我是土堆 - Pytorch教程 知识点 学习总结笔记
Posted 耿鬼喝椰汁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我是土堆 - Pytorch教程 知识点 学习总结笔记相关的知识,希望对你有一定的参考价值。
此文章为【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)包括:完整的模型训练套路(一)、完整的模型训练套路(二)、完整的模型训练套路(三)、利用GPU训练(一)、利用GPU训练(二)、完整的模型验证套路、【完结】看看开源项目。
学习系列笔记(已完结):
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(二)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(三)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(四)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(五)_耿鬼喝椰汁的博客-CSDN博客
目录
2.model.train() 和 model.eval()
一、完整的模型训练套路(一)
以 CIFAR10 数据集为例,分类问题(10分类)
pycharm中 在语句后面按 Ctrl + d 可以复制这条语句
此教程搭建的网络模型:
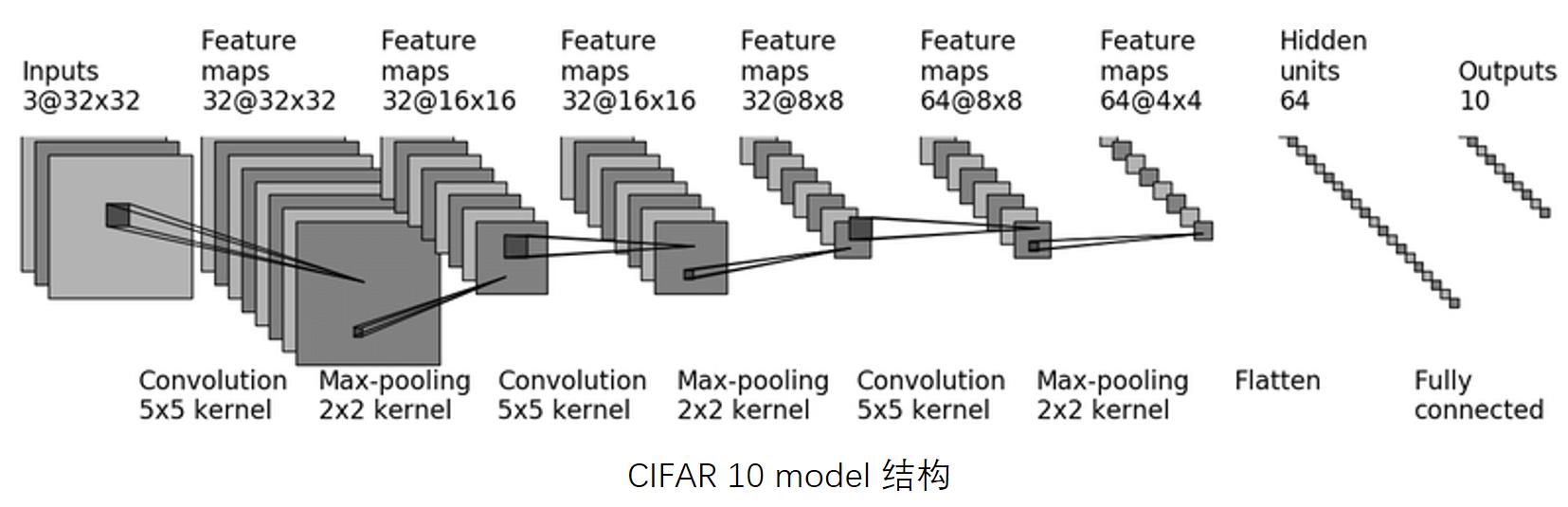
1.model.py 文件代码
import torch
from torch import nn
# 搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
# 测试网络的验证正确性
tudui = Tudui()
input = torch.ones((64,3,32,32)) # batch_size=64(代表64张图片),3通道,32x32
output = tudui(input)
print(output.shape)运行结果如下:

返回64行数据,每一行数据有10个数据,代表每一张图片在10个类别中的概率。
2.train.py 文件代码
(与 model.py 文件必须在同一个文件夹底下)
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
for i in range(epoch):
print("----------第轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader: # 从训练的dataloader中取数据
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
print("训练次数:,loss:".format(total_train_step,loss.item()))运行结果如下:

print(a) 和 print(a.item()) 的区别
import torch
a = torch.tensor(5)
print(a)
print(a.item())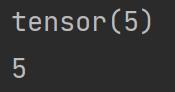
二、完整的模型训练套路(二)
1.如何知道模型是否训练好,或达到需求?
每次训练完一轮就进行测试,以测试数据集上的损失或正确率来评估模型有没有训练好
测试过程中不需要对模型进行调优,利用现有模型进行测试,所以有以下命令:
with torch.no_grad(): 在上述 train.py 代码后继续写:
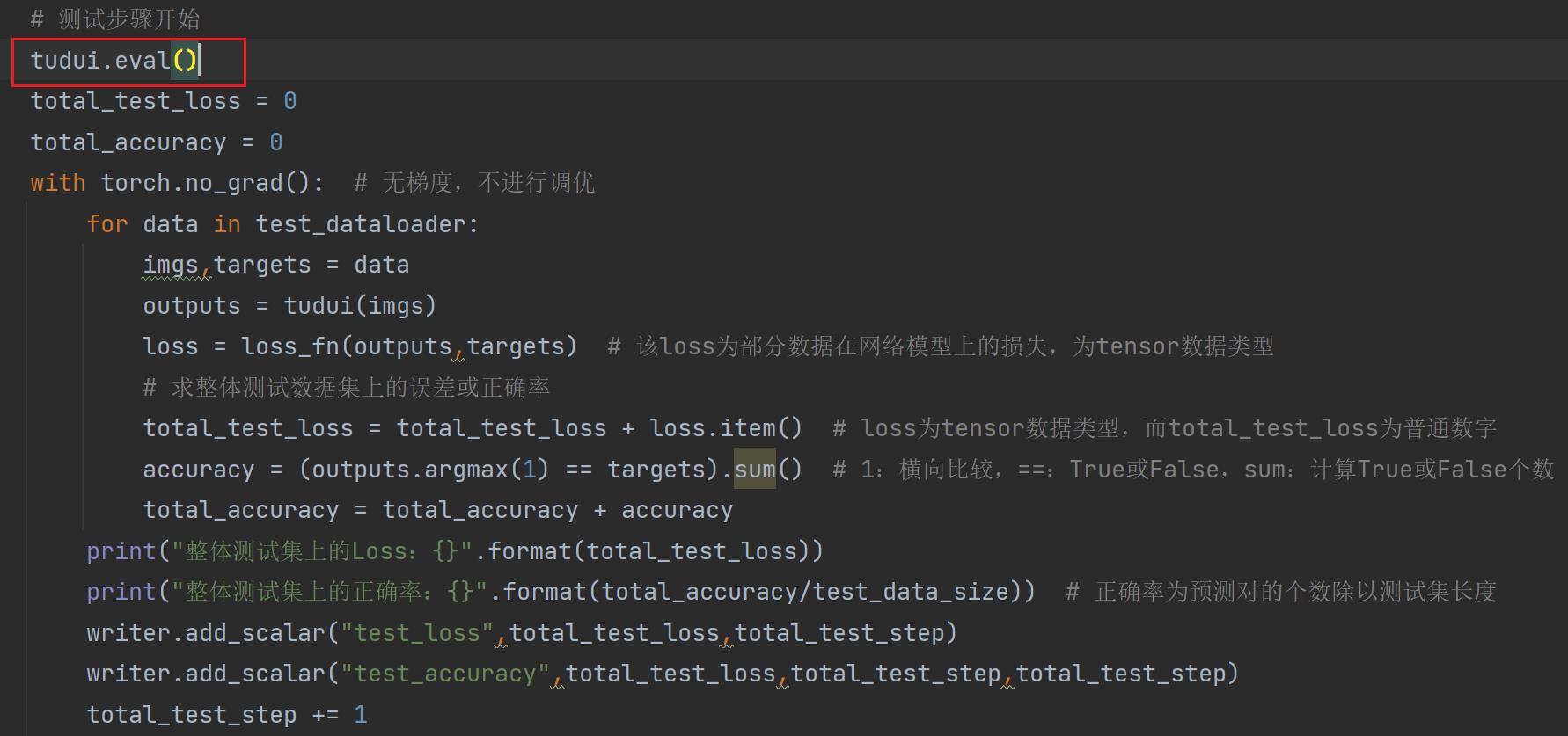
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字,所以要.item()一下
print("整体测试集上的Loss:".format(total_test_loss))结果如下:

此处为了使测试的 loss 结果易找,在 train.py 中添加了一句 if 的代码,使train每训练100轮才打印1次:
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step,loss.item()))完整代码
import torchvision.datasets
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
for i in range(epoch):
print("----------第轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step,loss.item()))
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
print("整体测试集上的Loss:".format(total_test_loss))2. 与 TensorBoard 结合
添加TensorBoard后的代码:
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----------第轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
total_test_loss = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
print("整体测试集上的Loss:".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step += 1
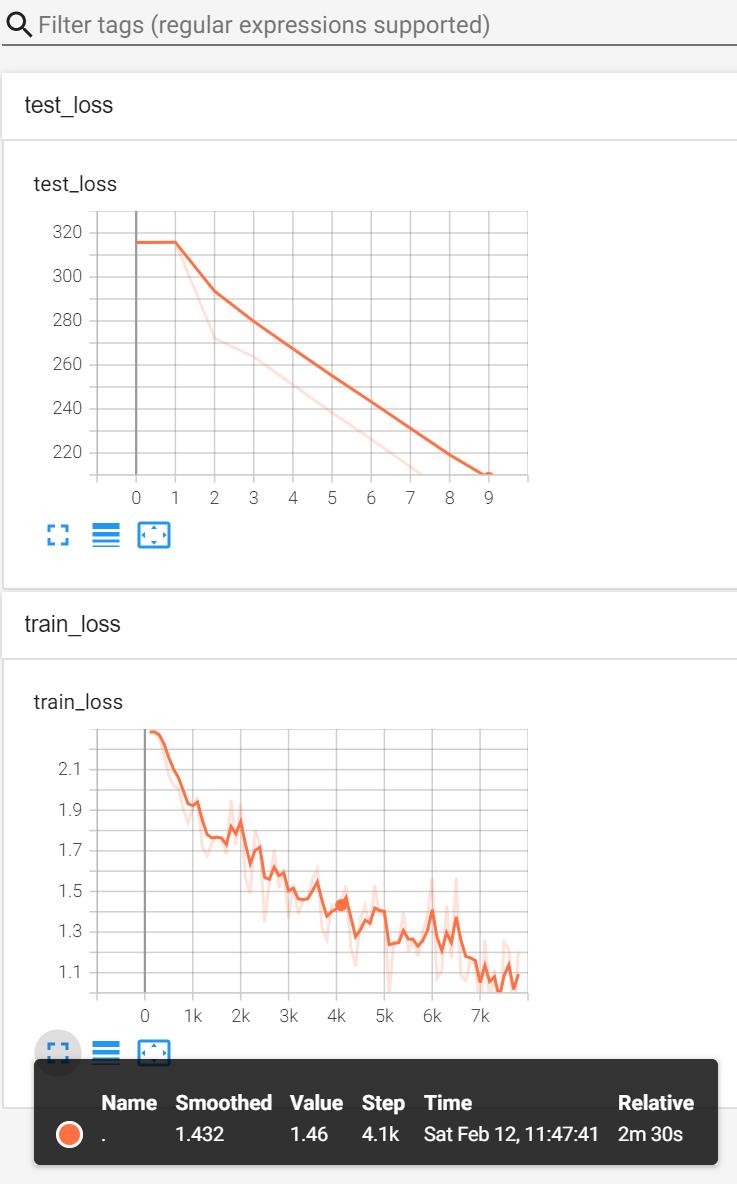
writer.close()运行结果:
在 Terminal 里输入:
tensorboard --logdir=logs_train打开网页后显示图片:
3. 保存每一轮训练的模型
添加两句代码:
torch.save(tudui,"tudui_.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()运行后:
正确率的实现(对分类问题)
4.正确率的实现(对分类问题)
即便得到整体测试集上的 loss,也不能很好说明在测试集上的表现效果
- 在分类问题中可以用正确率表示(下述代码改进)
- 在目标检测/语义分割中,可以把输出放在tensorboard里显示,看测试结果
例子:

第一步:(个人理解:argmax()返回数组中最大值的索引。)
import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
print(outputs.argmax(1)) # 0或1表示方向,1为横向比较大小. 运行结果:tensor([1, 1])
第二步:
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print(preds == targets) # tensor([False, True])
print(sum(preds == targets).sum()) # tensor(1),对应位置相等的个数上例说明了基本用法,现对原问题的代码再进一步优化,计算整体正确率:
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
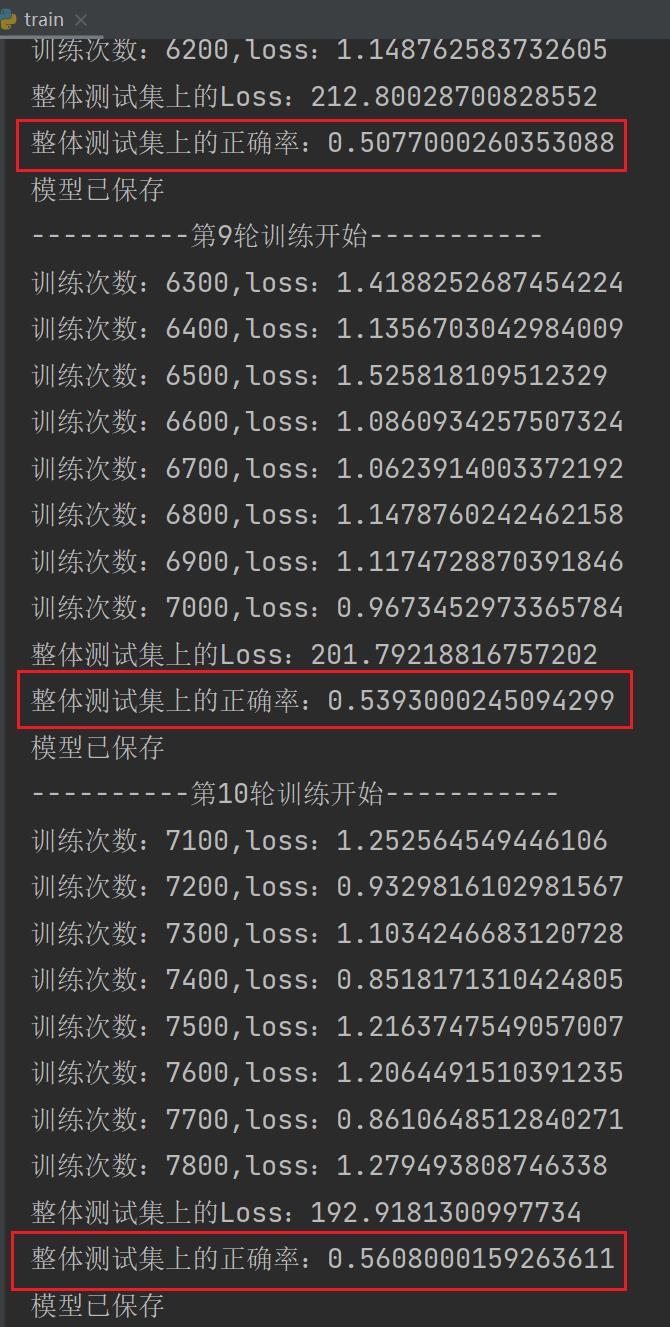
print("整体测试集上的Loss:".format(total_test_loss))
print("整体测试集上的正确率:".format(total_accuracy/imgs.size(0)))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/imgs.size(0),total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()运行结果:
在 Terminal 里输入:
tensorboard --logdir=logs_train打开网址 :

三、完整的模型训练套路(三)
此章节注意一些细节:
1.train.py 完整代码
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----------第轮训练开始-----------".format(i+1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:".format(total_test_loss))
print("整体测试集上的正确率:".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
torch.save(tudui,"tudui_.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
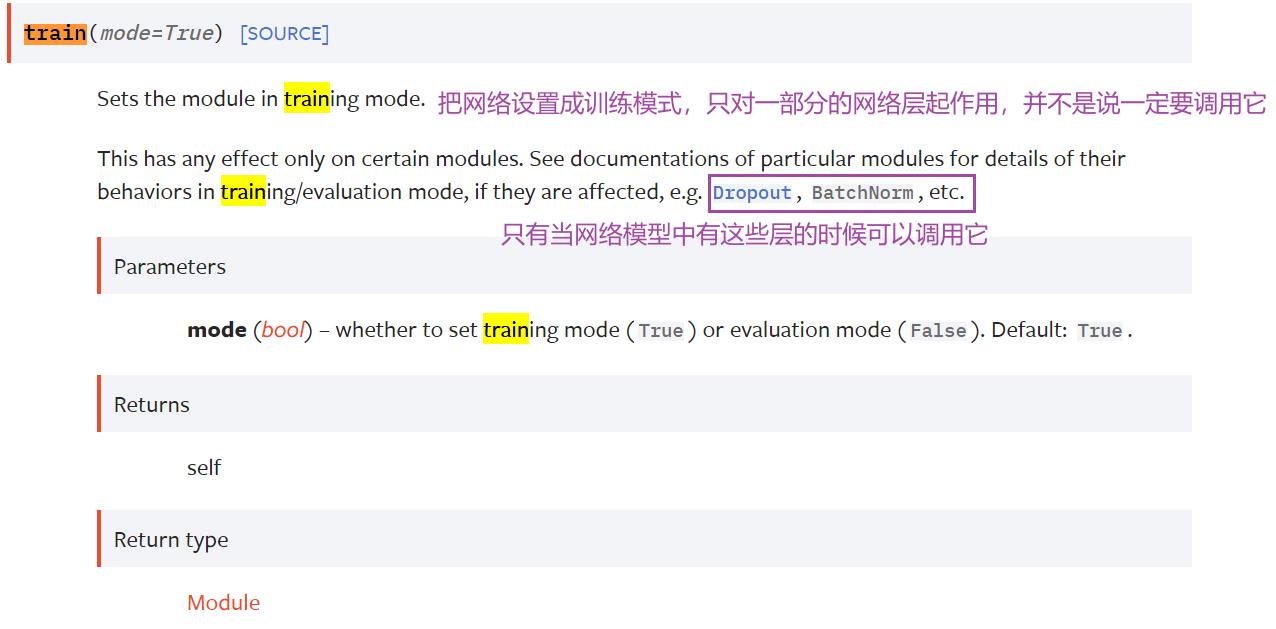
writer.close()2.model.train() 和 model.eval()

训练步骤开始之前会把网络模型(我们这里的网络模型叫 tudui)设置为train,并不是说把网络设置为训练模型它才能够开始训练
测试网络前写 网络.eval(),并不是说需要这一行才能把网络设置成 eval 状态,才能进行网络测试。
3.作用
这两句不写网络依然可以运行,它们的作用是:
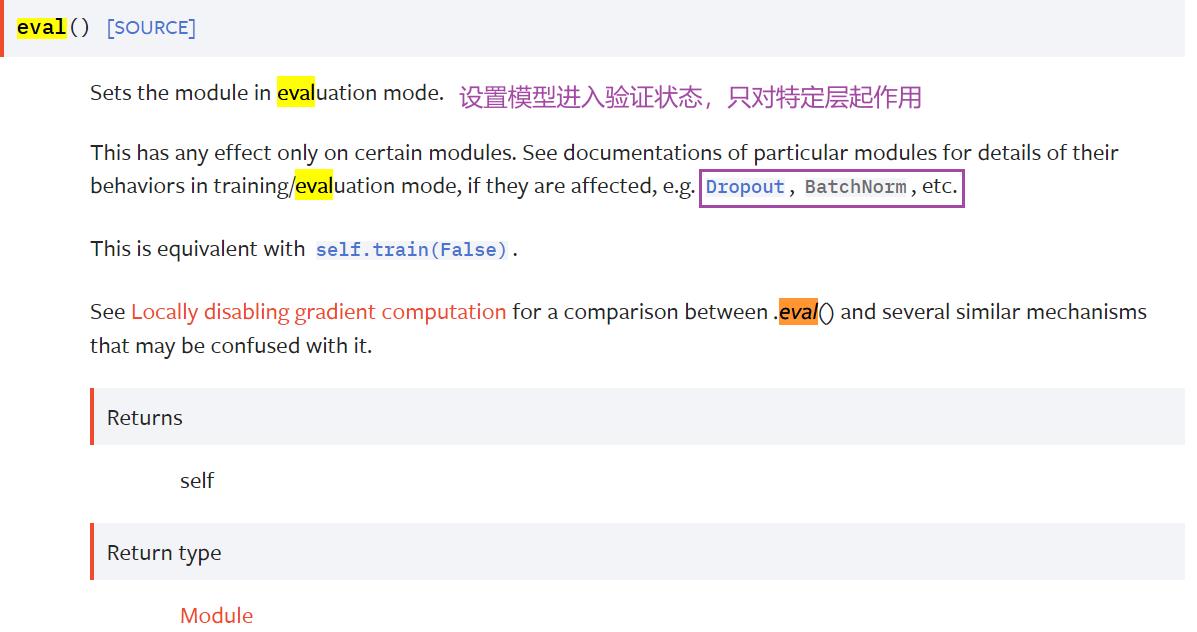
本节写的案例没有 Dropout 层或 BatchNorm 层,所以有没有这两行无所谓
如果有这些特殊层,一定要调用。
回顾案例
首先,要准备数据集,准备对应的 dataloader
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)调用
tudui.train() 使网络进入训练状态,从训练的 dataloader 中不断取数据,算出误差,放到优化器中进行优化,采用某种特定的方式展示输出,一轮结束后或特定步数后进行测试
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 ==0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)测试过程中可以设置
tudui.eval() 要设置
with torch.no_grad(): 让网络模型中的参数都没有,因为我们只需要进行测试,不需要对网络模型进行调整,更不需要利用梯度来优化。
从测试数据集中取数据,计算误差,构建特殊指标显示出来。
for data in test_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy最后可以通过一些方式来展示一下训练的网络在测试集上的效果
print("整体测试集上的Loss:".format(total_test_loss))
print("整体测试集上的正确率:".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1在特定步数或某一轮可以保存模型,保存模型的方式是之前讲的方式1:
torch.save(tudui,"tudui_.pth".format(i))回忆官方推荐的方式2:
torch.save(tudui.state_dict,"tudui_.pth".format(i))(将网络模型的状态转化为字典型,展示它的特定保存位置)
四、利用GPU训练(一)
两种方式实现代码在GPU上训练:
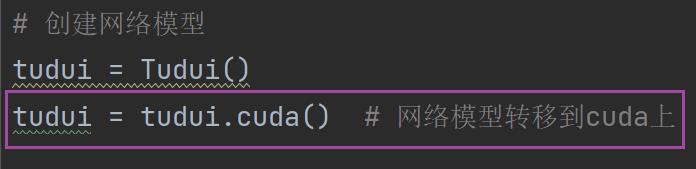
1.第一种使用GPU训练的方式

1.网络模型
2.数据(包括输入、标注):

( 训练过程)

( 测试过程)
3.损失函数:

更好的写法:(其他几个地方也可以类似这样写)
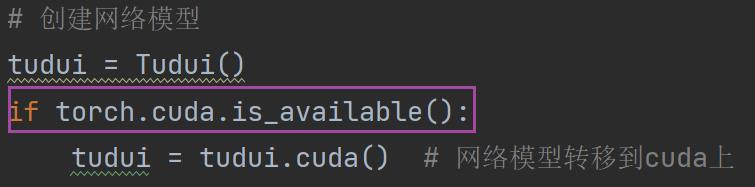
其他地方同理加上
这种写法在CPU和GPU上都可以跑,优先在GPU上跑
train_gpu_1 整体完整代码:
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4,64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("----------第轮训练开始-----------".format(i + 1)) # i从0-9
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 首先要梯度清零
loss.backward() # 反向传播得到每一个参数节点的梯度
optimizer.step() # 对参数进行优化
total_train_step += 1
if total_train_step % 100 == 0: # 逢百才打印记录
print("训练次数:,loss:".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 无梯度,不进行调优
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 该loss为部分数据在网络模型上的损失,为tensor数据类型
# 求整体测试数据集上的误差或正确率
total_test_loss = total_test_loss + loss.item() # loss为tensor数据类型,而total_test_loss为普通数字
# 求整体测试数据集上的误差或正确率
accuracy = (outputs.argmax(1) == targets).sum() # 1:横向比较,==:True或False,sum:计算True或False个数
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:".format(total_test_loss))
print("整体测试集上的正确率:".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, "tudui_.pth".format(i)) # 每一轮保存一个结果
print("模型已保存")
writer.close()2. 比较CPU/GPU训练时间
为了比较时间,引入 time 这个 package
(1)对于CPU
1.引用 time 的 package

