睿智的目标检测65——Pytorch搭建DETR目标检测平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了睿智的目标检测65——Pytorch搭建DETR目标检测平台相关的知识,希望对你有一定的参考价值。
睿智的目标检测65——Pytorch搭建DETR目标检测平台
学习前言
基于Transformer的目标检测一直没弄,补上一下。

源码下载
https://github.com/bubbliiiing/detr-pytorch
喜欢的可以点个star噢。
DETR实现思路
一、整体结构解析
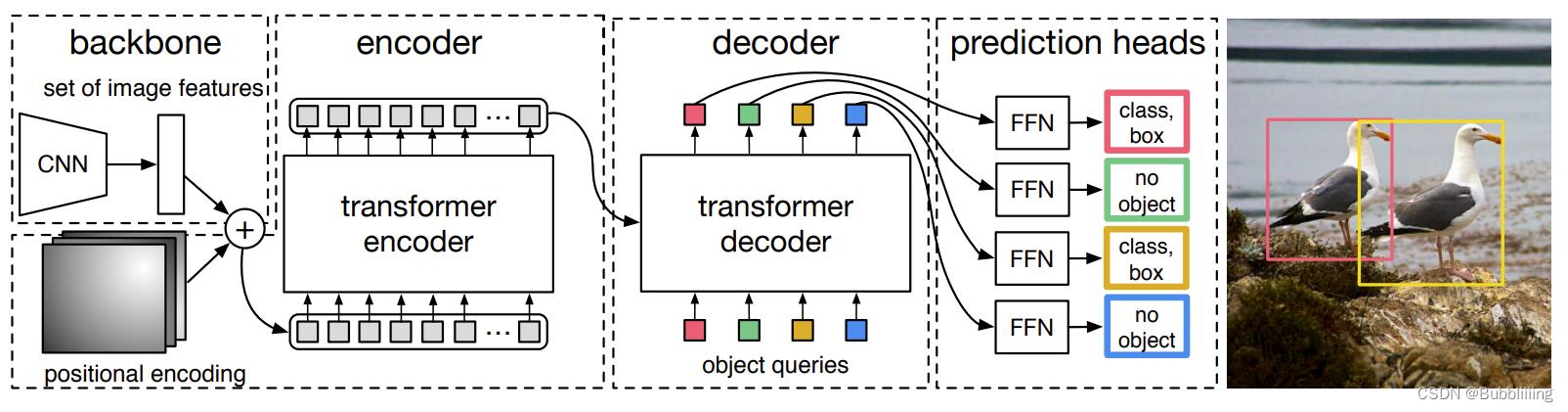
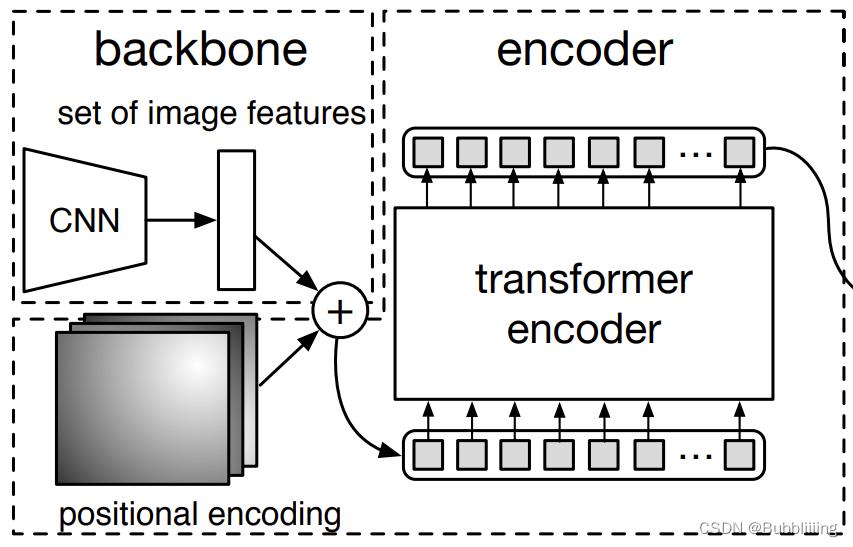
在学习DETR之前,我们需要对DETR所做的工作有一定的了解,这有助于我们后面去了解网络的细节。上面这幅图是论文里的Fig. 2,比较好的展示了整个DETR的工作原理。整个DETR可以分为四个部分,分别是:backbone、encoder、decoder以及prediction heads。
backbone是DETR的主干特征提取网络,输入的图片首先会在主干网络里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了一个特征层进行下一步网络的构建,这一个特征层我称它为有效特征层。
encoder是Transformer的编码网络-特征加强,在主干部分获得的一个有效特征层会首先在高宽维度进行平铺,成为一个特征序列,然后会在这一部分继续使用Self-Attension进行加强特征提取,获得一个加强后的有效特征层。它属于Transformer的编码网络,编码的下一步是解码。
decoder是Transformer的解码网络-特征查询,在encoder部分获得的一个加强后的有效特征层会在这一部分进行解码,解码需要使用到一个非常重要的可学习模块,即上图呈现的object queries。在decoder部分,我们使用一个可学习的查询向量q对加强后的有效特征层进行查询,获得预测结果。
prediction heads是DETR的分类器与回归器,其实就是对decoder获得的预测结果进行全连接,两次全连接分别代表种类和回归参数。图上画了4个FFN,源码中是2个FFN。
因此,整个DETR网络所作的工作就是 特征提取-特征加强-特征查询-预测结果。
二、网络结构解析
1、主干网络Backbone介绍
DETR可以采用多种的主干特征提取网络,论文中用的是Resnet,本文以Resnet50网络为例子来给大家演示一下。
a、什么是残差网络
Residual net(残差网络):
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下:
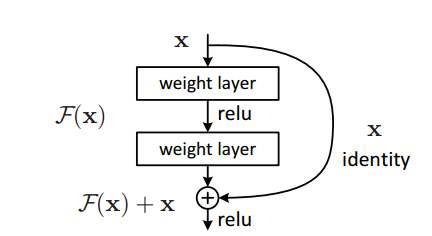
深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
b、什么是ResNet50模型
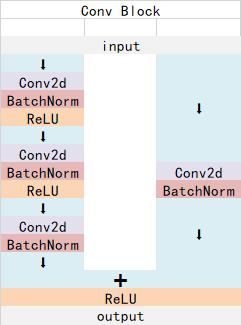
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,它的作用是加深网络的。
Conv Block的结构如下,由图可以看出,Conv Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,存在一次卷积、标准化,由于残差边部分存在卷积,所以我们可以利用Conv Block改变输出特征层的宽高和通道数:
Identity Block的结构如下,由图可以看出,Identity Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,直接与输出相接,由于残差边部分不存在卷积,所以Identity Block的输入特征层和输出特征层的shape是相同的,可用于加深网络:
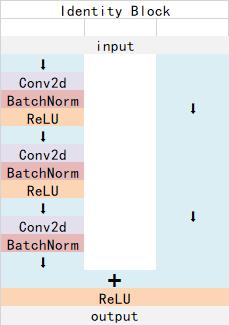
Conv Block和Identity Block都是残差网络结构。
总的网络结构如下:

在DETR中,假设输入为[batch_size, 3, 800, 800],此时输出为[batch_size, 2048, 25, 25],代码直接使用了torchvision库中自带的resnet,因此整个主干实现代码为:
class FrozenBatchNorm2d(torch.nn.Module):
"""
冻结固定的BatchNorm2d。
"""
def __init__(self, n):
super(FrozenBatchNorm2d, self).__init__()
self.register_buffer("weight", torch.ones(n))
self.register_buffer("bias", torch.zeros(n))
self.register_buffer("running_mean", torch.zeros(n))
self.register_buffer("running_var", torch.ones(n))
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
num_batches_tracked_key = prefix + 'num_batches_tracked'
if num_batches_tracked_key in state_dict:
del state_dict[num_batches_tracked_key]
super(FrozenBatchNorm2d, self)._load_from_state_dict(
state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
def forward(self, x):
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
rv = self.running_var.reshape(1, -1, 1, 1)
rm = self.running_mean.reshape(1, -1, 1, 1)
eps = 1e-5
scale = w * (rv + eps).rsqrt()
bias = b - rm * scale
return x * scale + bias
class BackboneBase(nn.Module):
"""
用于指定返回哪个层的输出
这里返回的是最后一层
"""
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:
return_layers = "layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"
else:
return_layers = 'layer4': "0"
# 用于指定返回的层
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] =
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""
ResNet backbone with frozen BatchNorm.
"""
def __init__(self, name: str, train_backbone: bool, return_interm_layers: bool,dilation: bool):
# 首先利用torchvision里面的model创建一个backbone模型
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation = [False, False, dilation],
pretrained = is_main_process(),
norm_layer = FrozenBatchNorm2d
)
# 根据选择的模型,获得通道数
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
c、位置编码
除去利用主干进行特征提取外,因为要传入Transformer进行特征提取与特征查询,主干获得的特征还需要进行位置编码。在图片上不属于backbone,但是在backbone.py里实现的,所以一起简单解析一下。
其实就是原Transformer的position embedding的思想,为所有特征添加上位置信息,这样网络才有区分不同区域的能力。
DETR是为resnet输出的特征图在pos_x和pos_y方向各自计算了一个位置编码,每个维度的位置编码长度为num_pos_feats,默认为Transformer的特征长度的一半,为128。对pos_x和pos_y,在奇数位置计算正弦,在偶数位置计算余弦,然后将计算结果进行拼接。得到一个[batch_size, h, w, 256]的向量。最后进行转置,获得[batch_size, 256, h, w]的向量。
代码如下:
class PositionEmbeddingSine(nn.Module):
"""
这是一个更标准的位置嵌入版本,按照sine进行分布
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
2、编码网络Encoder网络介绍
a、Transformer Encoder的构建
在上文中,我们获得了两个矩阵,一个矩阵是输入图片的特征矩阵,一个是特征矩阵对应的位置编码。它们的shape分别为[batch_size, 2048, 25, 25]、[batch_size, 256, 25, 25]。
在编码网络部分,DETR使用Transformer的Encoder部分进行特征提取。我们需要首先对特征矩阵进行通道的缩放,如果直接对特征矩阵进行transformer的特征提取的话,由于网络的通道数太大(2048),会直接导致显存不足。利用一个1x1的nn.Conv2d进行通道的压缩,压缩后的通道为256,即Transformer用到的特征长度。此时我们获得了一个shape为[batch_size, 256, 25, 25]的特征矩阵。
然后我们对特征矩阵与位置编码的高宽维度进行平铺获得两个shape为[batch_size, 256, 625]的矩阵,由于我们使用的是Pytorch自带的nn.MultiheadAttention,该模块要求batch_size位于第1维,序列长度位于第0维,所以我们将特征矩阵与位置编码进行转置,转置后的两个矩阵为[625, batch_size, 256]。
我们此时可以将其输入到Encoder当中进行特征提取。Encoder并不会改变输入的shape,因此经过Encoder进行特征提取的加强后的特征序列shape也为[625, batch_size, 256]。
由于在DETR中,Transformer的Encoder直接使用了Pytorch的MultiheadAttention,我们不必太贵纠结原理,简单了解一下就可以,在DETR中,整个Transformer Encoder的实现代码为:
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
