示得到对话的图表示。在主题词级别的图表示上连接全连接层用于分类,微调后的模型即可用于计算对话的TCM打分。
4.1.4 Engagement Metric (EM)
目的:分析生成Response的人或对话模型有多大的意愿参与当前对话。
内容:前面提到的指标都是从Context和Response视角评估对话质量,而用户参与度则是基于用户的视角来评估。用户参与度打分一般是0~5,分数越大,表示用户参与当前对话的兴趣越大。我们将ConvAI数据集[10]的参与度打分从1~5缩放到0~1,作为参与度打分数据集。预训练模型仍然使用SimCSE,用于预测对话的参与度打分。预训练后的模型可用于预测对话的用户参与度打分,记为EM。
4.1.5 Specificity Metric (SM)
目的:分析Response本身是否足够细节。
内容:SM指标用于避免Response模棱两可,缺乏信息量。
具体做法如下:序列Mask掉Response中的每一个Token,并基于SimCSE模型的MLM任务计算Negative Log-Likelihood损失,得到的打分称为SM-NLL。替换损失函数为Negative Cross-Entropy和Perplexity可以分别得到SM-NCE和SM-PPL打分,共3个SM指标打分。3个SM指标打分都需要分别归一化到0和1之间。
4.2 集成方法CRS
集成不同评估指标的打分是提高自动化对话评估效果的有效手段。
对每一个待评估的对话,基于上述5类7种基础指标可以得到7种不同的打分。对于待评估数据集的某个评估维度,需要综合7种指标打分得到一个综合打分,用于和人类打分计算相关性。我们的集成方法分为以下两步。
4.2.1 不同评估维度权重分布的计算
首先,计算验证集上每个数据集每个评估维度7种评估指标的相关性打分,相关性打分越大,认为该指标对该评估维度越重要。对越重要的评估指标赋予一个更大的权重,并将得到的权重在指标维度重新归一化,这样则得到了每个数据集每个评估维度上不同评估指标的权重分布:
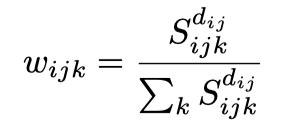
其中是第个数据集第个评估维度上第个评估指标的相关性打分,是相关性打分的幂数,越大则相关性打分越高的指标的权重就越大。一般当max()在1/3到1/2之间时集成效果最好,这是计算的一种简单有效手段。实验中,将设置为常数可以获得更好的泛化效果,我们将设置为2,并在验证集上计算权重分布,再迁移到测试集上,取得了比赛最优性能。
在数据集维度,将不同数据集中相同评估维度的权重求均值,得到每个评估维度在不同评估指标上的权重分布:
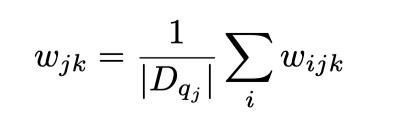
注意这里得到的权重分布已经和具体数据集无关,可以将权重分布迁移到测试集上。
4.2.2 计算指标打分的加权和
对每个测试集的每个评估维度,计算7种指标打分并基于第一步的权重求加权和,得到综合打分:
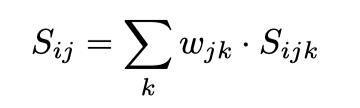
加权得到的综合打分和人工打分计算相关性,得到每种评估维度上的模型打分和人工打分的相关性打分。
我们的集成方法基于指标的相关性打分赋予权重并重新归一化,所以将该集成方法称为相关性重归一化方法。在得到的MME指标上使用CRS集成方法,可得MME-CRS评估算法。
5 实验分析
5.1 实验结果
我们的方法主要基于Dailydialog数据集预训练(除了EM子指标是使用ConvAI2数据集),在比赛验证集上计算集成方法的权重分布,最终在测试集上取得了0.3104的Spearman相关性打分。
图6展示了比赛基准模型Deep AM-FM[14]以及比赛Top5队伍在测试集上不同数据集评估维度的性能。本文的方法以0.3104的平均Spearman相关性系数取得了第一,且在5个数据集全部11个评估维度中的6个取得了第一,证明了本文方法的优越性能。

为了方便展示,图中方法采用了数据集-评估维度的展示方式。其中J、E、N、DT、DP分别表示JSALT、ESL、NCM、DST10-Topical、DSTC10-Persona数据集,而A、C、G、R分别表示Appropriateness、Content、Grammar、Relevance评估维度。我们对每个评估维度上最好的性能进行了加粗。
5.2 消融实验
在消融实验部分,我们以本文方法MME-CRS评估为基准,在集成阶段分别去除FM、RM、TCM、EM、SM、RM+TCM指标,对比不同指标在集成过程中的重要性。实验性能如图7所示:
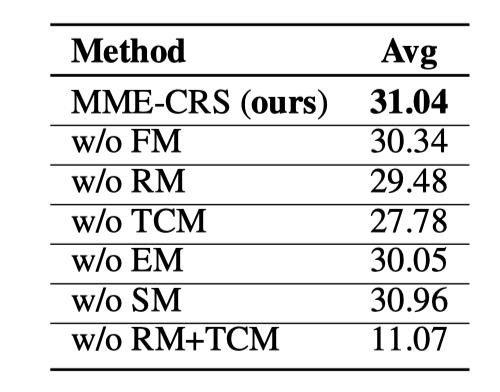
相关性指标RM和主题一致性指标TCM都使用了对话中的Context和Response信息,因此在实验中同时去除这两个指标,观察对性能的影响。从图7中的实验结果可以看出:
-
TCM、RM和EM对于模型性能的贡献最大,打分集成阶段删除这三个评估指标后,测试集上的平均Spearman相关性打分分别降低了3.26%、1.56%和1.01%。
-
粗粒度的RM指标和细粒度的TCM指标是有益的互相补充。如果分别去除RM或TCM指标,性能会有稍微下降;如果同时去除RM和TCM指标,评估方法缺乏了Context相关的信息,性能会大幅降低到11.07%。
-
SM指标在测试集上的提升基本可以忽略。我们分析原因是:测试集中用于生成Response的各个生成模型在测试集语料上过拟合较为严重,因此生成了很多非常详细,但和Context不相关的Response。因此SM指标的优劣对于测试集质量的评估基本没有作用。
5.3 CRS效果
为了分析集成算法CRS的作用,本文对比了MME-CRS和MME-Avg(将MME多个指标打分简单平均)两个评估方法的性能,如图8所示:

从图中可以看出,MME-CRS方法相比于MME-Avg高了3.49%,证明了CRS算法在集成子指标打分方面的优越性能。
6 总结
在本次比赛中,我们总结了开放领域对话自动评估存在的两个主要问题,即评估指标不够全面和缺乏有效的指标集成方法。针对评估指标不够全面的问题,本文设计了5类7种评估指标用于全面衡量对话的质量;基于7种基础指标,提出了相关性重归一化方法来计算每种对话评估维度的集成打分。
虽然本文方法在DSTC10比赛中取得了较好的成绩,但后续我们将继续探索其他更有效的评估指标和指标集成方法。我们正在尝试将比赛中的技术应用到美团具体业务中,如语音交互中心的智能外呼机器人、智能营销和智能客服中,在多个不同维度评估机器、人工客服与用户的对话质量,不断优化对话效果,提升用户的满意度。
参考文献
[1] Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318.
[2] Lin C Y. Rouge: A package for automatic evaluation of summaries[C]//Text summarization branches out. 2004: 74-81.
[3] Rus, V.; and Lintean, M. 2012. An optimal assessment of natural language student input using word-to-word similarity metrics. In International Conference on Intelligent Tutoring Systems, 675–676. Springer.
[4] Wieting, J.; Bansal, M.; Gimpel, K.; and Livescu, K. 2016. Towards universal paraphrastic sentence embeddings. In 4th International Conference on Learning Representations.
[5] Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K. Q.; and Artzi, Y. 2019. BERTScore: Evaluating text generation with BERT. In International Conference on Learning Representations.
[6] Liu C W, Lowe R, Serban I V, et al. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016: 2122-2132.
[7] Zhao, T.; Zhao, R.; and Eskenazi, M. 2017. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 654–664.
[8] Lowe R, Noseworthy M, Serban I V, et al. Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017: 1116-1126.
[9] Phy, V.; Zhao, Y.; and Aizawa, A. 2020. Deconstruct to reconstruct a configurable evaluation metric for open-domain dialogue systems. In Proceedings of the 28th International Conference on Computational Linguistics, 4164–4178.
[10] Zhao, T.; Lala, D.; and Kawahara, T. 2020. Designing precise and robust dialogue response evaluators. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 26–33.
[11] Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[J]. arXiv preprint arXiv:2104.08821, 2021.
[12] Lan, T.; Mao, X.-L.; Wei, W.; Gao, X.; and Huang, H. 2020. Pone: A novel automatic evaluation metric for open-domain generative dialogue systems. ACM Transactions on Information Systems (TOIS), 39(1): 1–37.
[13] Huang, L.; Ye, Z.; Qin, J.; Lin, L.; and Liang, X. 2020. Grade: Automatic graph-enhanced coherence metric for evaluating open-domain dialogue systems. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 9230–9240.
[14] Zhang, C.; D’Haro, L. F.; Banchs, R. E.; Friedrichs, T.; and Li, H. 2021. Deep AM-FM: Toolkit for automatic dialogue evaluation. In Conversational Dialogue Systems for the Next Decade, 53–69. Springer.
作者简介
鹏飞、晓慧、凯东、汪建、春阳等,均为美团平台/语音交互部工程师。
---------- END ----------
招聘信息
美团语音交互部负责美团语音和智能交互技术及产品研发,面向美团业务和生态伙伴,提供语音和口语数据的大规模处理及智能响应能力。团队在语音识别、合成、口语理解、智能问答和多轮交互等技术上已建成大规模的技术平台服务,研发包括外呼机器人、智能客服、语音交互平台等解决方案和产品并广泛落地。我们长期招聘志同道合的伙伴,感兴趣的同学可以将简历发送至:yuanchunyang@meituan.com(邮件主题:美团平台语音交互部)
美团科研合作
美团科研合作致力于搭建美团各部门与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕人工智能、大数据、物联网、无人驾驶、运筹优化、数字经济、公共事务等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com 。
也许你还想看
阅读更多
---
以上是关于DSTC10开放领域对话评估比赛冠军方法总结的主要内容,如果未能解决你的问题,请参考以下文章
WMT 2022国际机器翻译大赛发榜,微信翻译斩获三项任务冠军
阿里云ACE X 阿里云IoT-HaaS物联网设备云端一体极客大赛“总决赛冠军” 无一战队比赛总结