2.记录开始时间
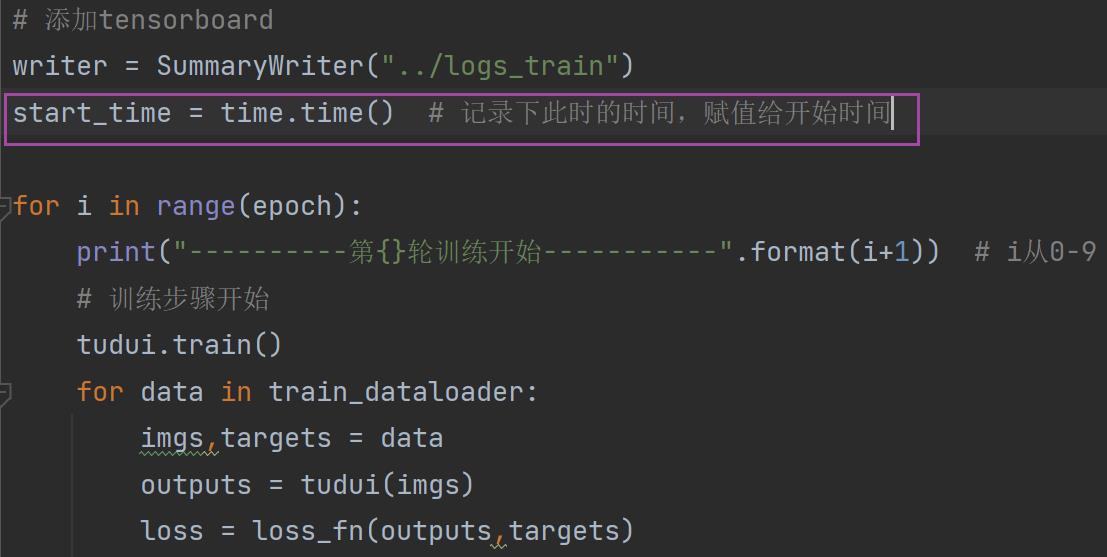
3. 记录截至时间并输出所用时间
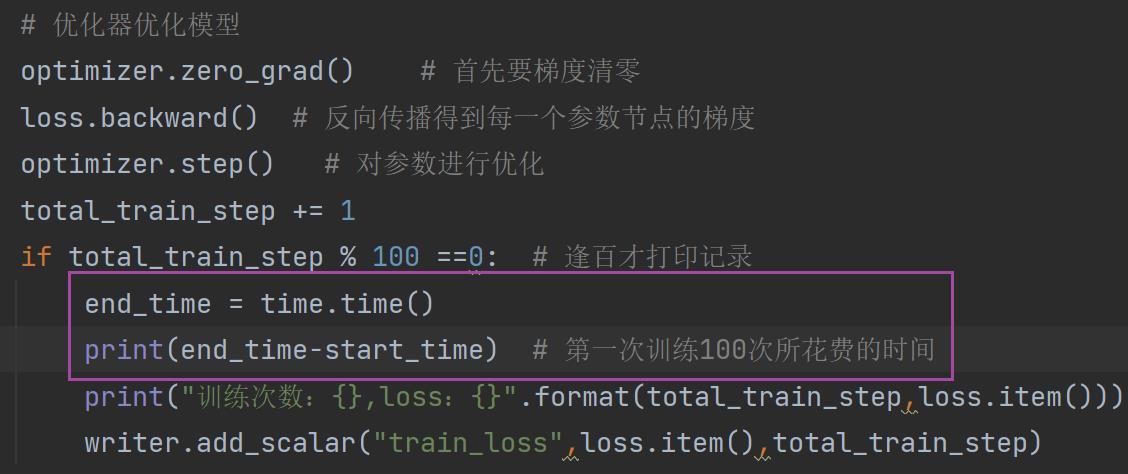
4. 运行 train.py,可以看到它的运行时间

(2) 对于GPU
与上面相同的步骤(相同地方引入time)运行后结果如下:

时间竟然比CPU长(我不理解呜呜呜!)
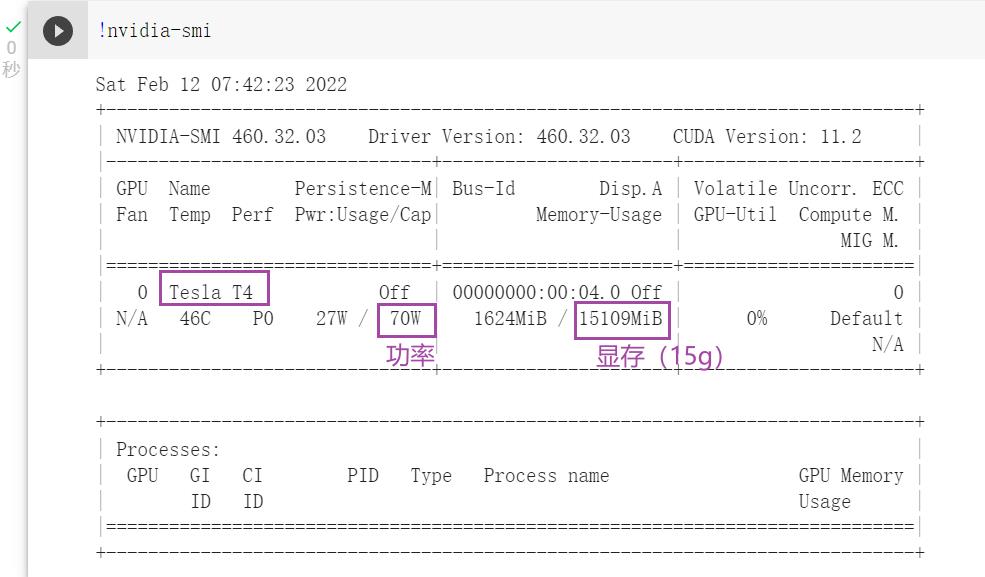
(3)查看GPU信息
在 Terminal 里输入:
nvidia-smi会出现一些GPU的信息

