睿智的目标检测51——Tensorflow2搭建yolo3目标检测平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了睿智的目标检测51——Tensorflow2搭建yolo3目标检测平台相关的知识,希望对你有一定的参考价值。
睿智的目标检测51——Tensorflow2搭建yolo3目标检测平台
学习前言
对YoloV3进行了重构,用tensorflow2进行了复现。

源码下载
https://github.com/bubbliiiing/yolo3-tf2
喜欢的可以点个star噢。
YoloV3实现思路
一、整体结构解析
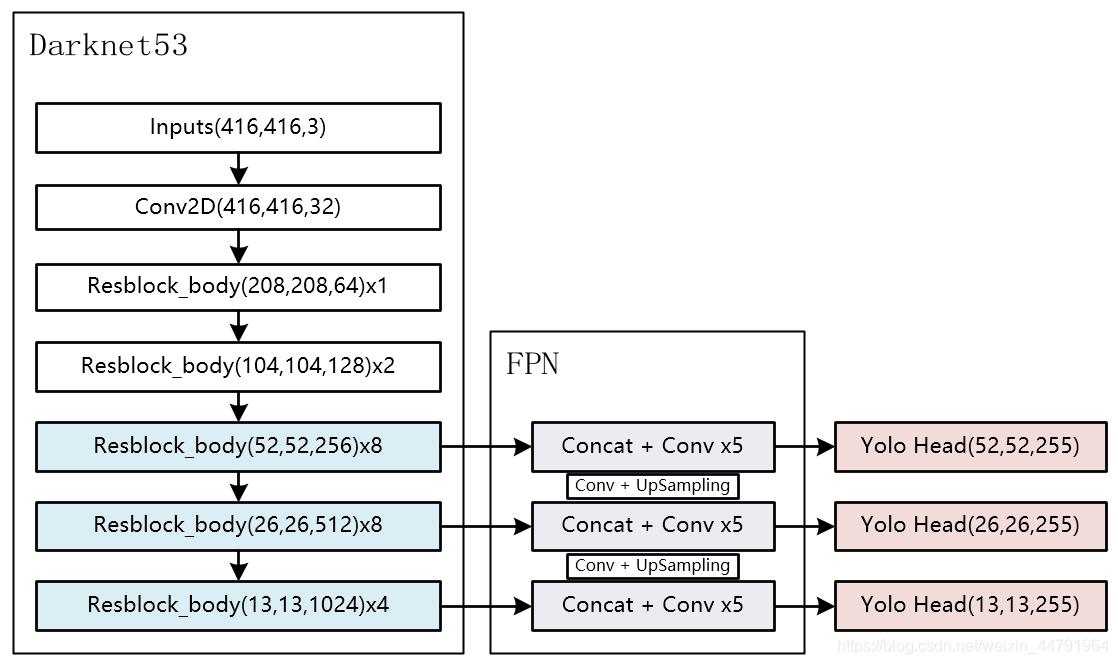
在学习YoloV3之前,我们需要对YoloV3所作的工作有一定的了解,这有助于我们后面去了解网络的细节。
整个YoloV3可以分为三个部分,分别是Darknet53,FPN以及Yolo Head。
Darknet53可以被称作YoloV3的主干特征提取网络,输入的图片首先会在Darknet53里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN可以被称作YoloV3的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。
Yolo Head是YoloV3的分类器与回归器,通过Darknet53和FPN,我们已经可以获得三个加强过的有效特征层,他们的shape分别为(52,52,128),(26,26,256),(13,13,512)。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。
因此,整个YoloV3网络所作的工作就是 特征提取-特征加强-预测特征点对应的物体情况。
二、网络结构解析
1、主干网络Darknet53介绍
YoloV3所使用的主干特征提取网络为Darknet53,它具有两个重要特点:
1、使用了残差网络Residual,Darknet53中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV3的主干部分都由残差卷积构成,上述所示的YoloV3整体结构里,Resblock_body后面的x几就代表在这个特征层部分,残差结构重复了几次。Resblock_body的代码如下,for训练里的就是残差结构:
#---------------------------------------------------#
# 卷积块
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def resblock_body(x, num_filters, num_blocks):
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = DarknetConv2D_BN_Leaky(num_filters//2, (1,1))(x)
y = DarknetConv2D_BN_Leaky(num_filters, (3,3))(y)
x = Add()([x,y])
return x

残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2、Darknet53的每一个DarknetConv2D后面都紧跟了BatchNormalization标准化与LeakyReLU部分。普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。以数学的方式我们可以表示为**:
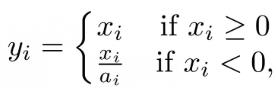
DarknetConv2D_BN_Leaky的实现代码如下
#---------------------------------------------------#
# 卷积块 -> 卷积 + 标准化 + 激活函数
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
整个主干实现代码为:
from functools import wraps
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Add, BatchNormalization, Conv2D, LeakyReLU,
ZeroPadding2D)
from tensorflow.keras.regularizers import l2
from utils.utils import compose
#------------------------------------------------------#
# 单次卷积DarknetConv2D
# 如果步长为2则自己设定padding方式。
# 测试中发现没有l2正则化效果更好,所以去掉了l2正则化
#------------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_initializer' : RandomNormal(stddev=0.02), 'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块 -> 卷积 + 标准化 + 激活函数
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
#---------------------------------------------------------------------#
# 残差结构
# 首先利用ZeroPadding2D和一个步长为2x2的卷积块进行高和宽的压缩
# 然后对num_blocks进行循环,循环内部是残差结构。
#---------------------------------------------------------------------#
def resblock_body(x, num_filters, num_blocks):
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = DarknetConv2D_BN_Leaky(num_filters//2, (1,1))(x)
y = DarknetConv2D_BN_Leaky(num_filters, (3,3))(y)
x = Add()([x,y])
return x
#---------------------------------------------------#
# darknet53 的主体部分
# 输入为一张416x416x3的图片
# 输出为三个有效特征层
#---------------------------------------------------#
def darknet_body(x):
# 416,416,3 -> 416,416,32
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
# 416,416,32 -> 208,208,64
x = resblock_body(x, 64, 1)
