睿智的目标检测57——Tensorflow2 搭建YoloV5目标检测平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了睿智的目标检测57——Tensorflow2 搭建YoloV5目标检测平台相关的知识,希望对你有一定的参考价值。
睿智的目标检测57——Tensorflow2 搭建YoloV5目标检测平台
学习前言
这个很久都没有学,最终还是决定看看,复现的是YoloV5的第5版,V5有好多版本在,作者也一直在更新,我选了这个时间的倒数第二个版本。

源码下载
https://github.com/bubbliiiing/yolov5-tf2
喜欢的可以点个star噢。
YoloV5改进的部分(不完全)
1、主干部分:使用了Focus网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。该结构在YoloV5第5版之前有所应用,最新版本中未使用。
2、数据增强:Mosaic数据增强、Mosaic利用了四张图片进行拼接实现数据中增强,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!
3、多正样本匹配:在之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV5中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。
以上并非全部的改进部分,还存在一些其它的改进,这里只列出来了一些我比较感兴趣,而且非常有效的改进。
YoloV5实现思路
一、整体结构解析
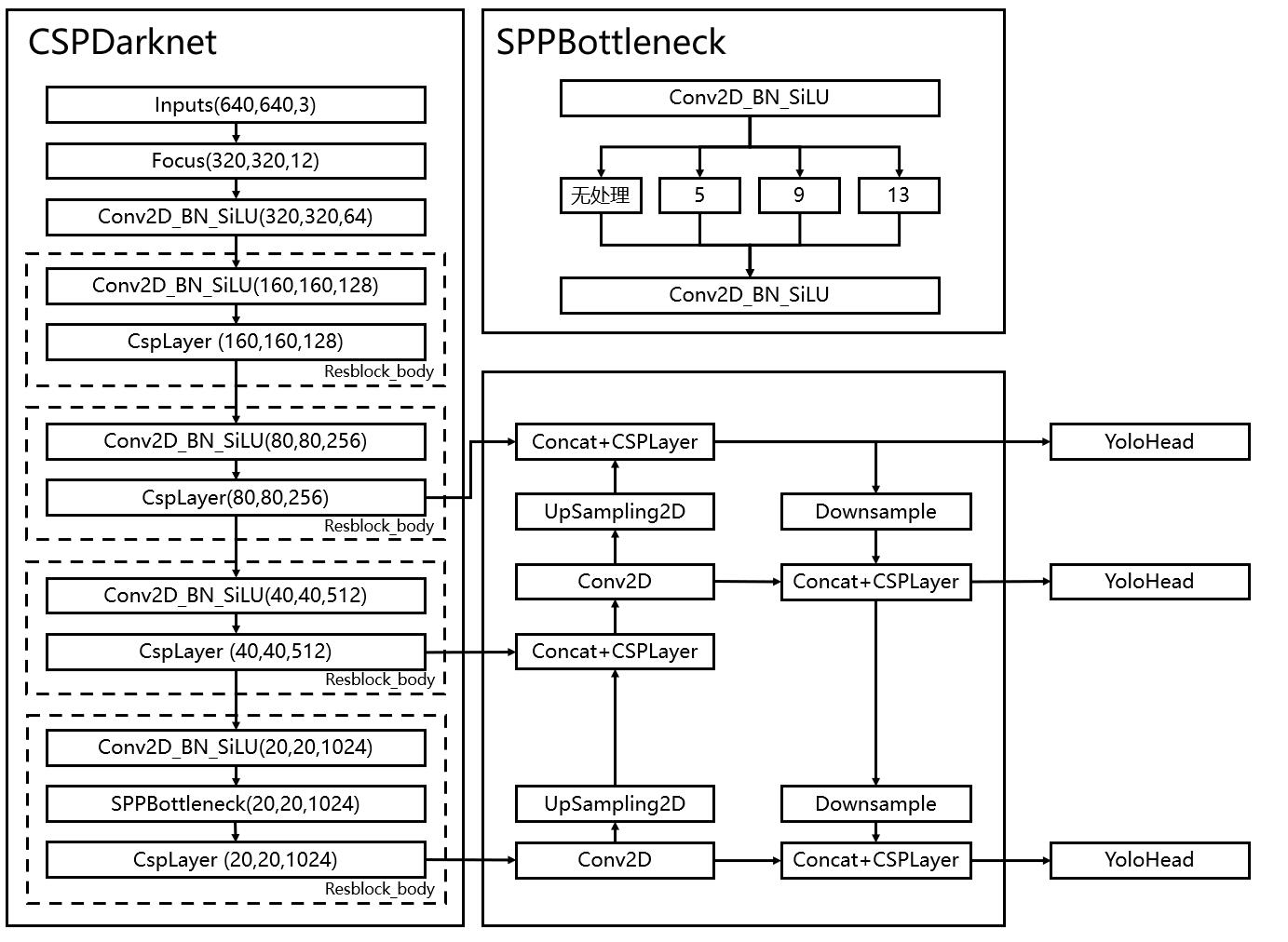
在学习YoloV5之前,我们需要对YoloV5所作的工作有一定的了解,这有助于我们后面去了解网络的细节。
和之前版本的Yolo类似,整个YoloV5可以依然可以分为三个部分,分别是Backbone,FPN以及Yolo Head。
Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN可以被称作YoloV5的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是YoloV5的分类器与回归器,通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV5网络所作的工作就是 特征提取-特征加强-预测特征点对应的物体情况。
二、网络结构解析
1、主干网络Backbone介绍
YoloV5所使用的主干特征提取网络为CSPDarknet,它具有五个重要特点:
1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV5的主干部分都由残差卷积构成:
def Bottleneck(x, out_channels, shortcut=True, name = ""):
y = compose(
DarknetConv2D_BN_SiLU(out_channels, (1, 1), name = name + '.cv1'),
DarknetConv2D_BN_SiLU(out_channels, (3, 3), name = name + '.cv2'))(x)
if shortcut:
y = Add()([x, y])
return y

残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2、使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。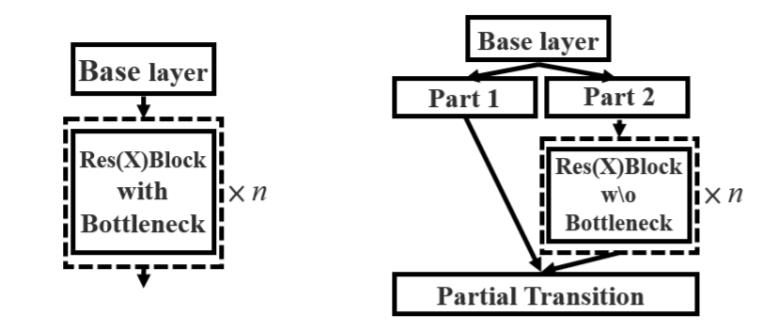
def C3(x, num_filters, num_blocks, shortcut=True, expansion=0.5, name=""):
hidden_channels = int(num_filters * expansion) # hidden channels
#----------------------------------------------------------------#
# 主干部分会对num_blocks进行循环,循环内部是残差结构。
#----------------------------------------------------------------#
x_1 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), name = name + '.cv1')(x)
#--------------------------------------------------------------------#
# 然后建立一个大的残差边shortconv、这个大残差边绕过了很多的残差结构
#--------------------------------------------------------------------#
x_2 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), name = name + '.cv2')(x)
for i in range(num_blocks):
x_1 = Bottleneck(x_1, hidden_channels, shortcut=shortcut, name = name + '.m.' + str(i))
#----------------------------------------------------------------#
# 将大残差边再堆叠回来
#----------------------------------------------------------------#
route = Concatenate()([x_1, x_2])
#----------------------------------------------------------------#
# 最后对通道数进行整合
#----------------------------------------------------------------#
return DarknetConv2D_BN_SiLU(num_filters, (1, 1), name = name + '.cv3')(route)
3、使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,下图很好的展示了Focus结构,一看就能明白。
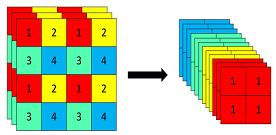
class Focus(Layer):
def __init__(self):
super(Focus, self).__init__()
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] // 2 if input_shape[1] != None else input_shape[1], input_shape[2] // 2 if input_shape[2] != None else input_shape[2], input_shape[3] * 4)
def call(self, x):
return tf.concat(
[x[..., ::2, ::2, :],
x[..., 1::2, ::2, :],
x[..., ::2, 1::2, :],
x[..., 1::2, 1::2, :]],
axis=-1
)
4、使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。
f
(
x
)
=
x
⋅
sigmoid
(
x
)
f(x) = x · \\textsigmoid(x)
f(x)=x⋅sigmoid(x)

class SiLU(Layer):
def __init__(self, **kwargs):
super(SiLU, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.sigmoid(inputs)
def get_config(self):
config = super(SiLU, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
5、使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。
def SPPBottleneck(x, out_channels, name = ""):
#---------------------------------------------------#
# 使用了SPP结构,即不同尺度的最大池化后堆叠。
#---------------------------------------------------#
x = DarknetConv2D_BN_SiLU(out_channels // 2, (1, 1), name = name + '.cv1')(x)
maxpool1 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(x)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(x)
maxpool3 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(x)
x = Concatenate()([x, maxpool1, maxpool2, maxpool3])
x = DarknetConv2D_BN_SiLU(out_channels, (1, 1), name = name + '.cv2')(x)
return x
整个主干实现代码为:
from functools import wraps
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Add, BatchNormalization, Concatenate,
Conv2D, Layer, MaxPooling2D,
ZeroPadding2D)
from tensorflow.keras.regularizers import l2
from utils.utils import compose
class SiLU(Layer):
def __init__(self, **kwargs):
super(SiLU, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.sigmoid(inputs)
def get_config(self):
config = super(SiLU, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
class Focus(Layer):
def __init__(self):
super(Focus, self).__init__()
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] // 2 if input_shape[1] != None else input_shape[1], input_shape[2] // 2 if input_shape[2] != None else input_shape[2], input_shape[3] * 4)
def call(self, x):
return tf.concat(
[x[..., ::2, ::2, :],
x[..., 1::2, ::2, :],
x[..., ::2, 1::2, :],
x[..., 1::2, 1::2, :]],
axis=-1
)
#------------------------------------------------------#
# 单次卷积DarknetConv2D
# 如果步长为2则自己设定padding方式。
#------------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = 'kernel_initializer' : RandomNormal(stddev=0.02), 'kernel_regularizer' : l2(kwargs.get('weight_decay', 5e-4))
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2, 2) else 'same'
try:
del kwargs['weight_decay']
except:
pass
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块 -> 卷积 + 标准化 + 激活函数
# DarknetConv2D + BatchNormalization + SiLU
#---------------------------------------------------#
def DarknetConv2D_BN_SiLU(*args, **kwargs):
no_bias_kwargs = 'use_bias': False
no_bias_kwargs.update(kwargs)
if "name" in kwargs.keys():
no_bias_kwargs['name'] = kwargs['name'] + '.conv'
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(momentum = 0.97, epsilon = 0.001, name = kwargs['name'] + '.bn'),
SiLU())
def Bottleneck(x, out_channels, shortcut=True, weight_decay=5e-4, name = ""):
y = compose(
DarknetConv2D_BN_SiLU(out_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv1'),
DarknetConv2D_BN_SiLU(out_channels, (3, 3), weight_decay=weight_decay, name = name + '.cv2'))(x)
if shortcut:
y = Add()([x, y])
return y
def C3(x, num_filters, num_blocks, shortcut=True, expansion=0.5, weight_decay=5e-4, name=""):
hidden_channels = int(num_filters * expansion)
#----------------------------------------------------------------#
# 主干部分会对num_blocks进行循环,循环内部是残差结构。
#----------------------------------------------------------------#
x_1 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
#--------------------------------------------------------------------#
# 然后建立一个大的残差边shortconv、这个大残差边绕过了很多的残差结构
#--------------------------------------------------------------------#
x_2 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
for i in range(num_blocks):
x_1 = Bottleneck(x_1, hidden_channels, shortcut=shortcut, weight_decay=weight_decay, name = name + '.m.' + str(i))
#----------------------------------------------------------------#
# 将大残差边再堆叠回来
#----------------------------------------------------------------#
route = Concatenate()([x_1, x_2])
#----------------------------------------------------------------#
# 最后对通道数进行整合
#----------------------------------------------------------------#
return DarknetConv2D_BN_SiLU(num_filters, (1, 1), weight_decay=weight_decay, name = name + '.cv3')(route)
def SPPBottleneck(x, out_channels, weight_decay=5e-4, name = ""):
#---------------------------------------------------#
# 使用了SPP结构,即不同尺度的最大池化后堆叠。
#---------------------------------------------------#
x = DarknetConv2D_BN_SiLU(out_channels // 2, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
maxpool1 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(x)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(x)
maxpool3 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(x)
x = Concatenate()([x, maxpool1, maxpool2, maxpool3])
x = DarknetConv2D_BN_SiLU(out_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
return x
def resblock_body(x, num_filters, num_blocks, expansion=0.5, shortcut=True, last=False, weight_decay=5e-4, name = ""):
#----------------------------------------------------------------#
# 利用ZeroPadding2D和一个步长为2x2的卷积块进行高和宽的压缩
#----------------------------------------------------------------#
# 320, 320, 64 => 160, 160, 128
x = ZeroPadding2D(((1, 0睿智的目标检测51——Tensorflow2搭建yolo3目标检测平台
睿智的目标检测61——Tensorflow2 Focal loss详解与在YoloV4当中的实现
睿智的目标检测65——Pytorch搭建DETR目标检测平台