3.Google Colab
Google 为我们提供了一个免费的GPU,默认提供的环境当中就有Pytorch(使用过程需要魔法tz哦)
colab 网站:https://colab.research.google.com/
进来时候新建笔记本:

输入代码运行后我们发现现在还不能使用GPU:

1.如何在Google Colab使用GPU?
修改 ——> 笔记本设置 ——> 硬件加速器选择GPU(每周免费使用30h)
(使用GPU后会重新启动环境)
设置后对比:
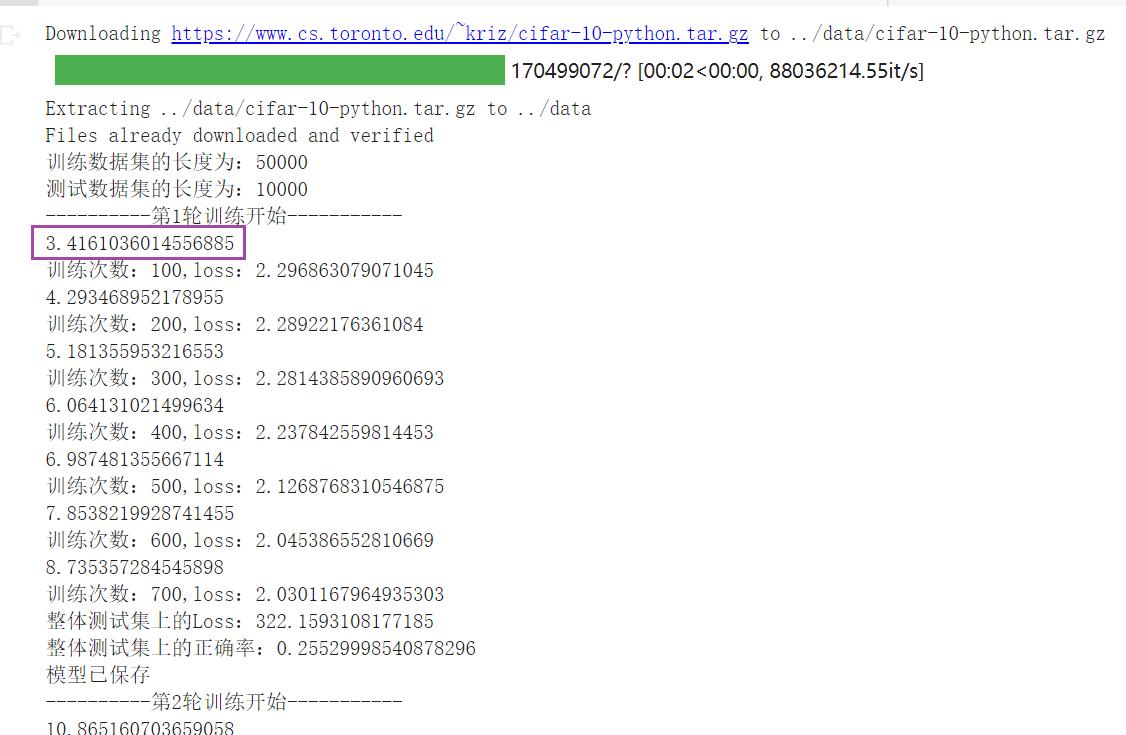
将 train_gpu_1.py 代码复制进去运行,速度很快,结果如下:
查看GPU配置
在 Google Colab 上运行 terminal 中运行的东西,在语句前加 !(感叹号)
五、利用GPU训练(一)
1.第二种使用GPU训练的方式(更常用)

以下两种写法对于单显卡来说等价:
device = torch.device("cuda")
device = torch.device("cuda:0")1.定义训练的设备
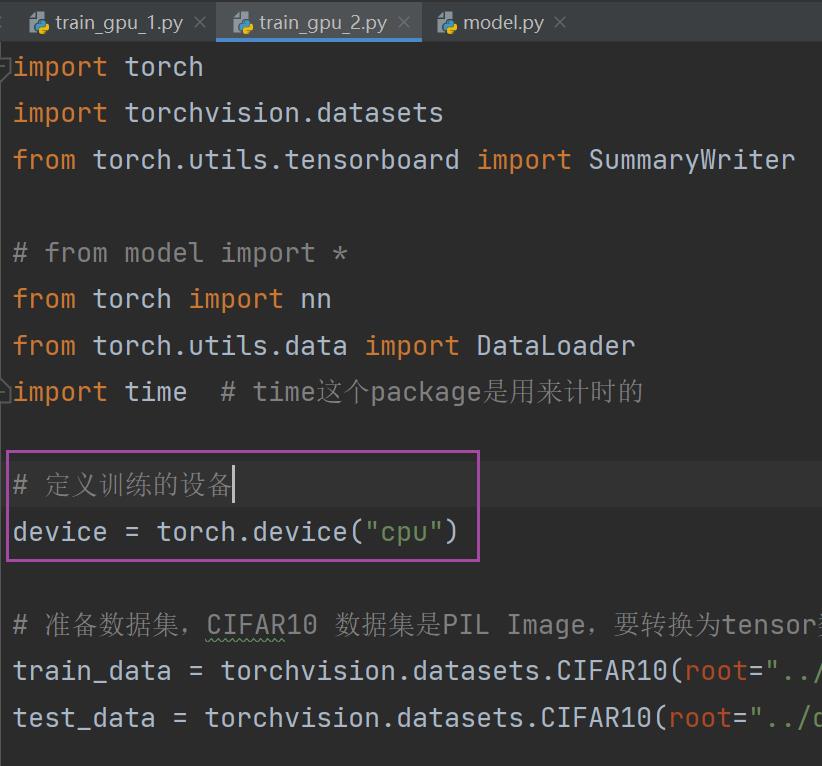
(通过这个变量可以控制是在CPU上运行还是GPU(改成 "cuda" 或 "cuda:0" )上运行)
2.模型