# 208,208,64 -> 104,104,128
x = resblock_body(x, 128, 2)
# 104,104,128 -> 52,52,256
x = resblock_body(x, 256, 8)
feat1 = x
# 52,52,256 -> 26,26,512
x = resblock_body(x, 512, 8)
feat2 = x
# 26,26,512 -> 13,13,1024
x = resblock_body(x, 1024, 4)
feat3 = x
return feat1, feat2, feat3
2、构建FPN特征金字塔进行加强特征提取
在特征利用部分,YoloV3提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分Darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024)。
在获得三个有效特征层后,我们利用这三个有效特征层进行FPN层的构建,构建方式为:
- 13x13x1024的特征层进行5次卷积处理,处理完后利用YoloHead获得预测结果,一部分用于进行上采样UmSampling2d后与26x26x512特征层进行结合,结合特征层的shape为(26,26,768)。
- 结合特征层再次进行5次卷积处理,处理完后利用YoloHead获得预测结果,一部分用于进行上采样UmSampling2d后与52x52x256特征层进行结合,结合特征层的shape为(52,52,384)。
- 结合特征层再次进行5次卷积处理,处理完后利用YoloHead获得预测结果。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
from tensorflow.keras.layers import Concatenate, Input, Lambda, UpSampling2D
from tensorflow.keras.models import Model
from utils.utils import compose
from nets.darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from nets.yolo_training import yolo_loss
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
y = DarknetConv2D(out_filters, (1,1))(y)
return y
#---------------------------------------------------#
# FPN网络的构建,并且获得预测结果
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# C3 为 52,52,256
# C4 为 26,26,512
# C5 为 13,13,1024
#---------------------------------------------------#
C3, C4, C5 = darknet_body(inputs)
#---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,13,13,3,85)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(C5, 512)
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes+5))
# 13,13,512 -> 13,13,256 -> 26,26,256
x = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(x)
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4])
#---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,26,26,3,85)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, 256)
P4 = make_yolo_head(x, 256, len(anchors_mask[1]) * (num_classes+5))
# 26,26,256 -> 26,26,128 -> 52,52,128
x = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(x)
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, C3])
#---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,52,52,3,85)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, 128)
P3 = make_yolo_head(x, 128, len(anchors_mask[2]) * (num_classes+5))
return Model(inputs, [P5, P4, P3])
3、利用Yolo Head获得预测结果
利用FPN特征金字塔,我们可以获得三个加强特征,这三个加强特征的shape分别为(13,13,512)、(26,26,256)、(52,52,128),然后我们利用这三个shape的特征层传入Yolo Head获得预测结果。
Yolo Head本质上是一次3x3卷积加上一次1x1卷积,3x3卷积的作用是特征整合,1x1卷积的作用是调整通道数。
对三个特征层分别进行处理,假设我们预测是的VOC数据集,我们的输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,YoloV3针对每一个特征层的每一个特征点存在3个先验框,所以预测结果的通道数为3x25;
如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
其实际情况就是,输入N张416x416的图片,在经过多层的运算后,会输出三个shape分别为(N,13,13,255),(N,26,26,255),(N,52,52,255)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
实现代码如下:
from tensorflow.keras.layers import Concatenate, Input, Lambda, UpSampling2D
from tensorflow.keras.models import Model
from utils.utils import compose
from nets.darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from nets.yolo_training import yolo_loss