# 625, batch_size, 256 => ...(x6)... => 625, batch_size, 256
for layer in self.layers:
output = layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
# Self-Attention模块
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# FFN模块
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 添加位置信息
# 625, batch_size, 256 => 625, batch_size, 256
q = k = self.with_pos_embed(src, pos)
# 使用自注意力机制模块
# 625, batch_size, 256 => 625, batch_size, 256
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
# 添加残差结构
# 625, batch_size, 256 => 625, batch_size, 256
src = src + self.dropout1(src2)
# 添加FFN结构
# 625, batch_size, 256 => 625, batch_size, 2048 => 625, batch_size, 256
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# 添加残差结构
# 625, batch_size, 256 => 625, batch_size, 256
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
b、Self-attention结构解析
在这里可以简单了解一下多头注意力机制的原理,多头注意力机制的计算原理如下:
看懂Self-attention结构,其实看懂下面这个动图就可以了,动图中存在一个序列的三个单位输入,每一个序列单位的输入都可以通过三个处理(比如全连接)获得Query、Key、Value,Query是查询向量、Key是键向量、Value值向量。
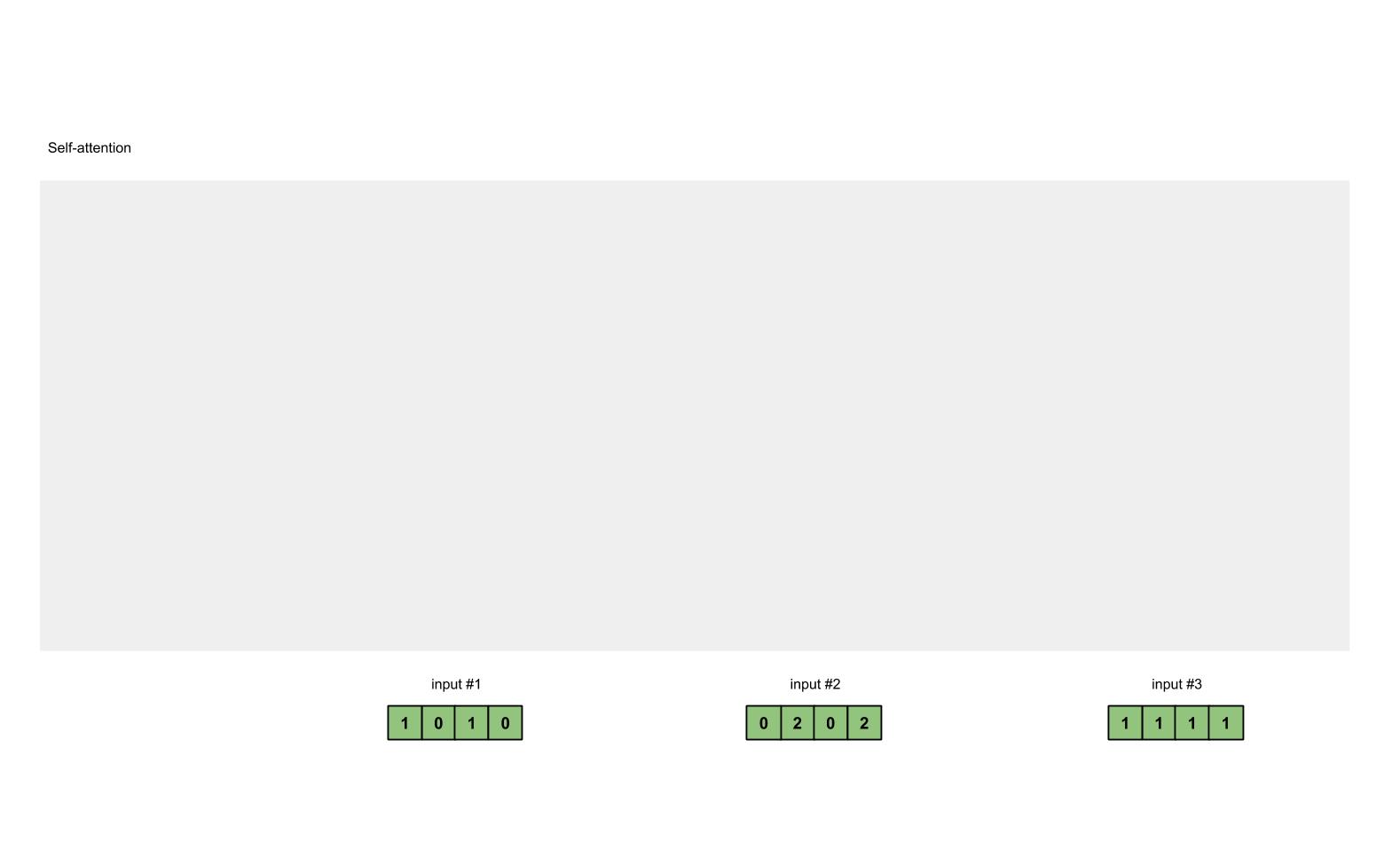
如果我们想要获得input-1的输出,那么我们进行如下几步:
1、利用input-1的查询向量,分别乘上input-1、input-2、input-3的键向量,此时我们获得了三个score。
2、然后对这三个score取softmax,获得了input-1、input-2、input-3各自的重要程度。
3、然后将这个重要程度乘上input-1、input-2、input-3的值向量,求和。
4、此时我们获得了input-1的输出。
如图所示,我们进行如下几步:
1、input-1的查询向量为[1, 0, 2],分别乘上input-1、input-2、input-3的键向量,获得三个score为2,4,4。
2、然后对这三个score取softmax,获得了input-1、input-2、input-3各自的重要程度,获得三个重要程度为0.0,0.5,0.5。
3、然后将这个重要程度乘上input-1、input-2、input-3的值向量,求和,即
0.0
∗
[
1
,
2
,
3
]
+
0.5
∗
[
2
,
8
,
0
]
+
0.5
∗
[
2
,
6
,
3
]
=
[
2.0
,
7.0
,
1.5
]
0.0 * [1, 2, 3] + 0.5 * [2, 8, 0] + 0.5 * [2, 6, 3] = [2.0, 7.0, 1.5]
0.0∗[1,2,3]+0.5∗[2,8,0]+0.5∗[2,6,