(这里第二句可以不用再赋值给 tudui,直接 tudui.to(device) 也可以)
3.损失函数

4.输入输出数据(必须要赋值)
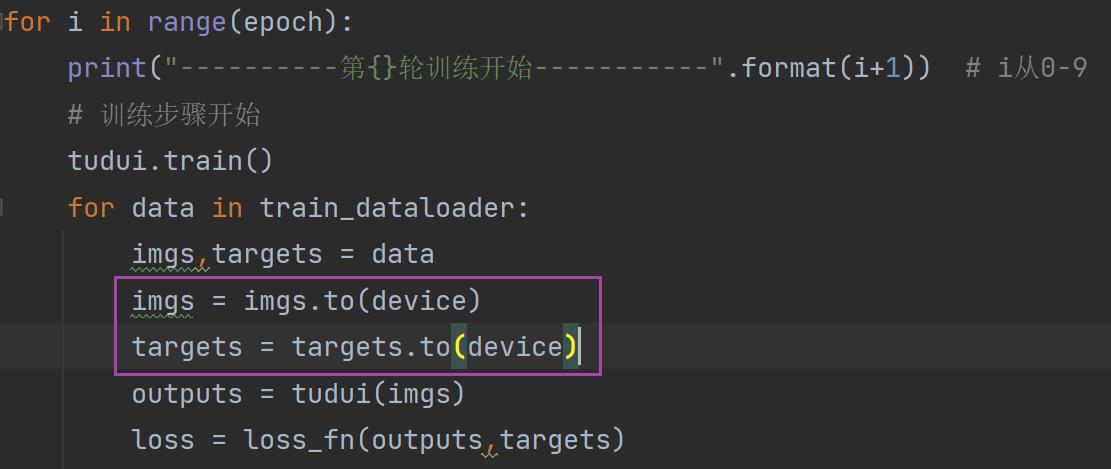

网络模型、损失函数都不需要另外赋值,直接 .to(device) 就可以
但是数据(图片、标注)需要另外转移之后再重新赋值给变量
语法糖(一种语法的简写),程序在 CPU 或 GPU/cuda 环境下都能运行:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")(六)完整的模型验证(测试、demo)套路
核心:利用已经训练好的模型,给它提供输入进行测试(类似之前案例中测试集的测试部分)

1.示例 1
Resize():
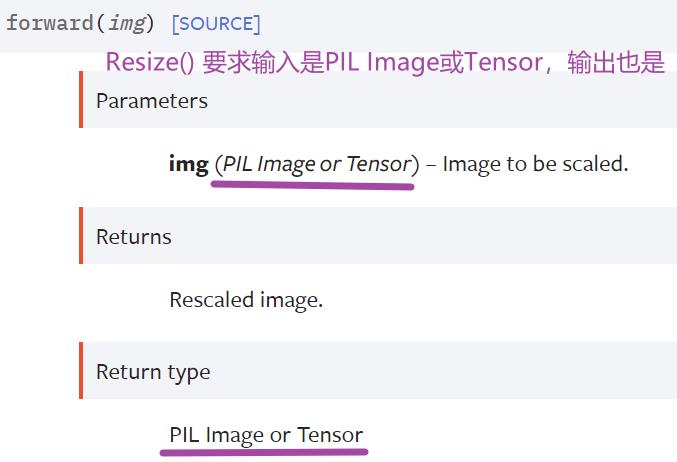
随便在网络上找图片,通过 Resize() 使图片符合模型
# 如何从test.py文件去找到dog文件(相对路径)
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
image_path = "../imgs/dog.png" # 或右键-> Copy Path-> Absolute Path(绝对路径)
# 读取图片(PIL Image),再用ToTensor进行转换
image = Image.open(image_path) # 现在的image是PIL类型
print(image) # <PIL.PngImagePlugin.PngImageFile image mode=RGB size=430x247 at 0x1DF29D33AF0>
# image = image.convert('RGB')
# 因为png格式是四通道,除了RGB三通道外,还有一个透明度通道,所以要调用上述语句保留其颜色通道
# 当然,如果图片本来就是三颜色通道,经过此操作,不变
# 加上这一步后,可以适应 png jpg 各种格式的图片
# 该image大小为430x247,网络模型的输入只能是32x32,进行一个Resize()
# Compose():把transforms几个变换联立在一起
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)), # 32x32大小的PIL Image
torchvision.transforms.ToTensor()]) # 转为Tensor数据类型
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])
# 加载网络模型(之前采用的是第一种方式保存,故需要采用第一种方式加载)
# 首先搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 然后加载网络模型
model = torch.load("tudui_0.pth") # 因为test.py和tudui_0.pth在同一个层级下,所以地址可以直接写
print(model)
output = model(image)
print(output)运行会报错,报错提示如下:
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [32, 3, 5, 5], but got 3-dimensional input of size [3, 32, 32] instead
原因:要求是四维的输入 [batch_size,channel,length,width],但是获得的图片是三维的 —— 图片没有指定 batch_size(网络训练过程中是需要 batch_size 的,而图片输入是三维的,需要reshape() 一下)
解决:torch.reshape() 方法
在上述代码后面加上:
image = torch.reshape(image,(1,3,32,32))
model.eval() # 模型转化为测试类型
with torch.no_grad(): # 节约内存和性能
output = model(image)
print(output)运行结果:

1.3220 概率最大,预测的是第六类
print(output.argmax(1))CIFAR10 对应的真实类别:

怎么找到?
第六类对应的是 frog(青蛙)
预测错误的原因可能是训练次数不够多,在 Google Colab 里,将训练轮数 epoch 改为 30 次,完整代码(train.py):
import torch
import torchvision.datasets
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch import nn
from torch.utils.data import DataLoader
import time # time这个package是用来计时的
# 准备数据集,CIFAR10 数据集是PIL Image,要转换为tensor数据类型
device = torch.device("cuda")
print(device)
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 看一下训练数据集和测试数据集都有多少张(如何获得数据集的长度)
train_data_size = len(train_data) # length 长度
test_data_size = len(test_data)
# 如果train_data_size=10,那么打印出的字符串为:训练数据集的长度为:10
print("训练数据集的长度为:".format(train_data_size)) # 字符串格式化,把format中的变量替换
print("测试数据集的长度为:".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 搭建神经网络(10分类网络)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 把网络放到序列中
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2), #输入是32x32的,输出还是32x32的(padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2), #输入输出都是16x16的(同理padding经计算为2)
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), # 展平
nn.Linear(in_features=64*4*4,out_features=64),
nn.Linear(in_features=64,out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
# 创建网络模型
tudui = Tudui()
tudui.to(device)
# 创建损失函数
loss_fn = nn.CrossEntropyLoss() # 分类问题可以用交叉熵
loss_fn.to(device)
# 定义优化器
learning_rate = 0.01 # 另一写法:1e-2,即1x 10^(-2)=0.01
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) # SGD 随机梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 30 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time() # 记PyTorch 安装过程总结(2022-03-06)
安装过程参考视频:
【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】-哔哩哔哩】 https://b23.tv/ydiIiX2
准备工作(非必要):更新驱动。
官方驱动 | NVIDIA下载适用于 GeForce、TITAN、NVIDIA RTX、数据中心、GRID 等 NVIDIA 产品的新驱动。 https://www.nvidia.cn/Download/index.aspx?lang=cn#备注:更新驱动不是必须的,也可以直接进行下面的步骤。不过为了避免不必要的麻烦,非常建议更新显卡驱动。
https://www.nvidia.cn/Download/index.aspx?lang=cn#备注:更新驱动不是必须的,也可以直接进行下面的步骤。不过为了避免不必要的麻烦,非常建议更新显卡驱动。
一、下载anaconda。
(1)anaconda历史版本网址如下,我选择的是Anaconda3-5.2.0-Windows-x86_64.exe(2018.5.30号的版本)
https://repo.anaconda.com/
下载后安装即可,可以都选择默认,安装过程中记住安装路径。
(2)检验是否安装成功:打开Anaconda Prompt,在窗口中如果可以看到(base)则意味着安装成功。

二、检查显卡驱动。
(1)在任务管理器—性能 下拉就可以看到GPU,如果GPU可以正常显示型号则意味着显卡的驱动已经正常安装了。
三、使用conda指令创建pytorch环境。
(1)打开Anaconda Prompt,输入如下指令。
conda create -n pytorch python=3.6

(2)然后按 y,继续安装所需的各种依赖包。
四、安装pytorch。
(2)网页下拉,找到下图这个界面,官网会自动根据你的电脑,显示的即是你可安装的CUDA版本,并给出安装命令,复制这条安装命令。

(3)打开 Anaconda prompt 命令窗口,输入命令:conda activate pytorch,进入刚刚所创建的环境

(4)将第(2)步复制的安装命令输入即可下载。
conda install pytorch torchvision -c pytorch
注意:每个人的命令,会由于电脑配置而各不同。
五、检验pytorch安装是否成功。

至此,安装完成!但是在安装过程中很有可能碰到各种各样的问题,下面是我所遇到的问题及解决办法。
1、安装Anaconda过程中提示error opening file for writing,如下图:
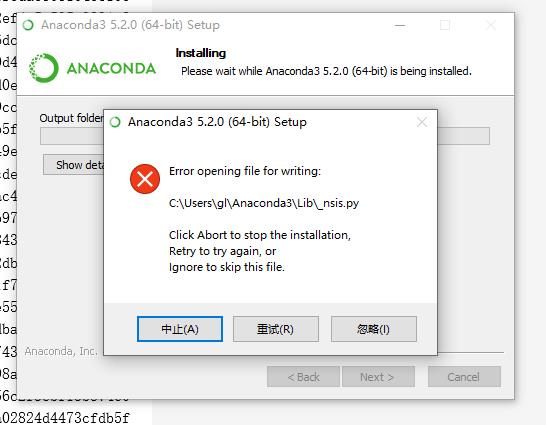
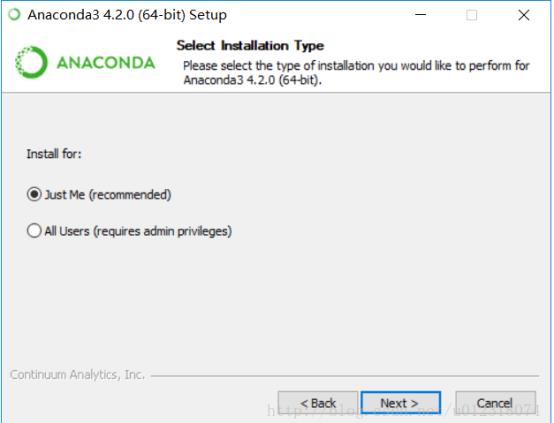
解决办法:安装anaconda出现上述错误可能由于环境变量的问题,安装选择all users 不要选择默认推荐那个。(不选择 Just Me)
2、装好anaconda后在anaconda prompt中输入命令conda create -n pytorch python=3.6,报错Solving environment: failed。
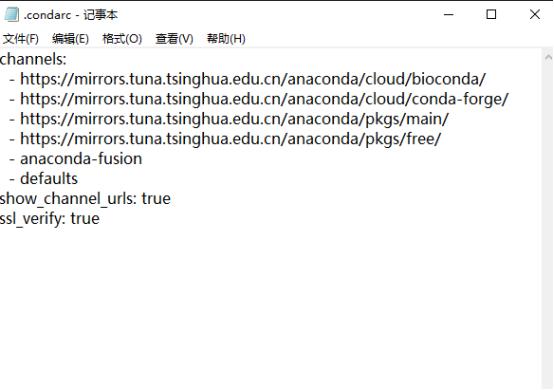
解决办法:修改.condarc文件,将https改为http,删除-defaults。
.condarc文件所在位置为:在cmd中输入%HOMEPATH%目录打开,编辑其中的 .condarc 文件(记事本打开即可)。
修改前:
修改后:

以上是关于我是土堆 - Pytorch教程 知识点 学习总结笔记的主要内容,如果未能解决你的问题,请参考以下文章
pytorch土堆pytorch教程学习Transforms 的使用
 https://pytorch.org/
https://pytorch.org/