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
y = DarknetConv2D(out_filters, (1,1))(y)
return y
#---------------------------------------------------#
# FPN网络的构建,并且获得预测结果
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# C3 为 52,52,256
# C4 为 26,26,512
# C5 为 13,13,1024
#---------------------------------------------------#
C3, C4, C5 = darknet_body(inputs)
#---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,13,13,3,85)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(C5, 512)
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes+5))
# 13,13,512 -> 13,13,256 -> 26,26,256
x = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(x)
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4])
#---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,26,26,3,85)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, 256)
P4 = make_yolo_head(x, 256, len(anchors_mask[1]) * (num_classes+5))
# 26,26,256 -> 26,26,128 -> 52,52,128
x = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(x)
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, C3])
#---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,52,52,3,85)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, 128)
P3 = make_yolo_head(x, 128, len(anchors_mask[2]) * (num_classes+5))
return Model(inputs, [P5, P4, P3])
三、预测结果的解码
1、什么是先验框
由网络我们可以获得三个特征层的预测结果,shape分别为:
- (N,13,13,255)
- (N,26,26,255)
- (N,52,52,255)
N代表的是batch_size,就是输入图片的数量,我们可以忽略,但是后面的(52,52,255)、(26,26,255)、(13,13,255),就不可以忽略了。
每一个预测结果都有宽、高和通道数,宽、高里面是一个又一个特征点,那此时我们便可以想办法利用这些特征点,和原图进行结合。
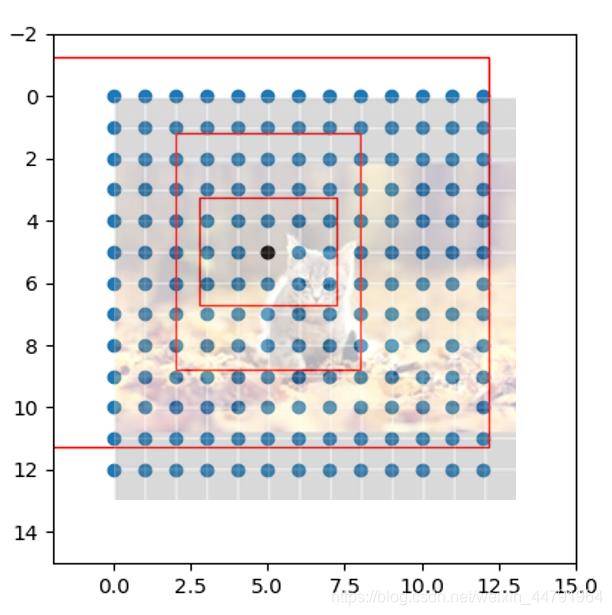
我们再看看预测结果的特点,13X13,26X26,52X52,它是不是非常像三个等分的网格?如果我们将原图划分成对应13X13,26X26,52X52的部分,是不是整个特征层就以某种形式映射在原图上了。
事实上yolo系列就是这么做的,每一个有效特征层将整个图片分成与其长宽对应的网格,仔细看看这幅图,原图被划分成13x13的网格;然后从每个网格中心建立多个先验框,典型值是一个特征点三个先验框,这些框是网络预先设定好的框,网络的预测结果会判断这些框内是否包含物体,以及这个物体的种类。
2、获得先验框后做什么
由网络我们可以获得三个特征层的预测结果,shape分别为:
- (N,13,13,255)
- (N,26,26,255)
- (N,52,52,255)
由于每一个网格点都具有三个先验框,所以上述的预测结果可以reshape为: - (N,13,13,3,85)
- (N,26,26,3,85)
- (N,52,52,3,85)
其中的85可以拆分为4+1+80,其中的4代表先验框的调整参数,1代表先验框内是否包含物体,80代表的是这个先验框的种类,由于coco分了80类,所以这里是80。如果YoloV3只检测两类物体,那么这个85就变为了4+1+2 = 7。
即85包含了4+1+80,分别代表x_offset、y_offset、h和w、置信度、分类结果。
但是这个预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。
YoloV3的解码过程分为两步:
- 先将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心。
- 然后再利用 先验框和h、w结合 计算出预测框的宽高。这样就能得到整个预测框的位置了。
下图展示了YoloV3解码的过程:

实现代码如下,当调用DecodeBox时,就会进行解码:
#---------------------------------------------------#
# 对box进行调整,使其符合真实图片的样子
#---------------------------------------------------#
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image):
#-----------------------------------------------------------------#
# 把y轴放前面是因为方便预测框和图像的宽高进行相乘
#-----------------------------------------------------------------#
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
if letterbox_image:
#-----------------------------------------------------------------#
# 这里求出来的offset是图像有效区域相对于图像左上角的偏移情况
# new_shape指的是宽高缩放情况
#-----------------------------------------------------------------#
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape - new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw